
引言
已在数据通信、电信、无线通信、消费类产品、医疗、工业和军事等各应用领域当中占据重要地位。推出采用90nm工艺的大容量StraTIxII系列具有创新的自适应体系,即自适应逻辑模块(ALM),使其在单个器件中具有双倍多的逻辑容量(多达71760个ALM),比第一代StraTIx器件速度快50%,效率提高25%。公司提供的QuartusII软件开发工具能够方便地完成设计输入、仿真,同时还为用户提供了丰富的宏库、LPM(参数化模块库)和IP核,方便了软件设计。正是由于StraTIxII系列FPGA以上的诸多优点,才使得我们能够实现三种信号处理器的单芯片集成设计,不但提高了系统集成度,减小了体积和成本,同时设计的灵活性、可靠性和实用性也大为加强。
1、设计实现
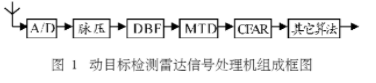
图1所示的是动目标检测雷达信号处理机的主要组成部分,虚线中的处理模块是本系统要完成的工作。其中,阵列由16个阵元组成,脉冲重复周期为1000Hz,每个脉冲回波采样1024次,故而形成1M的数据率,脉冲积累数为128个。阵元信号AD采样后送入脉冲压缩处理器进行匹配滤波,把宽脉冲变成窄脉冲,然后经过DBF将16路信号合成6个波束通道信号,接收某些特定方向的信号,再经由MTD和进行动目标检测和恒虚警判别后,把目标的距离和速度信息送给后续的算法处理,最后将结果送出给雷达显示系统。本系统的硬件由单片FPGA加外部三组和一片组成,其中,高性能的FPGA保证了硬件系统的简洁,由于DBF和MTD处理后的矩阵形式的数据都不能直接送入下一级处理,必须经由外部进行过程存储,通过读写地址的变换送入一级。中保存一些慢速变化的数据,在本系统中,它保存了一张16位的对数查找表。
波束形成器的原理和实现
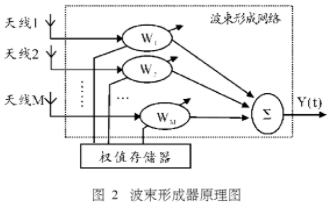
常见波束形成器的原理如图2,采用数字方法对阵列的阵元接收信号加权处理形成波束,阵列天线阵元的方向图是全方向的,阵列的输出经过加权求和后,将阵列接收方向增益聚集在一个方向上,相当于形成了一个波束,只要信号处理的速度足够快,就可以产生不同指向的波束。本系统要形成六个波束,用x[r,t](1≤r≤16,t≥1)表示第r个阵元的时间轴上第t个复信号,用y[s,t](1≤s≤6,t≥1)表示第s个波束的时间轴上第t个复信号,权值用w(6316的矩阵)表示,它们的关系如式(1)所示。
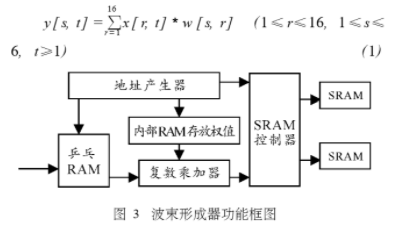
波束形成器的功能实现框图如图3,经过脉压处理的速率16M的复信号送入能存储16×2个数据的乒乓RAM中,两部分轮换读写,同一时刻的16个阵元的复信号依次进入乒乓RAM的一部分;权值存放在内部RAM中,由公式1可以看出,共需16×6个复权值,这六组权值和同一时刻的16个阵元信号送入乘加器中,依次进行乘加运算,显然同一时刻的16个阵元信号需要重复送入6次,乘加器以16次乘加计算为一个周期,锁存输出一个结果,同时清空内部寄存;最后形成一个6M数据率的波束信号通过控制器轮换写入外部的两组SRAM中,为保证系统的实时性,每组SRAM都有单独的地址、数据和控制总线与FPGA相联,以乒乓形式进行读写操作,考虑到后续MTD处理器的工作需要,第组SRAM需要积累128个脉冲周期的信号数据。地址产生器根据需要产生各个模块的地址信号。
由以上分析看出,波束形成器的核心部分复数乘法器仅占用了一个内部的DSP功能块,配置成4个16×16的乘法器,资源占用很低,另一方面根据实时处理需要乘法器仅需工作在96M频率上,远低于其工作极限(370M以上),足以保证其工作的稳定性和可靠性。
动目标检测器的原理和实现
作为雷达数字信号处理核心部分的动目标检测器的基本原理是应用了电磁波的多谱勒效应,和雷达之间有相对运动(速度v)的目标所反射的雷达回波信号在雷达接收端会产生大小为2v/λ的频率偏移,称为多谱勒频率。MTD就是采用匹配的方法在复杂的雷达回波中检测出目标的多谱勒频率,并以此来确定动目标的距离、速度和方位。其中匹配是一组不同中心频率的(FIR形式或FFT形式),FFT方法虽然运算量小,但由于运算点数较少而使此优点不十分明显,且其灵活性差,止带衰减小,对杂波抑制能力差,常不能满足要求,而FIR形式具有灵活性高、运算控制简单、可根据杂波设计达到自适应和杂波抑制能力强等优点,得到广泛应用。经常采用的FIR形式的滤波是一种适用于Kalmus处理的全共轭对称形式的运算,在这种算法中,若滤波器组共有N个滤波器,则第k个滤波器(k≤N2-1)的权系数与第N-k-1个滤波器的权系数共轭对称。这样,由式(2)可以看出权系数的存储量减少了一半,实际乘法的计算量也减少了一半。
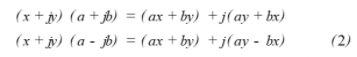
本系统要对六个波束分别进行MTD运算,每个滤波器组有128个滤波器,由于前端脉冲积累数为128个,故每组滤波器有128个权值与其相对应进行乘加运算。用y[s,t](1≤s≤6)表示第s个波束的第t个复信号,用z[s,u,N](1≤s≤6)表示第s个波束第u通道第n个输出值,权值用w表示,它们的关系如式(3)所示。
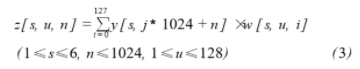
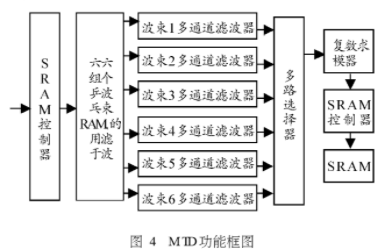
六波束动目标检测器的功能实现框图如图3,存在外部SRAM中的数据以12M速度读取存入六组乒乓RAM中,每组可以存放128×2个复数,用于存放单个波束128次脉冲积累中相同距离门的128个数据,设每组分为上下两部分,存入顺序如下:1组上,2组上,3组上,4组上,5组上,6组上,1组下,2组下,3组下,4组下,5组下,6组下,1组上,。.。
这样六个波束的多通道滤波器可以并行处理,区别仅是启动时间和结束时间不同。每个多通道滤波器由一个复数乘加器和一块用于存放权值的内部RAM构成,由于前面讨论过的共轭对称性,内部权值共需存储64×128个,这些权值依次与内部乒乓RAM中准备就绪的128个复数在乘加器中进行乘法和加减法运算,每组内部RAM中的128个复数需要重复读取64次,乘加器以128次乘加计算为一个周期,锁存输出对称通道的两个结果,同时清空内部寄存;每个波束的多通道滤波器输出速度均为2M,通过多路选择器分时送入求模器,最后经SRAM控制器以12M的速度写入外部SRAM。求模算法可用近似公式(4)求出:
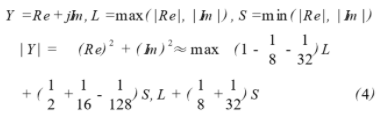
这一近似算法的最大误差为1.379%,在软件设计上主要用到了比较器、移位器和加减法器。
恒虚警检测器的原理和实现
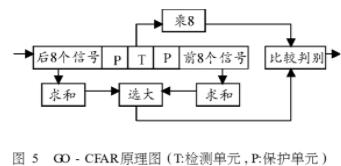
(constant)处理技术,用于在杂波环境变化时,防止雷达的虚警概率发生太大的变化,同时保证一定的检测概率,是一种对杂波问题很在效的处理技术,可以随本地噪声能量信息设置门限。处理方法可分为时间法和空间法两大类,第一类方法采用了热噪声估值门限和时间估值门限来控制虚警概率,在非杂波区,用热噪声估值来构成门限估值器,因此消除了CFAR损失。第二类方法包括平面平均相减组合式CFAR及各种距离平均CFAR处理器,如单元平均,选小单元平均,选大单元平均等,它们的共同特点是利用邻近检测单元的某些参考单元的采样值对检测单元内的杂波强度进行估计,并据此形成检测门限,适用于空域比较平稳、时域变化比较剧烈的杂波环境。在这里我们选用了选大单元平均(GO-CFAR)恒虚警方法,原理如图5所示。
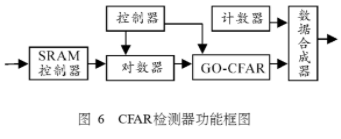
恒虚警检测器的功能实现框图如图6所示。SRAM控制器将存在外部SRAM中的数据按波束号、滤波器号、距离号顺序依次经过对数处理后送入GO-CFAR进行检测,对每个波束、每个滤波器的1024个距离点上判别目标的有无(0或1),由图4所示可以看出,GO-CFAR检测模块对大量的相邻数据进行了寄存,因而需要用控制器在每个滤波器1024个信号检测完成后进行即时清空,以利于下一个滤波器数据的进入,控制器还要负责GO-CFAR检测模块运行、停止和数据进入的控制。在数据检测的同时,计数器根据检测模块系统时钟运行情况进行三种计数,这三个计数器的计数情况对应当前检测单元的波束号(0-5)、滤波器号(0-127)、距离号(0-1023),当检测模块判断出有目标(输出逻辑1)时,三个计数器的计数值被数据合成器锁存并输出。最后合成的数据为32位,其中高8位以无符号数形式表示波束信息(范围0~5),中8位以无符号数形式表示滤波器信息(范围0~127);低16位以无符号数形式表示距离信息(范围0~1023)。这样处理的数据输出结果对后续算法的操作实施非常有利。
系统性能分析和改进
纵观整个系统,其硬件结构较为简单。由于FP2GA的IO资源丰富,外部SRAM总共有三套32位数据总线与其相联,使得FPGA读写外部存储器的速度需求都在20M以内,因而十分便于硬件实施,避免了很多高速信号处理板设计时要充分考虑的电磁兼容性和抗干扰问题。需要实时高速信号处理的部分都在FP2GA内部完成,这些优点都是由以下几个方面对其资源的充分利用所保证的,首先整个设计需要的各种不同的时钟信号,比较典型的有16M,12M,96M,128M,2M,6M等,对FPGA内部PLL的充分利用使我们能毫不费力的产生如此多不同频率和数目的高稳定、低时延的内部时钟信号,同时外部时钟源的数目可能只有一两个。其次,作为运算核心的复数乘法器需要灵活高速的输入数据缓冲,对FPGA内部嵌入式RAM块的使用使这一点得到了有力的保证,在系统中,它们被大量的配置成不同容量的乒乓RAM,这些乒乓RAM都具有不同的读写时钟,使得慢速写高速读的操作可以高效完成,例如在MTD滤波器中配置的乒乓RAM写入为12M,读出为128M;同时,另一些内部嵌入式RAM块被配置成为存储固定权值用的高速大容量RAM,因为这些数据最高读取速度为128M,若放在FPGA片外则硬件实施的复杂性大为加强。这些数值固定的权值也不需要额外的存储,它们在软件操作时以RAM初值表的形式输入,通过下载与FPGA程序一同存储在配置芯片中,上电配置时自动下载到相应的硬件单元。
最后,系统的高度集成不仅缘于内部大量的自适应逻辑模块使其比上一代产品在逻辑容量上成倍增加,而且有赖于大量硬件DSP功能块的使用,这些功能块能方便地实现乘法器而不占用逻辑资源。传统上用逻辑单元搭建一个32×32的复数乘法器需要近一千个逻辑单元,照此计算本系统共使用了7个复乘器,用DSP功能块实现节省了七千个左右的逻辑单元,同时在计算速度上也大为提高。
虽然FPGA内部嵌入式硬件资源减化了部分软件工作,但由于三种处理器的集成,带来了大量的接口操作和数据同步的工作,因此,软件工作仍是本系统设计过程的难点,具体表现在两方面,首先,内外存储器地址操作复杂。三个处理器对一批128个脉冲积累数据操作的顺序和方式不一样,需要外部SRAM进行暂存,因而在读和写过程中要变化地址操作以实现数据传递顺序的改变,地址操作带来了较大的工作量;另外内部乒乓RAM的读写时钟相差大,读写地址也要精心处理。其次,控制时序复杂。动目标检测器和恒虚警检测器的工作只用了一半的数据积累时间,因此需要频繁的启动和停止,同时恒虚警检测器内的GO-CFAR检测模块也需要频繁的启动和停止,对控制时序的要求很高,形成大量的软件工作。
本系统还存在以下两方面可以改进的方向以适应更大数据量和更高实时处理速度要求的情况,一是将外部存储器由SRAM换成,这将带来存储容量上的突破,适用脉冲积累数提高和DBF合成波束数目增多的情况。二是将对数表由外部的移至FPGA内部,从而把对数操作的速度由原来的限制在十多兆提高到上百兆,这样以来对数操作将不再是系统的速度瓶颈,适用于更高速实时处理要求时的情况。
结论
在使用阵列接收天线的动目标检测雷达系统中,数字波束形成器、动目标检测器和恒虚警检测器常常同时出现并依次对接收信号进行处理,本文基于高性能FPGA(的StraTIxII系列)介绍了一种三者结合的单芯片集成设计方案,这一系统集成度高,体积小,而且设计的灵活性、可靠性和实用性较以往大为加强,同时它也能很方便的移植到其它雷达设计中,只需稍作改进就能适用于更高性能的算法实现。本方案已经应用到某型号地面监视雷达项目中,收到良好效果。
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂