

简介
ESPSR 全程 ESP- Speech- recognization. 是乐鑫推出的语音识别的框架, 为用户提供AI语音的解决方案. 目前支持的ESP系列有ESP32, ESP32S3 和 ESP32P4. 截止到目前为止它一共支持四个模块
1- 声学前端算法 AFE
2-唤醒词检测 WakeNet
3-命令词识别 MultiNet
4-语音合成(目前只支持中文)
其AFE声学前端算法主要处理的任务是对原始音频进行处理达到降噪等一系列的目的, 它主要包括以下模块

一次完成的语音识别的流程如下所示
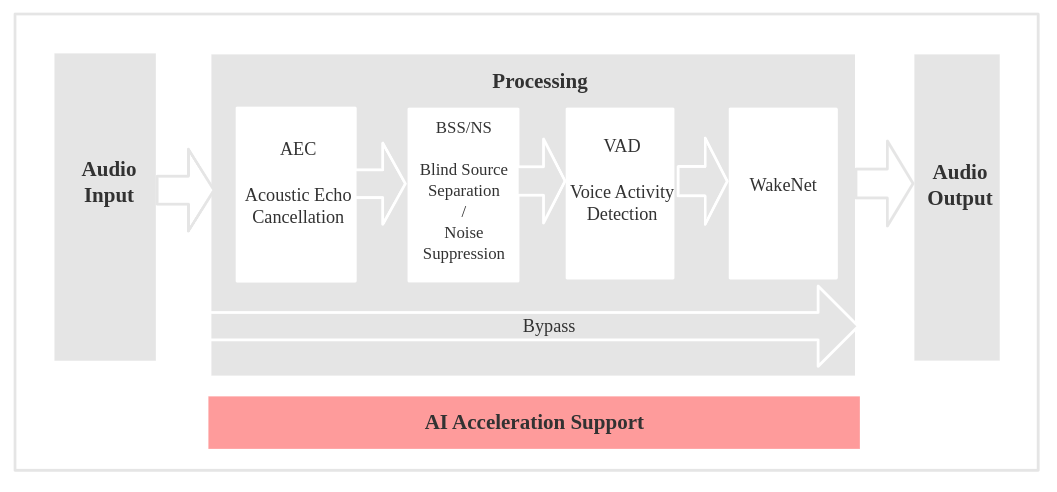
首先音频数据输入, 进入到AEC模块, AEC模块对音频进行回声消除. 之后处理后的数据进入到NS和BSS模块, NS对环境噪声进行抑制从而得到被处理过后的音频数据. 同时BSS盲信号分离算法对音频数据和干扰杂音进行分离. 之后处理过的数据则进入到语音活动监测算法. 从而检测当前的语音活动状态. 最后进入WakeNe进行唤醒词匹配. 然后输出音频数据.
其中ESP-SR支持多通道音频数据输入(即使用多个麦克风输入), 只需要在初始化input_format 的时候指定对应的通道即可, 如下所示.

Esp-skainet 简介
esp-skainet 是乐鑫的一个仓库, 其中esp-sr作为组件被编译到了这个项目中, 其中具有一些examples可以供我们来学习使用.

首先将仓库clone到本地
git clone https://github.com/espressif/esp-skainet.git
然后使用vscode 打开项目
cd esp-skainet code .

可以从上图中看到, 它包含了很多例子, 比如说文字转换语音、中英文语音识别、音频通话测试demo 和 唤醒词检测. 我们在这里主要关注的是 唤醒词检测. 使用vscode 打开这个工程.
首先设置为正确的开发板

然后我们便可以在 menuconfig 中配置对应的 ESP-SR配置

上图中最上方配置的是模型的路径, 它可以选择从内存卡中加载模型或者是直接从文件系统中加载. 然后就是其他的一些音频处理的模型和音频活动的检测, 保持默认即可. 下方的数据为乐鑫已经训练好的唤醒词. 当我们勾选保存这些唤醒词的时候. 编译之后的固件便可以支持对应的唤醒词检测.

代码部分主要是分为了两个Task, 第一个task持续从mic里读取数据(i2S), 然后把数据喂给模型. 第二个task则是处理模型的响应结果. 并且两个任务分配到了不同的核心上不会造成任务的干扰. 我使用AI工具把程序都加了注释
1- 首先初始化I2S 和 音频前端数据处理
/**
* @brief 应用程序的主函数,负责初始化硬件和软件资源,并创建用于音频处理和唤醒词检测的任务。
*
* 该函数的主要步骤包括:
* 1. 初始化开发板;
* 2. 加载唤醒词模型;
* 3. 配置音频前端(AFE);
* 4. 打印配置中的唤醒词模型信息;
* 5. 创建音频数据馈送任务和唤醒词检测任务。
*/
void app_main()
{
// 初始化开发板,设置采样率、输入通道数和输出通道数。
ESP_ERROR_CHECK(esp_board_init(16000, 1, 16));
// 初始化SD卡(如果需要)。
// ESP_ERROR_CHECK(esp_sdcard_init("/sdcard", 10));
// 初始化唤醒词模型列表。
srmodel_list_t *models = esp_srmodel_init("model");
if (models)
{
// 遍历模型列表,查找并打印存储在闪存中的唤醒词模型。
for (int i = 0; i < models->num; i++)
{
if (strstr(models->model_name[i], ESP_WN_PREFIX) != NULL)
{
printf("wakenet model in flash: %s\n", models->model_name[i]);
}
}
}
// 初始化音频前端配置。
afe_config_t *afe_config = afe_config_init("MMNN", models, AFE_TYPE_SR, AFE_MODE_LOW_COST);
// 打印音频前端配置中的唤醒词模型名称。
if (afe_config->wakenet_model_name)
{
printf("wakeword model in AFE config: %s\n", afe_config->wakenet_model_name);
}
if (afe_config->wakenet_model_name_2)
{
printf("wakeword model in AFE config: %s\n", afe_config->wakenet_model_name_2);
}
// 根据配置创建音频前端句柄和数据结构。
afe_handle = esp_afe_handle_from_config(afe_config);
esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(afe_config);
// 释放音频前端配置资源。
afe_config_free(afe_config);
// 设置任务标志位,表示任务可以开始运行。
task_flag = 1;
// 创建音频数据馈送任务,负责从音频前端获取数据并馈送到处理管道中。
xTaskCreatePinnedToCore(&feed_Task, "feed", 8 * 1024, (void *)afe_data, 5, NULL, 0);
// 创建唤醒词检测任务,负责监听和检测唤醒词。
xTaskCreatePinnedToCore(&detect_Task, "detect", 4 * 1024, (void *)afe_data, 5, NULL, 1);
}如果你使用的是你自己的麦克风比如说Inmp441, 只需要在初始化I2S处按照你自己的进行初始化即可, 其余代码并不需要修改.
2- 读取音频Task
/**
* feed_Task函数是音频处理任务的主循环。
* 它负责从音频前端获取音频数据,并将其馈送到音频处理管道中。
*
* @param arg 任务参数,这里是esp_afe_sr_data_t类型的指针,指向音频前端数据结构。
*/
void feed_Task(void *arg)
{
// 将任务参数转换为esp_afe_sr_data_t类型指针
esp_afe_sr_data_t *afe_data = arg;
// 获取音频数据的块大小
int audio_chunksize = afe_handle->get_feed_chunksize(afe_data);
// 获取音频数据的通道数量
int nch = afe_handle->get_feed_channel_num(afe_data);
// 获取系统期望的音频通道数量
int feed_channel = esp_get_feed_channel();
// 确保音频数据的通道数量与系统期望一致
assert(nch == feed_channel);
// 分配缓冲区用于存储音频数据
int16_t *i2s_buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);
// 确保内存分配成功
assert(i2s_buff);
// 当任务标志位设置时,持续执行音频数据的获取和馈送
while (task_flag)
{
// 从音频前端获取音频数据
esp_get_feed_data(false, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);
// 将音频数据馈送到音频处理管道中
afe_handle->feed(afe_data, i2s_buff);
}
// 释放分配的内存并清理指针
if (i2s_buff)
{
free(i2s_buff);
i2s_buff = NULL;
}
// 删除当前任务
vTaskDelete(NULL);
}这个task的主要任务就是从I2S中读取数据,然后把音频数据喂给模型, 如果你使用的是你自己的麦克风只需要修改下面这行代码成i2Sread 即可,然后把数据从缓冲区中喂给模型
esp_get_feed_data(false, i2s_buff, audio_chunksize * sizeof(int16_t) * feed_channel);
3 - 识别task, 该task的主要任务就是识别上述task的音频输入, 判断是否检测到关键字, 如果检测到关键词的话则程序打印输出
/**
* @brief 检测任务函数,用于持续监听和检测唤醒词
*
* 该函数接收一个参数,用于初始化音频前端处理所需的数据结构和参数。
* 它通过分配缓冲区来准备处理音频数据,并在循环中不断尝试获取音频处理结果。
* 如果检测到唤醒词,则打印相关信息并进入监听模式。
*
* @param arg 指向音频前端数据结构的指针,包含音频处理所需的信息
*/
void detect_Task(void *arg)
{
// 将传入的参数转换为esp_afe_sr_data_t类型指针
esp_afe_sr_data_t *afe_data = arg;
// 获取音频数据处理的块大小
int afe_chunksize = afe_handle->get_fetch_chunksize(afe_data);
// 分配用于存储音频数据的缓冲区
int16_t *buff = malloc(afe_chunksize * sizeof(int16_t));
// 确保缓冲区分配成功
assert(buff);
// 打印检测任务开始的信息
printf("------------detect start------------\n");
// 持续运行检测任务,直到任务标志位为假
while (task_flag)
{
// 尝试获取音频处理结果
afe_fetch_result_t *res = afe_handle->fetch(afe_data);
// 如果获取结果失败,打印错误信息并退出循环
if (!res || res->ret_value == ESP_FAIL)
{
printf("fetch error!\n");
break;
}
// 打印当前的语音活动检测(VAD)状态
// printf("vad state: %d\n", res->vad_state);
// 如果检测到唤醒词,打印相关检测信息
if (res->wakeup_state == WAKENET_DETECTED)
{
printf("wakeword detected\n");
printf("model index:%d, word index:%d\n", res->wakenet_model_index, res->wake_word_index);
printf("-----------LISTENING-----------\n");
}
}
// 释放之前分配的缓冲区,并设置指针为NULL
if (buff)
{
free(buff);
buff = NULL;
}
// 删除当前任务
vTaskDelete(NULL);
}我们来将程序进行烧录,并且查看一下监视窗口的识别效果.

可以从上图中看到, 其中支持的唤醒词一共有三个, 分别是Hilexin、nihaoxiaozhi、xiaoaitongxu. 当我对着麦克风说话的时候它已经成功的检测到了关键词并且做出了响应.
总结
最近小智算是火的一踏糊涂, 各个厂商都在向Ai行业靠拢, 也在短视频上刷到了好多类似的AI玩具(类似小智的语音对话). 其中关键词识别唤醒是其中非常重要的一个环节, 这样的话程序才能读取到你的语音数据进行传输和识别. 相信通过这篇文章能带给你一些启发.
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

