
第一次正式研究嵌入式操作系统,所以只能一点一点往前爬。
感谢楼上各位的支持,我赶脚我又原地满状态复活鸟。。。。。。
实验五 互斥体
要整明白互斥体,首先要了解使用互斥体时,可能面对的一个有极大可能会使OS崩溃的问题:优先级反转。
啥是优先级反转?假设A、B、C三个任务,优先级A>B>C,A和C对同一个资源X有需求,如果C在使用X时锁定资源并满足触发A的条件,那么A就会进入运行状态而使C失去解锁的机会。由于A无法锁定X,那么只能进入等待态,并等C解锁X后才能运行。
如果A等待C解锁X的过程中,B所等待的事件也来临,那么毫无疑问,B就要优先于A和C而运行了。这样,ABC三个任务的运行情况就不再受优先级的约束,造成优先级反转的现象,很容易恶化操作系统运行情况。
为了避免这个情况的出现,μTenux中设置了2种机制去规避:优先级置顶和优先级继承。
所谓优先级置顶,就是将锁定互斥体的任务的优先级暂时提升至互斥体所设定的优先级。
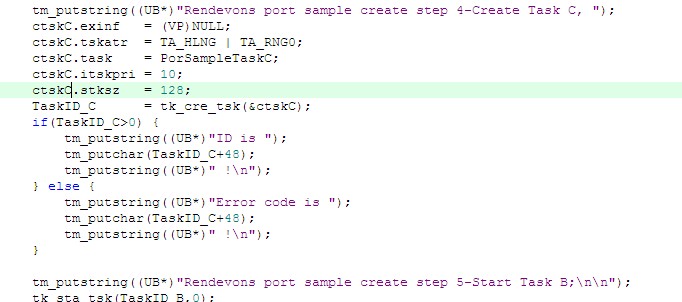
实验源代码就是使用这种机制,代码中cmtx.mtxatr = TA_TFIFO|TA_CEILING;cmtx.ceilpri = 15;置顶优先级设置的是15,而任务A和B的优先级则都是20.
编译,下载,看打印信息。

从打印信息不难看出来,任何锁定互斥体Mutex的任务的优先级均被提升至互斥体定义的优先级15.
以保证锁定互斥体的任务能够顺利解锁,并释放给其他任务使用。
另外一种机制就是优先级继承,与优先级置顶不同,这种机制直接将锁定互斥体的任务的优先级提升至某个值,这个值由正在等待锁定这个互斥体的任务的最高优先级来决定。
修改实验源代码,cmtx.mtxatr = TA_TFIFO|TA_INHERIT;cmtx.ceilpri = 15;置顶优先级设置的是15,而任务A、B的优先级则分别是16、20,并使B在锁定互斥体后再调用任务A。
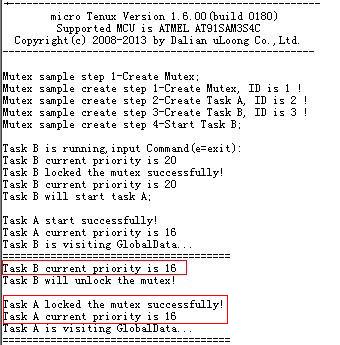
编译下载,从打印信息可以看出来,虽然设定互斥体的ceilpri为15,但是实际上锁定互斥体的任务的优先级在锁定后,都被提升为16,也就是等待锁定互斥体的任务的最高优先级,即A的优先级16.
实验五思考题
1) 本实验中演示了两个同优先级任务使用互斥体进行交替的方式,如果不使用互斥体的优先级置顶属性,或不使用互斥体的优先级继承属性,结果如何?
简单分析一下,如果不使用TA_INHERIT或TA_CEILING属性来构建互斥体,仅仅是使用TA_TPRI或TA_TFIFO来构建互斥体,很可能会出现优先级高的任务(不同优先级情况下)或先运行的任务(相同优先级)一直在操作互斥体。
立马实验,修改互斥体mtxatr的属性。发现无论A、B的优先级如何设定、mtxatr的属性只要不是TA_INHERIT或TA_CEILING,永远都只会有一个任务在操作互斥体,不会修改优先级,也不会交替执行。

如果要验证优先级反转,假设优先级由高到低的三个任务A、B、C,A和C操作互斥体,而B不对互斥体进行操作。
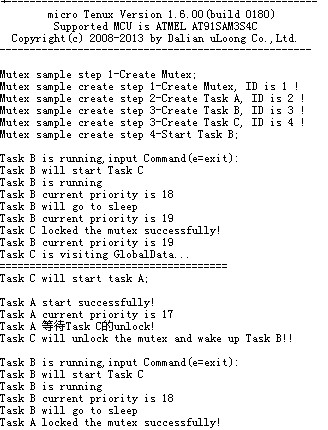
观察串口打印信息可以发现,A在等待TaskC解锁的时期,B能够优先于A执行,优先级反转鸟。
2)本实验中演示了两个同优先级任务使用事件标志进行交替的方式,如果把一个任务的优先级提高,
结果如何?什么情况下,会使用到这种方式?
简要分析一下,如果优先级不同,那么优先级高的任务会一直操作互斥体。
修改,编译,下载,run......
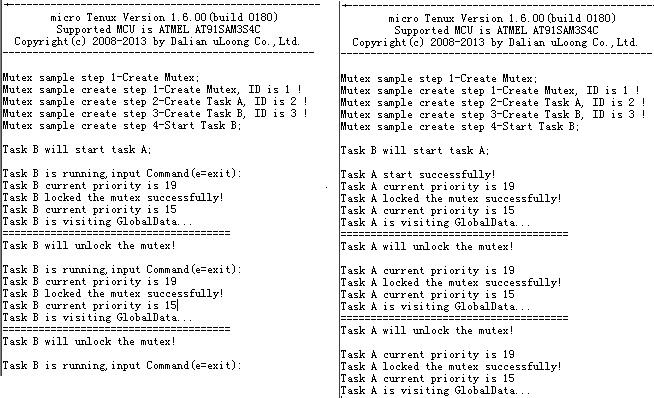
任务优先级还是按照优先级置顶的机制变化了,但是仅有较高优先级的任务在操作互斥体。
如果为较高优先级的任务设置合适的事件标志,可以保证较高优先级任务的资源独享,而不被其他任务破坏。
TBC......
实验六 消息缓存区
看了看内核规范里的消息缓存区,赶脚和邮箱消息蛮相似的,不过没看到有消息类优先级的设置,只有发送消息任务队列有优先级。第一感觉,应该是个经典的FIFO。
读实验源代码的时候,发现有个函数strlen( )找不到定义。
貌似是用来获取发送字符串的长度的函数,然后将长度参数传递给tk_snd_mbf()函数用来发送消息。
后来才知道,这个函数是Gcc库中的。
实验结果:

串口信息显示,A和B不断在通过消息缓存区进行通信。
如果消息邮箱有一定的了解,这个也不在话下。
1) 当一个缓冲区中有多个消息时,取出一条消息,那么这条消息是最先进入缓冲区的消息还是最后进入缓冲区的消息?
简单分析一下,在内核规范里头未见有消息类的优先级设置,估计应该是一个FIFO。
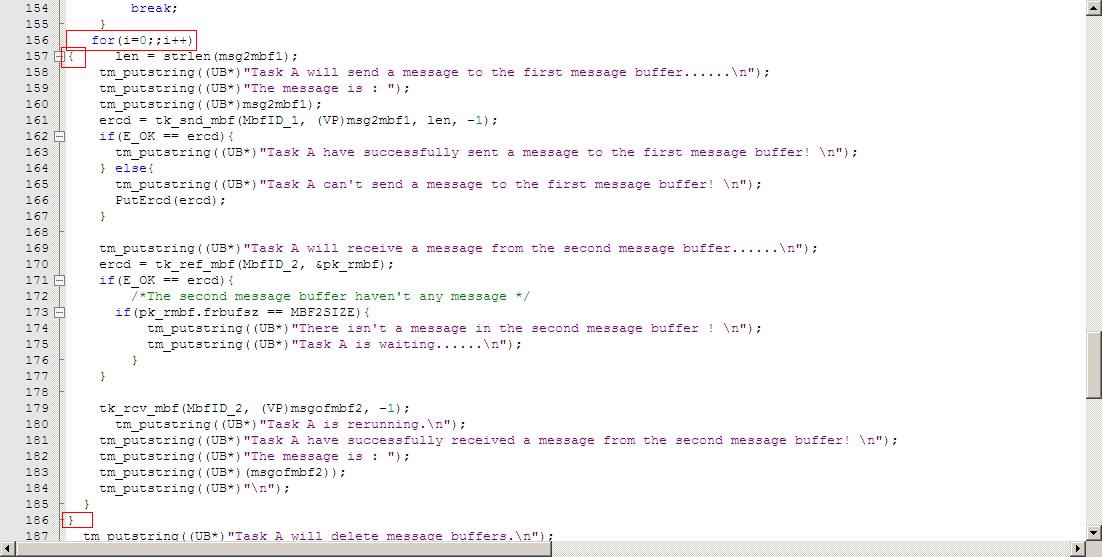
修改代码,使TaskA连续发送字符串 “Do you think that uTenux is the best RTOS?????????”和“ Good Day????????? ”,然后使TaskB从消息缓存区接收2次消息。

从串口打印信息可以很清楚的看到,A先发送的消息,B会先收到。
2) 某任务向一个消息缓冲区连续不断发送消息,消息缓冲区满之后会出现什么状况?
内核规范中提到,如果没有足够的缓冲区空间可容纳消息队列中的消息 msg,则发行该系统调用的任务进入发送等待状态, 排队等候可用的缓冲区空间 (发送队列)。也意思是说,A不断地发送消息直至消息缓冲区满,那么A就会进入等待状态,这个时候B就开始运行。
修改代码,使A不断发送消息,并不接收消息。可以预见,A进入等待状态后,B会收取一个消息并向第二个缓存区发送消息,那么很快,第二个缓存区也会满,B最后也会进入等待状态。
μTenux所有任务都等待状态的话,会退出。
有图有真相:

看上去,分析得还不算太错。
如果修改代码,使A不断发送消息,并不断接收消息呢?
是不是应该A和B不断进行发送和接收呢?

那必须滴。
TBC......
实验七集合点端口
个人觉得集合点相对于前面几个实验是比较难理解一些。
仔细查看内核规范,这里重点是四个函数tk_cre_por( )、tk_acp_por( )、tk_cal_por( )和tk_rpl_rdv( )。
基本任务流程是:
首先,用tk_cre_por( )函数创建一个集合点端口,这里要特别注意,仅仅是创建而已,并没有使用。就好像任务一样,创建任务和运行任务是不同的。
然后,是tk_acp_por( )和tk_cal_por( ),你可以以先acp再由cal应答(等待集合点接受)的方式来唤醒集合点,或者以先cal再acp应答(等待集合点调用)的方式唤醒,我个人理解这两个函数得成对使用才行。任务之间通信和同步如果用集合点端口来完成的话,那么不同任务必须使用相同的位模式参数(相与不为0),才能使tk_acp_por( )和tk_cal_por( )匹配,唤醒集合点端口。
最后,等待的任务调用tk_rpl_rdv( )完成应答,并结束集合点(类似挂起),等待下一次集合点唤醒。特别注意,这个tk_rpl_rdv( )函数只能在执行完 tk_acp_por 以后执行。
这里面有个集合点ID和集合点编号的区别,ID其实是创建集合点时OS赋予的,而编号则是由OS在等待集合点调用或接受的时候,由OS分配。在多个集合点的系统里面,编号是非常重要的。
了解了这些东西,再去看实验源代码就一目了然了。
直接上结果:

很顺利,B执行tk_cal_por( )等待调用,A执行tk_acp_por( )接受集合点,然后A执行tk_rpl_rdv( )进行回复并结束集合点,典型的等待集合点调用模式。
1) 本实验中演示了两个同优先级任务使用集合点端口进行通信的方式,如果增加一个任务,也参与通信,结果如何?
分析一下,如果增加一个任务C,会不会出现任务A和任务C这2个任务轮流与任务B通过集合点端口进行同步和通信呢?
果断增加同优先级的TaskC,同时B任务的i变成18(和2个任务通信,一个任务9次)。
出来的结果和预想的有点小差距,为毛A要与B通信2次后,C和A才交替与B进行通信呢?
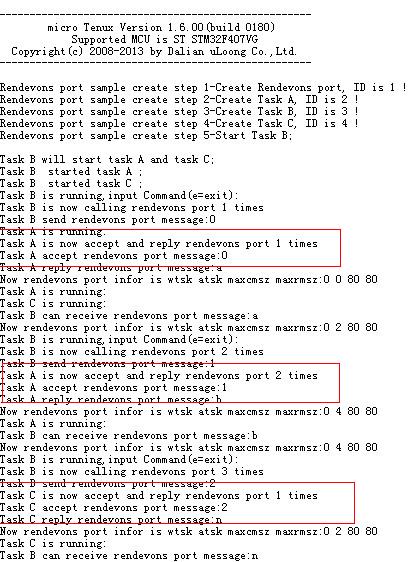
其实这个和ABC优先级、OS的任务调度有关。
ABC三个任务优先级一样,B首先运行并按次序启动A和C,这个时候,B在运行态,A和C在就绪态。根据μTenux系统调用的原则,B等待后,先会执行A,再执行C。
B调用tk_cal_por而进入等待集合点调用的等待状态,此时A开始运行并执行tk_acp_por启用集合点(此时集合点应答等待队列中无任务),然后执行tk_rpl_rdv在集合点中返回一个回应给调用任务B,终止集合点。tk_rpl_rdv并不会引起A进入等待状态,A继续从循环开始执行,并执行tk_acp_por引起A进入等待集合点接受的等待状态(这个时候集合点等待队列中出现了A),C开始执行,并执行tk_acp_por引起C进入等待集合点接受的等待状态(这个时候集合点等待队列中出现了C)。回头看集合点创建函数,cpor.poratr = TA_TFIFO;,集合点等待队列以FIFO的形式进行排列,A和C进入等待状态后,B首先响应的是A的等待集合点接受,然后才是C的。这也就解释了,为什么A会与B通过集合点进行2次通信后,C和A才开始交替与B通过集合点进行通信。B和A第一次通信是等待集合点调用模式,以后所有的通信都是等待集合点接受的模式。
原来是优先级惹的祸,强力插入修改,将A和C的优先级提高为9.
上图:

串口打印出来的信息表明,从一开始,A和C就在交替与B通过集合点端口进行通信。打完收工。
2) 考虑一下其他还有什么情况下,会使用到集合点端口这种方式?
多个任务要执行同一个处理的时候,这种集合点端口的方式很方便。
譬如一个打印机,有A、B、C等3台电脑有文档需要打印,优先级A>B>C。如果C先开始打印,打印到1/3,B发出请求,再打印1/3,A又发出请求。如果没有集合点端口模式,最终打印出来的文档ABC各有1/3;如果采用集合点端口模式,就会按照优先级或者FIFO的队列形式进行打印。
不知道这种理解是否合适。
TBC......
实验八固定尺寸内存池
实验开始涉及有关内存管理的相关内容了。
不过μTenux不支持虚拟内存,支持常驻内存。意思是说,μTenux所管理的内存对象是物理内存。
关于保护级,μTenux目前只支持所有程序(包括系统和应用程序)内存保护级在0级。
这个实验主要涉及的函数包含tk_cre_mpf()、tk_rel_mpf()、tk_get_mpf()、tk_ref_mpf()和tk_del_mpf()。
实验开始前,首先要整清楚一个概念:内存池和内存块。内存池实际上是调用tk_cre_mpf()后,系统分配的内存区间大小,而内存块则包含在内存池中,或者说一个内存池包含有几个内存块。那么,整个内存池的大小=每个内存块的大小X内存块个数。
实验代码中,申请内存池参数cmpf.mpfcnt = 5; cmpf.blfsz = 100;,那么此次申请的内存池大小为5X100=500字节,由5个100字节的内存块构成。在不调用tk_rel_mpf()函数的情况下,这个内存池可以被tk_get_mpf()申请5次。
代码中还调用了内存块操作函数memcpy(blf, buf, len),意思是将buf起始地址位置的len个字节数据copy到blf起始地址位置里面去。
实验结果:

基本程序流程:创建内存池--B运行--A运行--A休眠--B申请内存块--B写入数据--B唤醒A--A读取内存--A释放内存并休眠--B运行。
固定内存池和互斥体相对,互斥体解锁必须由加锁的任务,而固定内存池可由任何任务进行get或release。
如果A不释放内存池,那么B最多只能申请5次,之后系统就会挂起。
注释掉释放的函数,上图:

嗯,从打印信息来开,意料之中,内存池中的内存块数量被申请完后,A和B进入等待休眠和等待态,系统最终被shutdown。
这里有个疑问,实验代码中len = strlen(buf)+1,为什么要从*buf多copy一个字节的数据到*blf?估计这个问题得回去再深入温习一下C语言了。后来也试了memcpy(blf, buf, len)中len不+1,其实和上面结果一样。
代码的彩蛋?求科普。
1) 尝试修改固定内存池程序,测试申请最大的内存池为多少 KB?
这里尝试了STM32F407VG和sam3S4c两块片子。
STM32F407VG最大申请的内存池为100800B(100.8KB),不过它Up to 192+4 Kbytes of SRAM,还有96KB的物理内存用作什么了,预留?boot?
sam3S4c最大申请的内存池为35264B(35.264KB),它RAM 48KB,还有将近13KB的的物理内存用作什么了,预留?boot?
看来嵌入式操作系统学习的路程才刚刚开始。
TBC......
实验九可变尺寸内存池
可变尺寸内存池(mpl)和固定尺寸内存池(mpf)灰常滴类似。
看了看内核规范,只是个别参数上的区别。
cre的时候,mpl的参数结构体中的mpfcnt和blfsz规定内存块的数量和大小;而mpf的参数结构体中的mplsz规定总的大小。
get的时候,mpf直接减少内存块的数量,大小由cre时候确定;而mpf则通过mplsz参数减少总内存的大小,mplsz即get到的内存块大小。
ref的时候,mpf通过frbcnt获取剩余内存块数量;而mpl则通过maxsz或frsz获取剩余内存池的大小。
窃以为,可变尺寸内存池应该指获取时并不指定具体的大小,而是根据任务使用情况来改变内存池块的大小。
从这个角度来看,μTenux的可变尺寸内存池应该叫做自定义尺寸内存池更为贴切。
实验结果:

实验代码创建的mpl是512B的,为毛128B+376B小于512B,这8个字节去哪里了?
1) 如果内存池内的数据超过内存池块的空间会产生什么样的现象?
其实这个题目看不大明白。是指任务获取的内存块中存储的数据,超过了整个mpl大小吗?
不过还是尝试了一下,条件是任务获得1B的内存块,字符串数据远远超过1B:

从打印信息来看,程序跑飞了。目前还未找到原因。
debug发现,任务B第二次执行MplSamplePutCnt()函数中的ltostr(rmpl.frsz,frsz,10,10)时,程序跑飞。
2) 为什么在申请了 128B 内存块后,剩余的内存块不是 384B,而是 376B 了?
损失了8B的数据空间,个人想法,内存池的控制表、创建内存池时候T_CMPL *pk_cmpl 所包含的内存池相关信息,应该都是会保存在内存池的单元中吧。所以会少几个B的空间,用以保存这些元数据。
不过有个很有意思的现象,申请不同大小的可变地址池,有可能损失的空间不一样。
譬如,在STM32F407VG平台下,申请一个1B的空间,系统会显示剩余488B空间,那么损失了25B空间;申请500B的空间,系统则显示剩余0B空间。
很奇怪。
TBC......
实验十 系统时间管理
驱动过外围芯片的筒子们都知道,芯片的时序是非常重要的,其实指的无非就是高低电平保持的时间和出现的顺序。尤其是各类总线器件,对时序的要求相当严苛。
那么对于一个操作系统而言,时间管理就显得尤为重要了。
μTenux提供的时间管理函数很简单,不过这里要整清楚系统时间和工作时间。
个人理解,系统时间是指上电初始化后,系统保存的时间,如果芯片自带RTC和电池的话,可以通过修改系统初始化,让系统保存真实世界的时间,那么每次调用tk_get_tim函数,将获得真实世界的时间,如果没有RTC或者支持RTC工作的电池,系统时间则为默认的1985年1月1日0点0时0分;而工作时间是指系统上电后,芯片会不断计时,每次调用tk_get_otm函数,将获得系统自上电以来经历的时间。
理清这两个概念,μTenux的基本时间管理就比较简单了。
实验代码调用的是tk_get_otm,那么获取的时间就应该是上电以来系统经历的时间。
上实验结果图

SYSTIM定义了高位和低位,低位保存时分秒,高位保存年月日。
我这里把高低位全部打印输出,实验代码调用tk_get_otm后,SYSTIM全为0,系统从0开始计时。
1) 如果把获取系统工作时间的 tk_get_otm 函数更换为获取系统时间的 tk_get_t im 函数,结果如何 ?
如果直接简单的把tk_get_otm更换为tk_get_tim,其实系统运行的结果和之前的是一样的,没变化。
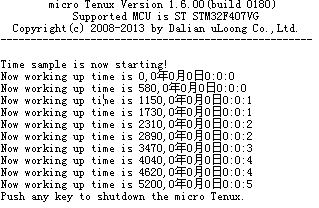
这里有一点点没有想清楚,内核规范上所写“系统时间表示成从 1985 年 1 月 1 日 0:00:00(GMT) 开始以 ms 为单位的累加”,意思是说如果没有设置系统时间,那么默认时间应该是1985 年 1 月 1 日 0:00:00,但是实际试验的结果是从0000年00月00日0点0分0秒开始计时的。
如果我们调用tk_set_tim来设置系统时间,那就可以获得真实世界的时间了。
修改代码:
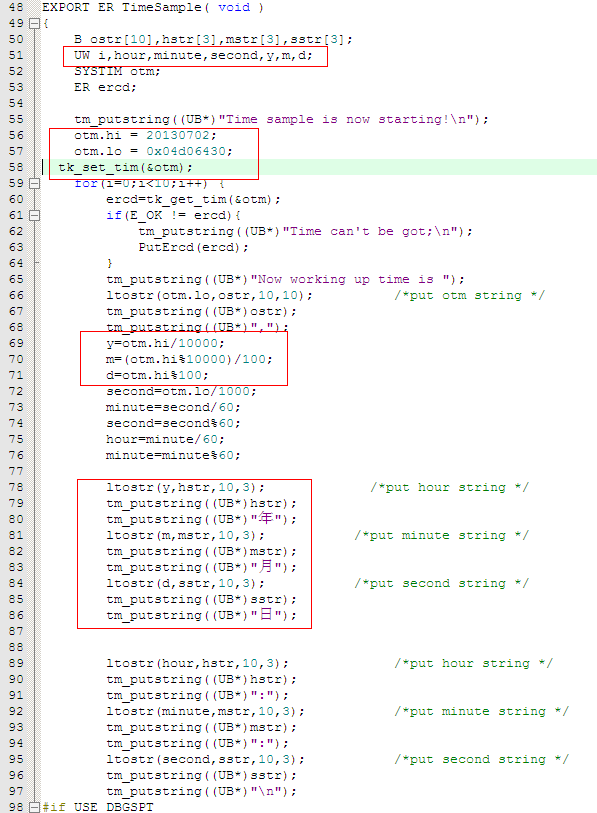
增加y、m、d代表年月日(大侠们不要吐槽变量命名方式)
直接将十进制数20130702赋值给otm.hi,用最粗俗的算法,计算年月日。
时分秒的计算比较坑,我尝试了一下,发现算法是这样:otm.lo=(小时*3600+分钟*60+秒)*1000+毫秒.
如果要从22点26分5秒开始作为系统时间,那么otm.lo=(22*3600+26*60+5)*1000+0=80766000=0x4d06340.
run......
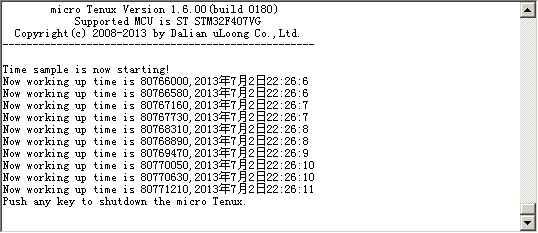
2) 如果开发板带 RTC 电池,使用 tk_get_otm 函数和 tk_get_t im 函数的程序结果有没有不同?
手头上的sam3s4c芯片虽然支持RTC,但开发板没有带RTC电池。如果有的话,在系统初始化时调用相关函数,SYSTIM就能共RTC模块获取数据,应该就能始终保持实时的时间。那么调用tk_get_otm 函数和 tk_get_tim 函数,得到的结果肯定就不一样了。个人认为,tk_get_tim受到系统所保存时间的影响,而tk_get_otm只受系统上电时刻的影响。
为了验证想法,调用tk_set_tim模拟系统有RTC电池,然后同时调用tk_get_otm 函数和 tk_get_tim 函数并打印相关信息。

run..run...run......
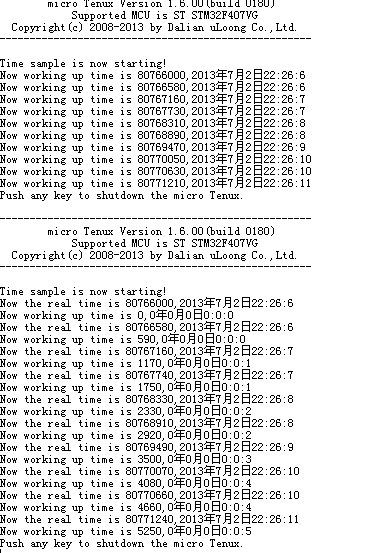
从结果来看,系统运行时间和系统时间的概念就能很容易厘清了。
如果有RTC电池,这两者的结果肯定就不一样咧。
TBC......
 我要赚赏金打赏帖 我要赚赏金打赏帖 |
|
|---|---|
| 【S32K3XX】LPSPI参数配置说明被打赏¥21元 | |
| 在WT9932C61-TINY上实现超声波测距被打赏¥22元 | |
| 基于WT9932C61-TINY的环境构建及OLED屏驱动测试被打赏¥20元 | |
| 【S32K3XX】Core-to-Core 中断使用被打赏¥21元 | |
| 「AI编程记录--含源码」用一晚上的时间写一个esp32的示波器被打赏¥19元 | |
| STM32C0116DK开发探索记(3)被打赏¥30元 | |
| STM32C0116DK开发探索记(2)被打赏¥24元 | |
| STM32C0116DK开发探索记(1)被打赏¥29元 | |
| 谨防极海G32M3101电机评估板易跌落的陷阱被打赏¥24元 | |
| 【全网首拆】M5STACK ATOM系列开发板拆解 / AtomS3R-CAM摄像头更换方法(提高10倍像素)被打赏¥26元 | |
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

