
十七、进程间通信总结
进程间通信主要包括管道, 系统IPC(包括消息队列,信号量,共享存储), SOCKET。
管道包括三种:1、普通管道PIPE, 通常有种限制,一是半双工,只能单向传输;二是只能在父子进程间使用. 2流管道s_pipe去除了第一种限制,可以双向传输。 3命名管道name_pipe, 去除了第二种限制,可以在许多并不相关的进程之间进行通讯。系统IPC的三种方式类同,都是使用了内核里的标识符来识别。
管道的使用方法与文件类似,都能使用read,write,open等普通IO函数. 管道描述符来类似于文件描述符. 事实上, 管道使用的描述符, 文件指针和文件描述符最终都会转化成系统中SOCKET描述符. 都受到系统内核中SOCKET描述符的限制. 本质上LINUX内核源码中管道是通过空文件来实现。管道: 优点是所有的UNIX实现都支持, 并且在最后一个访问管道的进程终止后,管道就被完全删除;缺陷是管道只允许单向传输或者用于父子进程之间。系统IPC: 优点是功能强大,能在毫不相关进程之间进行通讯; 缺陷是关键字KEY_T使用了内核标识,占用了内核资源,而且只能被显式删除,而且不能使用SOCKET的一些机制。
无名管道文件(单工通信,只能从一端到令一端)
#include <unistd.h>
int pipe(int filedes[2]);
函数功能:
产生一对文件描述符,其中filedes[0]用于读,filedes[1]用于写.
工作流程:
1.定义一组或多组描述符
2.利用描述符创建匿名管道文件
3.通过每组的读写属性在父子进程间建立通信
有名管道文件
#include<sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
函数功能:通过管道文件名和创建属性创建管道文件
工作流程:
1.在其中一个进程中创建管道文件
2.在两个进程中都打开该文件
3.一个进程读一个进程写
消息队列
#include<sys/msg.h>
#include<sys/ipc.h>
1.msgget函数说明
int msgget(key_t key,int flags)
flags分创建与打开
创建:IPC_CREAT|EXCL
打开:0
2.msgsnd函数说明
int msgsnd(int msgid
const void *msg,//消息缓冲
size_t size,//消息大小
int flags//消息发送方式
)
发送消息的长度是消息的长度,不是结构体的长度,结构体的第一个元素是系统用来维护队列的。
3.msgrcv函数说明
ssize_t msgrcv(int msqid,
void *msgp,//自定义结构体
size_t msgsz, //返回缓冲的空间大小(结构体第二个数据的大小)
long msgtyp,//和msgp里面的第一个参数相对应
int msgflg//
);
4.int msgctl(int msqid, int cmd, struct msqid_ds *buf);
使用方法和共享内存中的一致
共享内存
#include<sys/shm.h>
#include<sys/ipc.h>
1.shmget函数说明
int shmget(
key_t key,//唯一决定共享内存ID的生成
size_t size,//创建共享内存的大小
int flags//创建共享内存的方式与权限
flags:
);
id是根据key产生的
返回共享内存ID
filetokey把文件路径转化成Key
key_t ftok(const char*filepath,int projid);
filepath:文件路径名,因为在某个路径下文件是唯一的所以产生的key也是唯一的。
projid:微调作用,可能这个路径下有几个程序同时用了这个路径,就需要用不同的projid来区分这几个不同的程序产生不同的key。
2.shmat函数说明
void * shmat(int shmid,
const void *shmaddr, //NULL系统指定
int shmflg//指定挂载方式IPC_RDONLY或者0读写
)
返回:挂载成功返回内存地址,0就为失败
3.shmdt函数说明
int shmdt(const void *shmaddr);
4.shmctl函数说明
作用:控制(删除|获取共享内存的状态|修改共享内存状态的值)共享内存
int shmctl(int shmid,
int cmd,
struct shmid_ds *buf//只对IPC_STAT|IPC_SET有意义
);
信号量
#include<sys/ipc.h>
#include<sys/sem.h>
1.semget函数说明
int semget(key_t key,
int nsems,//创建的信号量的个数
int sem_flags//创建/打开信号量IPC_CREAT|IPC_EXCL,0
)
2.semop函数说明
int semop(int semid,
struct sembuf *op,//对信号量的操作
unsigned int nsops//第二个结构体数组的个数
)
3.semctl函数说明
删除ID
修改信号量
获取信号量
修改信号量状态
int semctl(int semid,
int index,//信号量下标
int cmd,//信号量的操作命令
... //对应命令的相关操作
)
十八、Linux多线程编程
1.Linux进程与线程
Linux进程创建一个新线程时线程将拥有自己的栈因为线程有自己的局部变量但与它的创建者共享全局变量、文件描述符、信号句柄和当前目录状态。Linux通过fork创建子进程与创建线程之间是有区别的fork创建出该进程的一份拷贝这个新进程拥有自己的变量和自己的PID它的时间调度是独立的它的执行几乎完全独立于父进程。进程可以看成一个资源的基本单位而线程是程序调度的基本单位一个进程内部的线程之间共享进程获得的时间片。
2._REENTRANT宏
在一个多线程程序里默认情况下只有一个errno变量供所有的线程共享。在一个线程准备获取刚才的错误代码时该变量很容易被另一个线程中的函数调用所改变。类似的问题还存在于fputs之类的函数中这些函数通常用一个单独的全局性区域来缓存输出数据。为解决这个问题需要使用可重入的例程。可重入代码可以被多次调用而仍然工作正常。编写的多线程程序通过定义宏_REENTRANT来告诉编译器我们需要可重入功能这个宏的定义必须出现于程序中的任何#include语句之前。
_REENTRANT为我们做三件事情并且做的非常优雅
1它会对部分函数重新定义它们的可安全重入的版本这些函数名字一般不会发生改变只是会在函数名后面添加_r字符串如函数名gethostbyname变成gethostbyname_r。
2stdio.h中原来以宏的形式实现的一些函数将变成可安全重入函数。
3在error.h中定义的变量error现在将成为一个函数调用它能够以一种安全的多线程方式来获取真正的errno的值。
3.线程的基本函数
大多数pthread_XXX系列的函数在失败时并未遵循UNIX函数的惯例返回-1这种情况在UNIX函数中属于一少部分。如果调用成功则返回值是0如果失败则返回错误代码。
1.线程创建
#include <pthread.h>
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void *), void
*arg);
参数说明
thread指向pthread_create类型的指针用于引用新创建的线程。
attr用于设置线程的属性一般不需要特殊的属性所以可以简单地设置为NULL。
*(*start_routine)(void *)传递新线程所要执行的函数地址。
arg新线程所要执行的函数的参数。
调用如果成功则返回值是0如果失败则返回错误代码。
2.线程终止 #include <pthread.h>
void pthread_exit(void *retval);
参数说明
retval返回指针指向线程向要返回的某个对象。
线程通过调用pthread_exit函数终止执行并返回一个指向某对象的指针。注意绝不能用它返回一个指向局部变量的指针因为线程调用该函数后这个局部变量就不存在了这将引起严重的程序漏洞。
3.线程同步
#include <pthread.h>
int pthread_join(pthread_t th, void **thread_return);
参数说明
th将要等待的张璐线程通过pthread_create返回的标识符来指定。
thread_return一个指针指向另一个指针而后者指向线程的返回值。
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
#include <string.h>
char str[] = "hello world";
void *pthreadFunc(void *arg);
/*
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
*/
int main()
{
pthread_t pthread; //线程标志
int res;
void *pthread_result;
res = pthread_create(&pthread,NULL,pthreadFunc,(void *)str);
if(res != 0)
{
perror("pthread_creadte error\n");
exit(EXIT_FAILURE);
}
printf("waiting..\n");
res = pthread_join(pthread,&pthread_result); //等待
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
printf("str --> %s\n",str);
printf("pthread return --> %s\n",pthread_result);
exit(0);
}
void *pthreadFunc(void *arg)
{
printf("gogogo...%s\n",str);
sleep(3);
strcpy(str,"eepw-->liklon");
pthread_exit("好久不见!\n");
}

如果不加-lpthread会出现undefined reference to 'pthread_create'问题
问题原因:
pthread 库不是 Linux 系统默认的库,连接时需要使用静态库 libpthread.a,所以在使用pthread_create()创建线程,以及调用 pthread_atfork()函数建立fork处理程序时,需要链接该库。
问题解决:
在编译中要加 -lpthread参数
gcc thread.c -o thread -lpthread
thread.c为你些的源文件,不要忘了加上头文件#include<pthread.h>
接下来是编写一个程序验证两个线程的执行是同时进行的。如果是在一个单处理器系统上线程的同时执行就需要靠CPU在线程之间的快速切换来实现了。 程序需要利用一个原理即除了局部变量外其他的变量在一个进程中的所有线程之间是共享的。在这个程序中是在两个线程之间使用轮询方式称为忙等待所以它的效率会很低。代码中两个线程会不断的轮询判断flag的值是否满足各自的要求。然后打印信息
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int flag = 1;
void *pthreadFunc(void *arg);
int main()
{
pthread_t pthread;
int count = 0;
int res;
void *pthreadResult;
res = pthread_create(&pthread,NULL,pthreadFunc,NULL);
if(res != 0)
{
perror("pthread_create error\n");
exit(EXIT_FAILURE);
}
while(count++ < 10)
{
if(flag == 1)
{
printf("-->eepw\n");
flag = 2;
}
else sleep(1);
}
printf("wait --> pthread finish\n");
res = pthread_join(pthread,&pthreadResult);
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
void *pthreadFunc(void *arg)
{
int count = 0;
while(count++ < 10)
{
if(flag == 2)
{
printf("-->liklon\n");
flag = 1;
}
else sleep(1);
}
pthread_exit(NULL);
}

续上一贴:
在一段代码中采用轮询的方式在两个线程之间不停地切换是非常笨拙且没有效率的实现方式,幸运的是专门有一级设计好的函数为我们提供更好的控制线程执行和访问代码临界区的方法。
本次代码是利用信号量让两个线程同步。
1.信号量创建
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数说明
sem 信号量对象。
pshared 控制信号量的类型0表示这个信号量是当前进程的局部信号量否则这个信号量就可以在多个进程之间共享。
value 信号量的初始值。
2.信号量控制
#include <semaphore.h>
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
sem_post的作用是以原子操作的方式给信号量的值加1。
sem_wait的作用是以原子操作的方式给信号量的值减1但它会等到信号量非0时才会开始减法操作。如果对值为0的信号量调用sem_wait这个函数就会等待直到有线程增加了该信号量的值使其不再为0。
3.信号量销毁
#include <semaphore.h>
int sem_destory(sem_t *sem);
这个函数的作用是用完信号量后对它进行清理清理该信号量所拥有的资源。如果你试图清理的信号量正被一些线程等待就会收到一个错误。 与大多数Linux函数一样这些函数在成功时都返回0。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
/*
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
*/
sem_t sem;
void *pthreadFunc(void *arg);
int main()
{
pthread_t pthread;
int count = 0;
int res;
void *pthreadResult;
res = sem_init(&sem,0,1); //信号量初始化
if(res != 0)
{
perror("sem inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_create(&pthread,NULL,pthreadFunc,NULL); //创建线程
if(res != 0)
{
perror("pthread_create error\n");
exit(EXIT_FAILURE);
}
while(count++ < 10)
{
sem_wait(&sem);
printf("-->eepw\n");
sem_post(&sem);
sleep(1);
}
printf("wait --> pthread finish\n");
res = pthread_join(pthread,&pthreadResult);
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
sem_destroy(&sem); //销毁信号量
exit(EXIT_SUCCESS);
}
void *pthreadFunc(void *arg)
{
int count = 0;
while(count++ < 10)
{
sem_wait(&sem);
printf("-->liklon\n");
sem_post(&sem);
sleep(1);
}
pthread_exit(NULL);
}

此段代码是在上一段代码基础上修改,看起来更加方便。
十九、线程同步--互斥锁
为了让多个线程达到同步的目的,在对于全局变量等大家都要用的资源的使用上,通常得保证同时只能由一个线程在用,一个线程没有宣布对它的释放之前,不能够给其他线程使用这个变量。
1.申请一个互斥锁
pthread_mutex_t mutex; //申请一个互斥锁
你可以声明多个互斥量。
在声明该变量后,你需要调用pthread_mutex_init()来创建该变量。pthread_mutex_init的格式如下:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);
第一个参数,mutext,也就是你之前声明的那个互斥量,第二个参数为该互斥量的属性。属性定义如下:
互斥量分为下面三种:
快速型(PTHREAD_MUTEX_FAST_NP)。这种类型也是默认的类型。该线程的行为正如上面所说的。
递归型(PTHREAD_MUTEX_RECURSIVE_NP)。如果遇到我们上面所提到的死锁情况,同一线程循环给互斥量上锁,那么系统将会知道该上锁行为来自同一线程,那么就会同意线程给该互斥量上锁。
错误检测型(PTHREAD_MUTEX_ERRORCHECK_NP)。如果该互斥量已经被上锁,那么后续的上锁将会失败而不会阻塞,pthread_mutex_lock()操作将会返回EDEADLK。可以通过函数
注意以下语句可以做到将一个互斥锁快速初始化为快速型。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
2.销毁一个互斥锁
pthread_mutex_destroy()用于注销一个互斥锁,API定义如下:
int pthread_mutex_destroy(pthread_mutex_t *mutex)
销毁一个互斥锁即意味着释放它所占用的资源,且要求锁当前处于开放状态。由于在Linux中,互斥锁并不占用任何资源,因此LinuxThreads中的pthread_mutex_destroy()除了检查锁状态以外(锁定状态则返回EBUSY)没有其他动作。
3.上锁(相当于windows下的EnterCriticalSection)
在创建该互斥量之后,你便可以使用它了。要得到互斥量,你需要调用下面的函数:
int pthread_mutex_lock(pthread_mutex_t *mutex);
该函数用来给互斥量上锁。互斥量一旦被上锁后,其他线程如果想给该互斥量上锁,那么就会阻塞在这个操作上。如果在此之前该互斥量已经被其他线程上锁,那么该操作将会一直阻塞在这个地方,直到获得该锁为止。
在得到互斥量后,你就可以进入关键代码区了。
4.解锁(相当于windows下的LeaveCriticalSection)
在操作完成后,你必须调用下面的函数来给互斥量解锁,也就是前面所说的释放。这样其他等待该锁的线程才有机会获得该锁,否则其他线程将会永远阻塞。
int pthread_mutex_unlock(pthread_mutex_t *mutex);
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
/*
int pthread_numtex_init()
*/
pthread_mutex_t mutex;
void *pthreadFunc(void *arg);
int main()
{
pthread_t pthread;
int count = 0;
int res;
void *pthreadResult;
res = pthread_mutex_init(&mutex,NULL);
if(res != 0)
{
perror("mutex inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_create(&pthread,NULL,pthreadFunc,NULL); //创建线程
if(res != 0)
{
perror("pthread_create error\n");
exit(EXIT_FAILURE);
}
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
printf("-->eepw\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
printf("wait --> pthread finish\n");
res = pthread_join(pthread,&pthreadResult);
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
pthread_mutex_destroy(&mutex); //销毁信号量
exit(EXIT_SUCCESS);
}
void *pthreadFunc(void *arg)
{
int count = 0;
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
printf("-->liklon\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
pthread_exit(NULL);
}

二十、线程同步--条件变量
条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起使用。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其它的某个线程改变了条件变量,它将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。一般说来,条件变量被用来进行线承间的同步。
1.条件变量的结构为pthread_cond_t
2.条件变量的初始化
int pthread_cond_init ((pthread_cond_t *__cond,__const pthread_condattr_t *__cond_attr));
其中cond是一个指向结构pthread_cond_t的指针,cond_attr是一个指向结构pthread_condattr_t的指针。结构pthread_condattr_t是条件变量的属性结构,和互斥锁一样我们可以用它来设置条件变量是进程内可用还是进程间可用,默认值是PTHREAD_ PROCESS_PRIVATE,即此条件变量被同一进程内的各个线程使用。注意初始化条件变量只有未被使用时才能重新初始化或被释放。
3.条件变量的释放
释放一个条件变量的函数为pthread_cond_ destroy(pthread_cond_t cond)
4.条件变量的等待
(1)函数pthread_cond_wait()使线程阻塞在一个条件变量上。它的函数原型为:
extern int pthread_cond_wait_P ((pthread_cond_t *__cond,pthread_mutex_t *__mutex));
线程解开mutex指向的锁并被条件变量cond阻塞。线程可以被函数pthread_cond_signal和函数pthread_cond_broadcast唤醒,但是要注意的是,条件变量只是起阻塞和唤醒线程的作用,具体的判断条件还需用户给出,例如一个变量是否为0等等,这一点我们从后面的例子中可以看到。线程被唤醒后,它将重新检查判断条件是否满足,如果还不满足,一般说来线程应该仍阻塞在这里,被等待被下一次唤醒。这个过程一般用while语句实现。
(2)另一个用来阻塞线程的函数是pthread_cond_timedwait(),它的原型为:
extern int pthread_cond_timedwait_P (pthread_cond_t *__cond,pthread_mutex_t *__mutex, __const struct timespec *__abstime);
它比函数pthread_cond_wait()多了一个时间参数,经历abstime段时间后,即使条件变量不满足,阻塞也被解除。
5.条件变量的解除改变
函数pthread_cond_signal()的原型为:
extern int pthread_cond_signal_P ((pthread_cond_t *__cond));
它用来释放被阻塞在条件变量cond上的一个线程。多个线程阻塞在此条件变量上时,哪一个线程被唤醒是由线程的调度策略 所决定的。要注意的是,必须用保护条件变量的互斥锁来保护这个函数,否则条件满足信号又可能在测试条件和调用pthread_cond_wait函数之间被发出,从而造成无限制的等待。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
/*
int pthread_numtex_init()
*/
pthread_mutex_t mutex;
pthread_cond_t cond_haha;
void *pthreadFunc(void *arg);
int main()
{
pthread_t pthread;
int count = 0;
int res;
void *pthreadResult;
res = pthread_mutex_init(&mutex,NULL);
if(res != 0)
{
perror("mutex inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_cond_init(&cond_haha,NULL);
if(res != 0)
{
perror("cond_haha inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_create(&pthread,NULL,pthreadFunc,NULL); //创建线程
if(res != 0)
{
perror("pthread_create error\n");
exit(EXIT_FAILURE);
}
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
if(count == 5) pthread_cond_wait(&cond_haha,&mutex);
printf("-->eepw\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
printf("wait --> pthread finish\n");
res = pthread_join(pthread,&pthreadResult);
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
pthread_mutex_destroy(&mutex); //销毁信号量
pthread_cond_destroy(&cond_haha);
exit(EXIT_SUCCESS);
}
void *pthreadFunc(void *arg)
{
int count = 0;
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
if(count == 5) pthread_cond_signal(&cond_haha);
printf("-->liklon\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
pthread_exit(NULL);
}

可以和上一段代码相互比较!!!
二十一、网络基础架构
网络这个部分以前没有认真的理解过,在网上也找了些文章看,讲的都挺乱的,感觉鸟哥写的这一段还不错,贴出来分享一下!!!
网络层的相关协议
-
在 OSI
七层协议中,最底层的三层被定位为网络层,这三层是最基本的网络架构了!虽然这三层通常已经被整合在操作系统与硬件里面了,所以我们根本不需要担心这三层的协议,不过,如果能够知道这些基础概念,对于未来在进行网络追踪时,帮助是很大的!底下我们就分别来谈一谈这三层的主要内容吧!不过,在开始之前,我们得先来谈一谈整个网络传输单位的定义说~
-
网络媒体:
什么是『网络媒体』说穿了,最基础的网络媒体就是『网络线』啰,因为我们都是透过网络线来进行电子讯号的交流的嘛 (再次请您留意,这里是以网络线为例,当然网络媒体还有相当多的样式的!)。好了,请注意的是,当所有的计算机要进行数据传递的时候,就是需要使用到这个所谓的网络媒体,而由于所有的计算机都连接在这个网络媒体上面,您可以将这个 Bus 的网络线当成是一个『共享媒体』啰!并且,这个共享媒体的传输限制为『单一时间点上面,只能有一部机器使用这个共享媒体』,这个概念相当的重要,先记下来吧! - 各计算机怎么知道该时间点上面有没有其它的机器在使用呢?
- 如果 PC1 与 PC2 要相互沟通的话,他们的讯号是怎样传输的,也就是说, PC1 怎么知道该讯号是要送到 PC2 呢?
- 如果同一个时间里面有两部计算机以上同时使用这个媒体,会产生什么情况?
- 由于这个网络共享媒体在每个时间点上面仅能让一部机器使用 ( 这个时间可能是几千到几万分之一秒,很短的啦!),因此,如果 PC 1 这部计算机想要利用这个媒体发送数据出去时,他就必须要确认当时在这个媒体上面没有其它的机器在使用。这个时候 PC1 就会先发送一个讯息封包到这个媒体上面去,告诉这个媒体上面的所有计算机主机说『喂!我要使用这个媒体了』!而其它的 PC2 ~ PC5 在接到这样的讯息封包后,就会暂时停顿自己的网络工作,让 PC1 可以顺利的使用网络媒体传送数据(这个停顿也是很短的啦!您感觉不出来的 ^_^ )。PC 1 发送讯息封包的这个行为就是所谓的『物理广播』(Physical Broadcast) 了,而这个动作也是最底层的动作吶!
- 知道了物理广播 ( Physical broadcast ) 的动作之后,再来,如果 PC1 与 PC 3 同时都想要使用网络媒体呢?呵呵!这个时候,就要看是谁先传送出广播信息的,当然是先抢先赢!例如:当 PC1 比 PC3 早一步向网络共享媒体送出物理广播信息,那么 PC3 就会先停顿,直到等到 PC1 将该次工作完毕之后,才会发送物理广播信息了。咦!您有没有发现这个地方很奇怪啊?!既然 PC 1 已经先抢先赢,万一 PC 1 要传送的数据高达 100 MB ,那么 PC 3 不是等到捉狂了?呵呵!回到刚刚我们提到的 OSI 七层协议里面的『传送层』的地方,里面说到了:由于网络物理机制的关系 ( 网络线的负荷啦、所有的网络周边啦等等的物理机器 ) ,每次进行网络传输时,该次的『封包大小』是有限制的!所以,如果 PC 1 的数据真的高达 100 MB 时,他也无法一次就将 100 MB 的数据打包成为一个 packet 的,网络媒体没有办法传输那么大的封包,所以当然就得将 100 MB拆开成为数个小 packet 再一次一次的传送出去啦!而每次的 physical broadcast 仅针对该次的 packet 发送而已,如果这个 packet 发送完,得再继续进行一次 physical broadcast 才能够再发送下一个 packet 喔!因此,这个 100MB 的传送得要 PC1 在这个共享媒体上面发送多次的 physical broadcast 才行哩!所以啦,如上面的例子来看,假设 PC1 要传输 100MB 而 PC3 要传输 10MB 时,他们是可以同时进行传输的,只是在网络媒体的使用上面,就会不断的进行物理广播,PC1 与 PC3 两个抢来抢去的,持续的将一个一个 packet 发送出去!这个时候网络媒体就很忙啦!
- 持续上面的例子,那么 PC1 与 PC3 可不可能『刚好』同时发出物理广播讯息呢?!当然可能啦!在一个很繁忙的共享网络媒体当中,由于可能使用者众多,加上使用者可能正在大量的传送档案数据,这个时候就容易发生同时发送物理广播信息的问题了!当发生在同一个网络媒体上面有两部主机以上同时发送物理广播的讯息时,两部主机该次的物理广播讯息就会无效,两部主机将不会进行数据的传送。不过也不需要太担心这样的情况,因为两部主机均会等待一段时间之后才再次进行物理广播的动作!而在等待的时间上面,是『在一段时间里面随机取一个时间点』来再次进行物理广播,(例如在千分之一秒的时间内,两部主机均随机取一个时间点,一部主机可能刚好选五千分之一秒,另一部选三千分之一秒,这样就避过再次同时发出物理广播讯息的问题。)由于是随机取样的,因此应该不太容易再造成同时进行物理广播的现象。万一真的不幸又同时物理广播,那么又会等待下一次....依序下去,好像超过 16 次以后,如果还真的很不幸(因为机率真的太低了)再次同时进行物理广播,那么就抱歉啦!您的网络媒体将瘫痪掉!不过也别担心,重新 reset ( 整个网络给他关机再开机 ) 就好啦! ^_^""
-
由上面的情况来看,网络媒体上面似乎在某一个时间点时只会有一个封包在进行传送喔,那么有没有可能发生一个网络共享媒体上面同时发送封包的状况呢?当然有啦!现在您假设
PC1 到 PC5 的距离是很远(假设 50 m 好了),那么当 PC1 与 PC5 发送出物理广播,提醒大家说要传送信息的时候,由于 PC1 与 PC5
的距离太远了,因此响应的时间比较长,那么这个时候可能就会造成主机的误判,认为当时媒体上面没有任何的机器在传送数据,所以就造成 PC1 与 PC5
同时传送出数据在媒体上面,这个时候就会发生所谓的『封包碰撞 ( collision
)』的情况了!因为网络媒体上面单一时间内仅能允许一个机器使用的嘛!所以封包碰撞就会造成该封包的损毁现象呢!比较麻烦啦!因为封包损毁了,所以
PC1 与 PC5 又得再次将该次的 packet 重新发送一次,又得要物理广播.....而为了避免封包碰撞的问题,所以目前网络上面都会使用一种称为CSMA/CD (
Carire Sense Multiple-Access / Collision Detect )的技术来避免因封包碰撞造成数据损毁的问题!不过,由于选择的媒体不同,所以还是很有可能会造成碰撞的啦!
-
关于
MAC:
在目前我们使用的以太网络卡上面,其实在出厂的时后就已经焊死一个网络卡的卡号在上面了,因为这个卡号是跟随着硬件的,所以一般我们也称为硬件地址 (Hardware address),而且每一张网络卡上面的卡号都不会重复!事实上,他是被称为Media Access Control, MAC的啦!MAC 的格式是六组 16 进位 (bytes) 的数据组合起来的,所以他共占掉 6 bytes ,基本的格式为:-
aa:bb:cc:dd:ee:ff
如同上面所示,在 Linux 底下,主要的格式是以『:』隔开的,在 Windows 底下,则是以『-』来隔开!无论如何,反正记得他是六组16进位的数据组成的就是了!使用的观察方式可以直接以 ifconfig 以及 ipconfig 来下达指令。1. 在 Linux 底下:
[root@test root]#ifconfig
eth0 Link encap:Ethernet HWaddr00:05:D3:43:E4:80
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
.....
2. 在 Windows 2000 底下:
C:\>ipconfig /allWindows 2000 IP Configuration
.....
Physical Address. . . . . . . . . :00-05-D3-43-E4-80
.....
-
关于 Address
Resolution Protocol, ARP:
现今最常用的网络传输是使用 TCP/IP 来进行的,所以每一部主机当然要有一个 IP 才行!然而我们知道数据其实是使用 MAC 在不同的网络卡之间互相传递,因此,必须要设定一个 IP 与 MAC 对应的方法才行,此时就有 ARP 协定的产生了。ARP 这个协议在目前主要的操作系统里面都存在着,例如 Linux 主机里面就有一个 ARP table 来纪录 IP 与 MAC 的对应信息。所以,当前面图二中, PC 1 (192.168.1.1) 要将数据传送到 PC2(192.168.1.2) ,那么 PC1 就会参考自己本身系统内的 arp table ,找到 192.168.1.2 对应的 MAC 之后,再将数据传送到那个 MAC 去!
-
在 PC1 首次进行数据传输的时候,由于 ARP table 当中没有相关的数据 ( 因为刚刚连上网络嘛! ) ,所以 PC 1 不知道
192.168.1.2 这个 IP 对应的是那个 MAC ,当然也就无法传递数据了。这个时候 PC 1 就会对『同一网域的全部计算机进行逻辑广播( logical broadcast )』,此时 PC 1 会发送一个带有本身的
MAC 与目标 IP (在这个例子中,也就是 192.168.1.2 ) 的逻辑广播封包给网域内的全部计算机( 在图二的例子中,包括 PC 2 ~ PC 5
均会收到这个逻辑广播封包 ) ;
-
在 PC 2 ~ PC 5 接到这个逻辑广播封包之后,由于这个逻辑广播封包的要求响应是 192.168.1.2 ,因为 PC 3 ~ PC 5
并不是这个 IP 的所有人,因此就会将这个逻辑广播封包丢弃不理。而 PC 2 收到这个逻辑广播封包时发现该封包要求的 IP 是自己的,此时他就会发送一个回应封包
( 该响应封包里面就含有 PC2 自己的 MAC ) 给 PC 1 ;
-
PC 1 在收到这个响应封包之后,就知道了 PC2 这个 192.168.1.2 IP 对应的 MAC 了,此时 PC 1 这部主机的 ARP
table 就会主动的将 IP 与 MAC 的对应给他写入表格中啦!而既然已经知道了 IP 对应 MAC 了,因此 PC1 就可以开始将资料传送给 PC 2
了!
-
未来,当 PC 1 要将资料再传给 PC 2 时,他会先由自己本身的 ARP table 里面去找寻是否有该主机的 IP 对应的 MAC
信息,如果找到了 PC 2 (192.168.1.2) 对应的 MAC ,那么 PC 1 将不会发送逻辑广播封包,而是直接依据 ARP table
里面的信息来将数据直接传送给 PC 2 的网络卡呢!也就是说:
- 如果 ARP table 有纪录的话,那么数据就会直接的传送到该目的地去,而不会进行『逻辑广播』;
- 如果 ARP table 没有纪录的话,那么主机就又会对全部的同一网域内的计算机进行『逻辑广播』。
传输单位
想一想,如果没有电的话,我们的网络是否能够通行无阻?!当然不行!因为网络其实就是电子讯号的传送啊!如果没有电,当然就没有办法传送讯息了。而电子讯号只有 0 跟 1 啊,所以在网络单位的计算上,一般通常是以二进制的 bit 为单位的。那么这个 bit 与我们通常用来计算档案大小的单位 bytes 有什么关连性?其实:
-
1byte = 8bits
所以啦,一般来说,我们看到的网络提供者(Internet Services Provide, ISP)所宣称他们的 ADSL 传输速度可以达到 下行/上行 512/64 Kbps ( Kbits per second) 时,那个 Kb 指的可不是 bytes 而是 bits 喔!所以 512/64 Kbps 在实际的档案大小传输速度上面,最大理论的传输为 64/8 KBps(KBytes per second),所以正常下载的速度约在每秒 45~50 KBytes 之间吶!同样的道理,在网络卡或者是一些网络媒体的广告上面,他们都会宣称自己的产品可以自动辨识传输速度为 10/100 Mbps ( Mega-bits per second),呵呵!该数值还是得再除以 8 才是我们一般常用的档案容量计算的单位 bytes 喔!这样可以了解传输单位的意义了吗?!
实体层
既然网络是由硬件来进行讯号传递的,所以在这里我们就先来谈一谈网络媒体的运作方式吧!不过网络媒体的连接方式有相当多的类型,例如近来比较常见的『星形联机』以及较早期的直线型总线 (bus) ,以及以基地台为基准的无线网络等等类型,不同的类型在讯号的传递上是不太一样的。不过,由于 Bus 类型的联机模式是比较容易理解的一种联机模式,所以底下我们以基本的 Bus 联机模式来进行说明。如下面图示所示: ( 虽然一般家庭网络最常见的联机模式为星形模式,不过基本原理上面还是与 Bus 布线模式相同的 )

图二、以 bus 串连计算机示意图 所有的计算机都经过同一个网络媒体(就是中间横向的那一条主要缆线)来进行连接。这个网络媒体上面有什么需要注意的地方呢?
现在我们知道讯号是藉由网络媒体来进行传递的,而这个媒体在单一时间点上面仅能让一个机器使用!果真如此的话,底下的问题该如何解决呢?
底下就需要针对上面的问题来说明一下咯:
在谈完了网络共享媒体之后,再来谈一谈目前最常见的网络配备,那就是以太网络的网络卡 ( Ethernet ) 。目前我们在计算机主机后面看到的类似电话线接头,但是比较大一点的,里头具有八条线的插槽,那就是以太网络卡。这个网络卡最大的特色是他具有一个焊死在上面的地址 ( 某些 Notebook 上面 PCMCIA 的网络卡是可调的 ) ,那就是Media Access Control (MAC),也常常被我们称为硬件地址 ( Hardware Address )。让我们翻回到 OSI 七层协议里面的数据连接层,在该层级中说明,每个框包 ( frame ) 要传送出去,必须要以硬件地址为传输的来源与目标,这就是网络卡与网络卡之间数据传输的最底层信息了。例如同样上面的图示,假设 PC 1 要将数据传送到 PC 2 上面去时,那么数据封包就必须要先取得 PC 2 主机的网络卡的 MAC 之后,才能够将数据传送给 PC2 呢!这个部分就需要在数据连接层来进行说明了。
数据连接层
在 TCP/IP 与 OSI 七层协议那个小节当中,我们知道网络世界上面使用来辨识计算机主机的是 IP ,这个 IP 是在 OSI 的第三层,也就是网络层的东西。而由上面的实体层的介绍,我们也可以知道其实数据封包由这个主机到下一个主机,使用的是 MAC 这个网络卡卡号 ( Hardware address ) 来进行传送的,那么 IP 与 MAC 有什么关系啊?!举个例子来说,同样的以上面图二为例好了,假设 PC 1 的 IP 是 192.168.1.1 而 PC2 的 IP 是 192.168.1.2 ,那么数据要由 PC 1 传送到 PC 2 的时后,到底是怎么进行传送的?其实也不难啦!因为数据要传送就得知道网络卡卡号,因此 PC1 必须要先知道 PC2 的 Hardware Address 之后,才能将数据由 PC1 的网络卡传送给 PC2 的网络卡上。也就是说,IP 必须要与 MAC ( 就是 Hardware address 啦 ) 对应起来才行!这个时候,就需要使用到Address Resolution Protocol (ARP)协定了。底下我们就介绍一下 MAC 的格式,以及 ARP 的内容。
|
[root@test root]#arp [-and] hostname [root@test root]#arp -s hostname(IP) Hardware_address 参数说明: -a :显示出目前主机所有的 IP 对应 MAC 状态 -n :将主机名称以 IP 的型态显示 -d :将 hostname 的 hardware_address 由 ARP table 当中删除掉 -s :设定某个 IP 或 hostname 的 MAC 到 ARP table 当中 范例: [root@test root]#arp Address HWtype HWaddress Flags Mask Iface localhost ether 08:00:20:C5:89:4D C eth0 [root@test root]#arp -n Address HWtype HWaddress Flags Mask Iface 192.168.1.1 ether 08:00:20:C5:89:4D C eth0 [root@test root]#arp -s 192.168.1.100 01:00:2D:23:A1:0E |
在谈完了 OSI 七层协议里面的实体层与数据连接层之后,接下来就是最重要的网络层了!不过,因为网络层里面的 IP 实在太重要了,所以我们将他独立出一个小节来继续介绍。当然,底下就独立的来介绍与 IP 相关的一些概念,包含了 Netmask, Broadcast, Gateway 以及网域的概念等等。
Internet Protocol, IP 概念
-
认识了最底层的网络共享媒体与数据链路层的 ARP 及 MAC 概念之后,接下来要跟大家介绍的就是那个可爱又可恨的网络门牌『Internet Protocol, IP』了,IP
是所有网络的基础,没有了他,您的网络将只是一堆废铁啊!赶紧来认识一下吧!
- 在同一个网段内,Net_ID 是不变的,而 Host_ID 则是不可重复,此外, Host_ID 在二进制的表示法当中,不可同时为 0 也不可同时为 1 ,例如上面的例子当中, 192.168.0.0 ( Host_ID 全部为 0 )以及 192.168.0.255 ( Host_ID 全部为 1 ) 不可用来作为网段内主机的 IP 设定,也就是说,这个网段内可用来设定主机的 IP 是由 192.168.0.1 到 192.168.0.254;
- 在同一个网域之内,每一部主机都可以藉由逻辑广播 ( logical broadcast ) 取得网域内其它主机的 MAC 对应 IP;
- 由上面的逻辑广播动作取得 MAC 之后(亦即 ARP 协议),在同一个网域之内,主机的数据可以直接透过彼此的 NIC ( Network Interface Card, 网络卡 ) 进行传送;
- 在同一个物理网段之内,如果两部主机设定成不同的 IP 网段,则两部主机无法直接以逻辑广播进行数据的传递 ( 在没有设定特殊 route 规则的情况下 )。
- A Class:10.0.0.0 - 10.255.255.255
- B Class:172.16.0.0 - 172.31.255.255
- C Class:192.168.0.0 - 192.168.255.255
- 私有地址的路由信息不能对外散播 (就是内部网络咯);
- 使用私有地址作为来源或目的地址的封包,不能透过 Internet 来转送 (呵呵!当然啰!不然网络会混乱);
- 关于私有地址的参考纪录(如DNS),只能限于内部网络使用(一样的原理啦!)
- 固定制手动设定:我们可以取得固定的 Public IP ,取得的管道可以是学术网络、或者是向 ISP 注册固定的 Public IP。不过,在使用固定的 Public IP 时,您必须要手动的在您的操作系统设定好网络参数;
- 浮动式拨接:除了上述的方法之外,传统的以调制解调器拨接,以及目前很流行的 ADSL 拨接,都是另一个取得 Public IP 的方法,只不过由于这种拨接的方法中,取得的 IP 是由 ISP 随机提供的,因此每次拨接到 ISP 后取得的 IP 可能都不是固定的,所以也有人称这种取得 IP 的方式为浮动式;
- 缆线, Cable modem:利用单向或者是双向 Cable 也可以向 ISP 注册取得 Public IP;
IP 的组成:
我们目前在网络上使用的 IP 协议是第四版,也就是被称为IPv4的一个协定。在这个协议当中,最重要的就是 IP 的组成了。IP 主要是由 32 bits 的资料所组成的一组数据,也就是 32 组 0 跟 1 所组成的数据数据,因为只有零跟一,所以 IP 的组成当然就是计算机认识的二进制的表示方式了。不过,因为人类对于二进制实在是不怎么熟悉,所以为了顺应人们对于十进制的依赖性,因此,就将 32 bits 的 IP 分成四小段,每段含有 8 个 bits ,将 8 个 bits 计算成为十进制,并且每一段中间以小数点隔开,那就成了目前大家所熟悉的 IP 的书写模样了。如下所示:
|
IP 的表示式: 00000000.00000000.00000000.00000000==>0.0.0.0 11111111.11111111.11111111.11111111==>255.255.255.255 |
所以 IP 最小可以由 0.0.0.0 一直到 255.255.255.255 哩!事实上, IP 的组成当中,除了以 32 bits 的组成方式来说明外,还具有所谓的『网域』的概念存在。底下就来谈一谈什么是网域吧!
网域的概念
事实上 IP 的 32 bits 数据中,可以分为 HOST_ID 与 Net_ID 两部份,我们先以 192.168.0.0 ~ 192.168.0.255 这个 C Class 的网域当作例子来说明好了:
|
192.168.0.0~192.168.0.255 这个 C Class
的说明: 11000000.10101000.00000000.00000000 11000000.10101000.00000000.11111111 |----------Net_ID---------|-host--| |
在 C Class 的范例当中,前面三组数字 (192.168.0) 称为 Net_ID,最后面一组数字则称为 Host_ID。同一个网域当中的定义是『在同一个物理网段内,主机的 IP 具有相同的 Net_ID ,并且具有独特的 Host_ID』,那么这些 IP 群就是同一个网域内的 IP 网段啦! (注:什么物理网段呢?举例来说,上图二所有的主机都是使用同一个网络媒体串在一起,这个时候这些主机在实体装置上面其实是联机在一起的,那么就可以称为这些主机在同一个物理网段内了!同时并请注意,同一个物理网段之内,可以依据不同的 IP 的设定,而设定成多个『IP 网段』喔! ) 例如上面例子当中的 192.168.0.1, 192.168.0.2, ...., 192.168.0.255 这些 IP 就是同一个网域内的 IP 群(同一个网域也称为同一个网段!),请注意,同一个 Net_ID 内,不能具有相同的 Host_ID ,例如上图二当中, PC 1 与 PC 5 不能同时具有 192.168.0.1 这个 IP ,否则就会发生 IP 冲突,可能会造成两部主机都没有办法使用网络的问题!那么同一个网域该怎么设定,与将 IP 设定在同一个网域之内有什么好处呢?
所以说,我们家里的所有计算机当然都设定在同一个网域内是最方便的,因为如此一来每一部计算机都可以直接进行数据的交流,而不必经由 Router ( 路由器 ) 来进行封包的沟通呢!( Router 这部份在后续才会提及! )。好了,刚刚我们上面说的是 C Class 的网域,那么有没有其它 Class 的网域呢?而且他们又是怎么区分的呢?目前 Internet 将整个 IP 简单的方类成为三个网段,分别设定为所谓的 A, B, C 三个 Class ,他们的分类原则如下:
|
以二进制说明 Network 第一个数字的定义: A Class : 0xxxxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==>开头是 0 |--net--|---------host------------| B Class : 10xxxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==>开头是 10 |------net-------|------host------| C Class : 110xxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==>开头是 110 |-----------net-----------|-host--| 以十进制说明 Network 的定义: A Class : 0.xx.xx.xx ~ 126.xx.xx.xx B Class : 128.xx.xx.xx ~ 191.xx.xx.xx C Class : 192.xx.xx.xx ~ 223.xx.xx.xx |
在上表中,可能您会觉得很奇怪,咦!那个 127.xx.xx.xx 怎么不见了?!他应该也是 A Class 的一段吧?!没错,是不见了,因为这个网段被拿去给操作系统做为内部循环网络 ( loopback )之用了!在各个操作系统当中,不管该主机的硬件有没有网络卡,为了让作业确认自己的网络没有问题,所以将 127.xx.xx.xx 这个 A Class 的网段拿到操作系统当中,来做为内部的回路测试!所以啦,这个 127.0.0.1 就不可以用来做为网络网域的设定了。
Netmask 的用途 (效能) 与子网络的切分
在上一小节当中提到的 A, B, C 三个层级的网域是由 IP 协定预设分配的,在这样的层级当中,我们可以发现 A Class 可以用于设定计算机主机的 IP 数量 ( Host ) 真的是很多,在同一个 A Class 的网域内,主机的数量可以达到『256 X 256 X 256 - 2(HostID全为0或1) = 16777214』,不过,这样的设定情况对于一般网络的效能却是不太好的!为什么呢?让我们回到 OSI 七层协议里面的共享媒体上面,还记得共享媒体上面主机 A 要发送数据出去的时后,需要先进行『物理广播』来确认媒体上面没有人在使用吧?而其它的主机在接收到这样的物理广播封包之后,就得要先将手边关于网络的工作停顿下来等主机 A 将动作做完之后,其它的主机才能进行下一次的物理广播。所以如果我们是以 A Class 的架构来架设我们的网络的话,那么当一部主机要传送数据时,其它的所有主机都得要停顿的吶!而且,如此大型的网域内,肯定更容易发生封包碰撞 ( Collision ) 的问题,而且在进行逻辑广播的时后,响应的计算机主机数量也实在是太多了!如此一来,整个网络的效能将会变的很糟糕!所以,一般来说,我们最多都仅设定 C Class 做为整个局域网络的架构,其实就连 C Class 也都太大了!不过不打紧,只要记得一个网域内不要超过 30 部以上的主机数量,那样网络的效能就会比较好一点~
其实,除了 C Class 之外,我们还是可以继续将网络切的更细的!上个章节我们提到 IP 分为 Net_ID 与 Host_ID,其中 C Class 的 Net_ID 占了 24 bits ,而其实我们还可以将这样的网域切的更细,就是让第一个 Host_ID 被拿来作为 Net_ID ,所以,整个 Net_ID 就有 25 bits ,至于 Host_ID 则减少为 7 bits 。在这样的情况下,原来的一个 C Class 的网域就可以被切分为两个子网域,而每个子网域就有『256/2 - 2 = 126』个可用的 IP 了!这样一来,在这个网域当中的主机在进行逻辑广播时,响应的主机数量就少了一半,当然对于网络的效能多多少少有点好处的啦!
好了,知道了子网络切分的大致情况后,现在要谈的是,那么到底是什么参数来达成子网络的切分呢?呵呵!那就是 Netmask ( 子网掩码 ) 的用途啦!这个 Netmask 是用来定义出网域的最重要的一个参数了!不过他也最难理解了~ @_@。为了帮助大家比较容易记忆住 Netmask 的设定依据,底下我们介绍一个比较容易记忆的方法。同样以 192.168.0.0~192.168.0.255 这个网域为范例好了,如下所示,这个 IP 网段可以分为 Net_ID 与 Host_ID,既然 Net_ID 是不可变的,那就假设他所占据的 bits 已经被用光了 ( 全部为 1 ),而 Host_ID 是可变的,就将他想成是保留着 ( 全部为 0 ),所以, Netmask 的表示就成为:
|
192.168.0.0~192.168.0.255 这个 C Class
的说明: 11000000.10101000.00000000.00000000 11000000.10101000.00000000.11111111 |----------Net_ID---------|-host--| 11111111.11111111.11111111.00000000 <== Netmask 二进制 255 . 255 . 255 . 0 <== Netmask 十进制 |
将他转成十进制的话,就成为『255.255.255.0』啦!这样记忆简单多了吧!照这样的记忆方法,那么 A, B, C Class 的 Netmask 表示就成为这样:
|
Netmask 表示方式: A Class : 11111111.00000000.00000000.00000000 ==> 255. 0. 0. 0 B Class : 11111111.11111111.00000000.00000000 ==> 255.255. 0. 0 C Class : 11111111.11111111.11111111.00000000 ==> 255.255.255. 0 |
所以说, 192.168.0.0~192.168.0.255 这个 C Class 的网域中,他的 Netmask 就是 255.255.255.0 了!再来,我们刚刚提到了当 Host_ID 全部为 0 以及全部为 1 的时后该 IP 是不可以使用的,因为 Host_ID 全部为 0 的时后,表示 IP 是该网段的 Network ,至于全部为 1 的时后就表示该网段最后一个 IP ,也称为 Broadcast ,所以说,在 192.168.0.0 ~ 192.168.0.255 这个 IP 网段里面的相关网络参数就有:
|
Netmask:
255.255.255.0 <==网域定义中,最重要的参数 Network: 192.168.0.0 <==第一个 IP Broadcast: 192.168.0.255 <==最后一个 IP 可用的 IP 数: 192.168.0.1 ~ 192.168.0.254 |
一般来说,如果我们知道了 Network 以及 Netmask 之后,就可以定义出该网域的所有 IP 了!因为由 Netmask 就可以推算出来 Broadcast 的 IP 啊!因此,我们常常会以 Network 以及 Netmask 来表示一个网域,例如这样的写法:
|
Network/Netmask 192.168.0.0/255.255.255.0 192.168.0.0/24 |
另外,既然 Netmask 里面的 Net_ID 都是 1 ,那么 C Class 共有 24 bits 的 Net_ID ,所以啦,就有类似上面 192.168.0.0/24 这样的写法啰!这就是一般网域的表示方法。好了,刚刚提到 C Class 还可以继续进行子网域 ( Subnet ) 的切分啊,以 192.168.0.0/24 这个情况为例,他要如何再细分为两个子网域呢?我们已经知道 Host_ID 可以拿来当作 Net_ID,那么 Net_ID 使用了 25 bits 时,就会如下所示:
|
原本的 C Class: 11000000.10101000.00000000.00000000 11000000.10101000.00000000.11111111 |----------Net_ID---------|-host--| 切成两个子网络 子网络一: 11000000.10101000.00000000.00000000 <==Network 11000000.10101000.00000000.01111111 <==Broadcast |----------Net_ID----------|-host-| 11111111.11111111.11111111.10000000<==Netmask 二进制 255 . 255 . 255 . 128 <==Netmask 十进制 所有 IP 与网域表示式: 192.168.0.0 ~ 192.168.0.127 192.168.0.0/25或192.168.0.0/255.255.255.128 子网络二: 11000000.10101000.00000000.10000000 <==Network 11000000.10101000.00000000.11111111 <==Broadcast |----------Net_ID----------|-host-| 11111111.11111111.11111111.10000000 <==Netmask 二进制 255 . 255 . 255 . 128 <==Netmask 十进制 所有 IP 与网域表示式: 192.168.0.128 ~ 192.168.0.255 192.168.0.128/25或192.168.0.128/255.255.255.128 |
所以说,当再细分下去时,就会得到两个子网域,而两个子网域还可以再细分下去喔 (Net_ID 用掉 26 bits ....)。呵呵!如果您真的能够理解 IP, Network, Broadcast, Netmask 的话,恭喜您,未来的服务器学习之路已经顺畅了一半啦! ^_^
IP 的种类与 IP 的取得方式
接下来要跟大家谈一谈也是很容易造成大家困扰的一个部分,那就是 IP 的种类!很多朋友常常听到什么『真实IP, 实体 IP, 虚拟 IP, 假的 IP....』烦都烦死了~其实不要太紧张啦!实际上,在 IPv4 里面就只有两种 IP 的种类,一种称为Public IP,翻译成为公共的或者是公开的 IP,另一种则是Private IP,翻译成为『私有 IP』或者是『内部保留 IP』。那么这两种 IP 要怎么分呢?很简单,只要『能够直接而不必透过其它机制就能与 Internet 上面的主机进行沟通的,那就是 public IP;无法直接与 Internet 上面沟通的,那就是 Private IP』。这是一个很简单的分辨方法啦!
早在 IPv4 规划的时候就担心 IP 会有不足的情况,而且为了应付某些私有网络的网络设定,于是就有了私有 IP ( Private IP ) 的产生了。私有 IP 也分别在 A, B, C 三个 Class 当中各保留一段作为私有 IP 网段,那就是:
由于这三个 Class 的 IP 是预留使用的,所以并不能直接作为 Internet 上面的连接之用,不然的话,到处都有相同的 IP 啰!那怎么行!网络岂不混乱?所以啰,这三个 IP 网段就只做为内部私有网域的 IP 沟通之用,也就是说,他有底下的几个限制:
这个私有 IP 有什么好处呢?呵呵!由于他的私有路由不能对外直接提供信息,所以呢,您的虚拟网络将不会直接被 Internet 上面的 Cracker 所攻击!但是,当然啰,您也就无法以私有 IP 来『直接上网』啰!所以相当适合一些尚未具有 Public IP 的企业内部用来规划其网络之设定之用!否则当您随便指定一些可能是 Public IP 的网段来规划您的企业内部的网络设定时,万一哪一天真的连上 Internet 了,那么启不是可能会造成跟 Internet 上面的 Public IP 相同了吗?!这可不是闹着玩的,要将您原先规划的 IP 网段整个重新调整过呢!哈哈!累死了!那么万一您又要将这些私有 IP 送上 Internet 呢?呵呵!这个简单,设定一个简单的防火墙加上 NAT ( Network Address Transfer ) 主机设定,您就可以透过 IP 伪装(不要急,这个在后面也会提到!)来使您的私有 IP 的计算机也可以连上 Internet 啰(虽然不是真的直接,但是很像『直接上网』呢!)
好了,那么除了这个预留的 IP 网段的问题之外,还有没有什么其它的怪东西呢?呵呵!当然是有啦!不然我干嘛花时间来唬 XX 呢!?没错,还有一个奇怪的 A Class 的网域,那就是 lo 这个奇怪的网域啦 ( 注意:是小写的 o 而不是零喔! )这个 lo 的网络是当初被用来作为测试操作系统内部循环所用的一个网域!简单的说,如果您没有安装网络卡在您的机器上面,但是您又希望可以测试一下在您的机器上面设定的数据到底可不可以被执行,这个时候怎么办,嘿嘿!就是利用这个所谓的内部循环网络啦!这个网段在 127.0.0.0/8 这个 A Class ,而且预设的主机 ( localhost ) 的 IP 是 127.0.0.1 呦!所以啰,当您启动了您的 WWW 服务器,然后在您的主机的 X-Window 上面执行 http://localhost 就可以直接看到您的主页啰!而且不需要安装网络卡呢!测试很方便吧!此外,您的内部使用的 mail 怎么运送邮件呢?例如您的主机系统如何 mail 给 root 这个人呢?嘿嘿!也就是使用这一个内部循环啦!当要测试您的 TCP/IP 封包与状态是否正常时,可以使用这个呦!( 所以哪一天有人问您:嘿!您的主机上面没有网络卡,那么您可以测试您的 WWW 服务器设定是否正确吗?这个时候可得回答:当然可以啰!使用 127.0.0.1 这个 Address 呀! ^_^... )
理解了 IP 的种类之后,我们已经知道了要连上 Internet 就得要取得 Public IP 才可以,至于 private IP 则是用在内部的私有网络之用的!那么该如何取得 Public IP 呢?目前在台湾地区有几个可取得 Public IP 的方法:
请记得,IP 就只有 Public 与 Private IP 这两种,而由于取得 IP 的方法不同,可能又有人喜欢宣称浮动式、固定制、动态等等的 IP ,这很容易造成刚刚接触网络的朋友们的困扰!所以这里仅告诉大家记得『Public 与 Private IP』而已!您只要记得他就对了!其它的,以后自然就会理解的啦! ^_^
路由 ( route ) 的概念
- Gateway / Router:网关/路由器的功能就是在负责不同网域之间的封包转递 ( IP Forwarder ),由于路由器具有 IP Forwarder 的功能,并且具有管理路由的能力,所以可以将来自不同网域之间的封包进行转递的功能。
- 当 PC 01 的数据被打包之后,其封包资料上面就至少具有来源地与目的地的 IP 地址;
- 首先, PC 01 会先分析该封包的目的地 IP 地址是否在同一个网域当中,如果该封包是在同一个网域当中,则 PC 01 可以藉由他本身的 ARP 表以及逻辑广播来取得目的地 IP 的 MAC ,并进一步来进行该封包的传送;
- 不过在这个例子当中,因为 PC 11 并不在 PC 01 所在的网域之内,此时 PC 01 会找自己本身的路由表 ( Route table ),看看 PC 11 在不在自己的路由表之内的某个规则中,若有,则依照该规则传送到下一个主机去(通常就是 Router 啦!);
- 在我们这个例子当中,并没有给予 PC 01 特殊的路由规则,所以 PC 01 是找不到 PC 11 所在的网域的路由规则的,此时 PC 01 将会把该封包数据直接丢给在 PC01 本身路由规则当中的『预设路由器, default gateway』主机,也就是 192.168.0.254 那部 Gateway (GW) 上面去,由于 Server A 的 192.168.0.254 接口与 PC 01 是在同一个网域之内,所以 PC 01 是可以直接与 Server A 传送资料的 (注:也就是说, Gateway 与您的主机之间,必须要在同一个网段之内才行!);
- Server A 的 192.168.0.254 收到该封包之后,会依照 Server A 自己本身的路由表找到 192.168.1.1 这部主机的路由规则!刚好在自己的另一个接口 192.168.1.254 的同一个网段内,所以透过 IP Forwarder 的功能,将该封包由 192.168.1.254 传送到 192.168.1.1 那部 PC 11 上面去!
- IP;
- network;
- netmask;
- broadcast;
- gateway
- IP:由 192.168.0.1~254
- Network:192.168.0.0
- Netmask:255.255.255.0
- Broadcast:192.168.0.255
- Gateway :每个人的设定都不同,请询问您的网络管理员!呵呵!就是您自己啦!
什么是路由 ( Route )
在前面关于数据传送的所有介绍都是在『同一个网域』里面的情况,我们都是以图二的案例来说明的。那么万一我们的数据需要跨网域时,数据是怎么传送的呢?这个时候就需要讨论到路由 ( route ) 的概念了。例如下面的图例所示,Network A 与 Network B 是分开的两个网域,而他们是藉由 Server A 那部主机来进行硬件的连结。当 Network A 的 PC 01 要跟 Network B 的 PC 11 进行数据的传输时,他需要什么样的传输方式呢?

图三、简易的路由示意图 由上面的图示中,我们可以知道 Network A 为 192.168.0.0/24 这个网域,而 Network B 为 192.168.1.0/24 这个网域,这两个网域是不能直接相通的!所以 PC 01 可以透过逻辑广播以及 ARP table 来与 PC 02 传输数据,不过 PC 01 却无法直接与 PC 11 相互沟通的,因为这两部主机在不同的网域里面啊!那么就无法以 broadcast 的方式来达到传送讯息封包了。
事实上,两部主机之间能不能进行数据的传输,除了 MAC 、 ARP 以及 IP 等参数是否正确之外,还需要很重要的一个参数,那就是路由 ( route )!目前的操作系统都很亲切的,已经将同一个网段的网域建立的基本的路由了,所以当我们在同一个网段内时,就无须考虑路由,而可以直接藉由 ARP 的对应,而直接以网络卡 (NIC) 进行数据的传输。但是,万一发生了类似上面的架构当中的 PC 01 与 PC 11 的状况时,那么 PC 01 就需要藉由一部路由器 (Router)来帮他达成数据的传送了!
以 PC 01 要将数据传送到 PC 11 的案例来说明:
大致的情况就是这样,所以啦,每一部主机里面都会存在着一个路由表 ( Route table ),数据的传递将依据这个路由表进行传送!而一旦封包已经经由路由表的规则传送出去后,那么主机本身就已经不再管封包的流向了,因为该封包的流向将是下一个主机 (也就是那部 Router )来进行传送,而 Router 在传送时,也是依据 Router 自己的路由表来判断该封包应该经由哪里传送出去的!例如底下的图例:
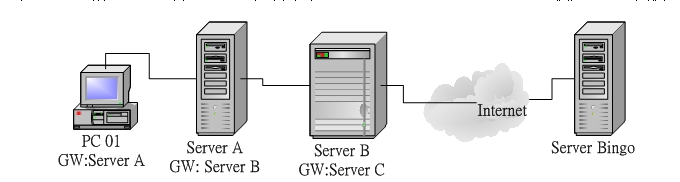
图四、路由的概念 PC 01 要将资料送到 Server Bingo 去,则依据自己的路由表,将该封包送到 Server A 去,Server A 再继续送到 Server B ,然后在一个一个的接力给他送下去,最后总是可以到达 Server Bingo 的。
当然,上面的案例是一个很简单的路由概念,事实上, Internet 上面的路由协议与变化是相当复杂的,因为 Internet 上面的路由并不是静态的,他可以随时因为环境的变化而修订每个封包的传送方向。举例来说,数年前在新竹因为土木施工导致台湾西部整个网络缆线的中断。不过南北的网络竟然还是能通,为什么呢?因为路由已经判断出西部缆线的终止,因此他自动的导向台湾东部的花莲路线,虽然如此一来绕了一大圈,而且造成网络的大塞车,不过封包还是能通就是了!这个例子仅是想告诉大家,我们上面提的路由仅是一个很简单的静态路由情况,如果想要更深入的了解 route ,请自行参考相关书籍喔! ^_^ 。
观察主机的路由
既然路由是这么的重要,而且『路由一旦设定错误,将会造成某些封包完全无法正确的送出去!』所以我们当然需要好好的来观察一下我们主机的路由表啦!还是请再注意一下,每一部主机都有自己的路由表喔!观察路由表的指令很简单,就是 route ,这个指令挺难的,我们在后面章节再继续的介绍,这里仅说明一些比较简单的用法:
|
[root@test root]#route [-n] 参数说明: -n :将主机名称以 IP 的方式显示 范例: [root@test root]#route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.0.0 * 255.255.255.0 U 0 0 0 eth0 127.0.0.0 * 255.0.0.0 U 0 0 0 lo default 192.168.0.254 0.0.0.0 UG 0 0 0 eth0 [root@test root]#route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 192.168.0.254 0.0.0.0 UG 0 0 0 eth0 |
在上面的例子当中,我们以 PC 01 的状态来进行说明。由于 PC 01 为 192.168.0.0/24 这个网域,所以主机已经建立了这个网域的路由了,那就是『192.168.0.0 * 255.255.255.0 ...』那一行所显示的讯息!当您下达 route 时,屏幕上说明了这部机器上面共有三个路由规则,第一栏为『目的地的网域』,例如 192.168.0.0 就是一个网域咯,最后一栏显示的是『要去到这个目的地要使用哪一个网络接口!』例如 eth0 就是网络卡的装置代号啦。如果我们要传送的封包在路由规则里面的 192.168.0.0/255.255.255.0 或者 127.0.0.0/255.0.0.0 里面时,因为第二栏 Gateway 为 * ,所以就会直接以后面的网络接口来传送出去,而不透过 Gateway 咯!
万一我们要传送的封包目的地 IP 不在路由规则里面,那么就会将封包传送到『default』所在的那个路由规则去,也就是 192.168.0.254 那个 Gateway 喔!所以,几乎每一部主机都会有一个 default gateway 来帮他们负责所有非网域内的封包转递!这是很重要的概念喔!^_^!关于更多的路由功能与设定方法,我们在后面的『简易 Router 架设』当中会再次的提及呢!
一组网络设定需要的参数
由上面的介绍中,我们知道一部主机要能够使用网络,必须要有 IP ,而 IP 的设定当中,就必须要有 IP, Network, Broadcast, Netmask 等参数,此外,还需要考虑到路由里面的 Default Gateway 才能够正确的将非同网域的封包给他传送出去,所以说,一组合理的网络设定需要哪些数据呢?呵呵!就是:
没错!就是这些数据!如果您是使用 ADSL 拨接来上网的话,上面这些数据都是由 ISP 直接给您的,那您只要使用拨接程序进行拨接到 ISP 的工作之后,这些数据就自动的在您的主机上面设定完成了!但是如果是固定制 ( 如学术网络 ) 的话,那么就得自行使用上面的参数来设定您的主机啰!缺一不可呢!以 192.168.0.0 这个 C Class 为例的话,那么您就必须要在您的主机上面设定好底下的参数:
-
终于给他来到了封包格式的地方了!上面的咚咚大多是在网络最底层的基础知识,得自行好好的理解理解!第一次看不懂没关系,多看几次,并且实际配合实做,就比较容易进入状况了!假设您已经知道了网络最底层的
IP
以及相关的参数的意义,那么应该知道的是,网络层的协议只是提供路由的判断,以确定封包的传送路径,但是这些协议并没有管理可能由于网络媒体的损坏问题,或者是网络的负荷过重以及其它不可预期的情况,而造成封包损毁或者被丢弃的状态。为了使封包的传送过程中更具有稳定性与可靠性,我们就得提供一套机制来让数据可以没有错误的到达到目的地。
- 21-20:FTP ( ftp-data )
- 22 :SSH
- 23 :Telnet
- 25 :SMTP ( e-mail )
- 80 :WWW
- 110 :POP3 ( e-mail )
- 来源 IP ( Source Address )
- 目的 IP ( Destination Address )
- 来源埠口 ( Source Port )
- 目的埠口 ( Destination Port )
-
Source Port & Destination Port ( 来源埠口 & 目标端口口
):来源与目标的端口口,这个容易了解吧!上面才刚刚提过那个埠口的观念呢!再次的给他强调一下, Linux 的 daemon 名称对应 Port number 是记录在
/etc/services 里面的喔!而且,小于 1024 以下的 Port 只有 root 身份才能启用,至于一般 Client 发起的联机,通常是使用大于
1024 以上的埠口!
-
Sequence Number ( 封包序号 ):在前面的 OSI 七层协议里面提到过,由于种种的限制,所以一次传送的封包大小大约仅有数千 bytes
,但是我们的资料可能大于这个封包所可以允许的最大容量,所以就得要将我们的数据给他拆成数个封包来进行传送到目的地主机的动作了。那么对方主机怎么知道这些封包是有关连性的呢?就得藉由这个
Sequence Number
来辅助了。当发送端要发送封包时,会为这个封包设定一个序号,然后再依据要传送的数据长度,依序的增加序号。也就是说,我们可以使用递增的值来替下一个封包做为他序号的设定!
-
Acknowledgment Number ( 回应序号 ):由刚刚图五的封包传输过程中,我们知道在接受端接收了封包之后,会响应发送端一个响应封包,那个响应的信息就是在这里啦!当接收端收到
TCP 封包并且通过检验确认接收该封包后,就会依照原 TCP
封包的发送序号再加上数据长度以产生一个响应的序号,而附在回应给发送端的响应封包上面,这样发送端就可以知道接收端已经正确的接收成功该 TCP 封包了!所以说,
Sequence 与 Acknowledgment number 是 TCP 封包之所以可靠的保证啊!因为他可以用来检测封包是否正确的被接受者所接收呢!
-
Data Offset (资料补偿):这是用来记录表头长度用的一个字段。
-
Reserved (保留):未使用的保留字段。
-
Control Flag (控制标志码):控制标志码在 TCP
封包的联机过程当中,是相当重要的一个标志,先来说一说这六个句柄,然后再来讨论吧:
- Urgent data:如果 URG 为 1 时,表示这是一个紧急的封包数据,接收端应该优先处理;
- Acknowledge field significant:刚刚上面不是说到那个 Acknowledgment 吗?当 ACK 这个 Flag 为 1 时,表示这个封包的 Acknowledge Number 是有效的,也就是我们上面提到的那个回应封包咯。
- Push function:如果 PSH 为 1 的时候,该封包连同传送缓冲区的其它封包应立即进行传送,而无需等待缓冲区满了才送。接收端必须尽快将此数据交给程序处理。
- Reset:如果 RST 为 1 的时候,表示联机会被马上结束,而无需等待终止确认手续。
- Synchronize sequence number:这就是 SYN 标志啦!当 SYN 为 1 时,那就表示发送端要求双方进行同步处理,也就是要求建立联机的意思,这个 SYN 是相当重要的一个 Flag 喔!
- No more data fro sender (Finish):如果封包的 FIN 为 1 的时候,就表示传送结束,然后双方发出结束响应,进而正式进入 TCP 传送的终止流程。
-
Window (滑动窗口):与接收者的缓冲区大小有关的一个参数。
-
Checksum(确认):当数据要由发送端送出前,会进行一个检验的动作,并将该动作的检验值标注在这个字段上;而接收者收到这个封包之后,会再次的对封包进行验证,并且比对原发送的
Checksum 值是否相符,如果相符就接受,若不符就会假设该封包已经损毁,进而要求对方重新发送此封包!
-
Urgent Pointer:指示紧急数据所在位置的字段。
- Option:当需要 client 与 Server 同步动作的程序,例如 Telnet ,那么要处理好两端的交互模式,就会用到这个字段来指定数据封包的大小咯,不过,这个字段还是比较少用的!
在 TCP/IP 这个协议组合当中,TCP ( Transmission Control Protocol )就是用来做为传送的一个协议,当然啦,还有一个 UDP 的协定呢!在 TCP 这个协议当中,他提供了较为稳定而且可靠的联机状态,至于 UDP 则是一个比较没有这么可靠的联机型态了。底下我们就来谈一谈吧!
通讯端口口与 Socket pair
在开始说明 TCP 封包之前,我们先来了解一些常见的信息吧!首先提到的是通讯端口口 ( Port )这个玩意儿。通讯端口口的产生都是来自于操作系统的某些程序 ( 您也可以想成是程序, process ) 的执行结果。举例来说,当我们想要连上奇摩雅虎这个网站来浏览 WWW 的信息时,那么我们的浏览器 (Netscap 还是 IE 都好啦! ) 就需要在我们的计算机上面随机开启一个大于 1024 以上的通讯端口口来进行该次的联机,当然啦,在奇摩雅虎的 WWW 主机上面,因为要启动 WWW 的服务,不然怎么让 Client 端连进来?所以,他就会启动 WWW 服务器软件,而这个 WWW 服务器软件就会在奇摩雅虎的主机上面开启一个端口口来等待 Client 端的连接,这个埠口此时就称为在监听 ( LISTEN )了!而当两个埠口连接上并且正确的建立起联机之后,那么资料就可以开始在这两个埠口之间进行传送了!
或许您会觉得很奇怪,怎么上面提到的在 Client 端的埠口需要随机选取一个大于 1024 以上的埠口来进行这次的联机呢?这是因为小于 1023 以内的埠口大多已经预留给特殊的服务 ( Services ) 来进行该服务的启动了,例如上面提到的 WWW 服务器,预设的监听埠口就是 80 这个埠号。目前有相当多的常见 ( Well Known ) 的端口口就是保留给系统特定的服务器软件用的,而这些埠号与服务的名称对应在 Linux 系统当中,都是写在/etc/services里面,底下列出一些常见的 Services 与埠号的对应:
另外一点比较值得注意的是,小于 1023 以下的埠口要启动时,启动者的身份必须要是 root 才行!这个限制挺重要的,大家不要忘记了喔!
|
曾经有一个朋友问过我说:『一部主机上面这么多服务,那我们跟这部主机进行联机时,该主机怎么知道我们要的数据是
WWW 还是 FTP 啊?!』呵呵!这就是 port 的不同的结果啦!因为每种 Client 软件他们所需要的数据都不相同,例如上面提到的 Netscape
以及 IE 他们所需要的数据是 WWW ,所以该软件预设就会向主机的 80 port 索求数据;而如果您是使用 cuteftp 来进行与主机的 FTP
数据索求时, cuteftp 这个 Client 软件当然预设就是向主机的 FTP 相关埠口 ( 预设就是 port 21 )
进行连接的动作啦!所以当然就可以正确无误的取得 Client 端所需要的数据了。 举个例子来说,一部主机就好像是一间多功能银行,该银行内的每个负责不同业务的窗口就好像是通讯端口口,而我们民众就好像是 Client 端来的封包。当您进入银行想要缴纳信用卡账单时,一到门口服务人员就会指示您直接到该窗口去缴纳,当然,如果您是要领钱,服务人员就会请您到领钱的窗口去填写数据,您是不会跑错的对吧! ^_^。万一跑错了怎么办?呵呵!当然该窗口就会告诉您『我不负责这个业务,您请回去!』,呵呵!所以该次的联机就会『无法成功』咯! |
谈过了通讯端口口后,再来聊一聊每个封包的基本内容有哪些数据呢?这就得要谈论到Socket Pair ( 成对的承口 )了!当本机发送出封包时,主机是根据 IP 来判别来源与目的地的行进路线,并且,也需要 port number 来告知 Client 与 Server 是以哪一个埠口来进行联机的对吧!所以呢,一个联机封包就必须至少会包含底下四个信息:
这四个封包的基本信息是相当重要的!您得必须要了解喔!
封包的传送
知道了几个重要的端口口与相关的信息后,先来了解一下什么是封包呢?封包上面有哪些信息呢?其实封包就很像我们在邮寄信件的时候那个邮件的模样了!信纸总是得放入信封吧?而信封上面总是得写上发信人住址,受信人住址与姓名啊!所以,一封邮件主要会有两个部分,分别是:『信封表面的信息部分、与信封内部的信件内容!』。同样的,网络的信息封包主要也是分为两个部分,一个是表头 ( Header ) 的部分,另一个则是内容 ( messages ) 的部分啦!而一个封包要传送到哪里去,都是藉由 Header 的讯息部分来进行分析而传送的啦!那么 Header 有哪些重要的信息呢?主要就如同上面提到的,至少会有来源与目标 IP 、来源与目标 Port等等!
好了,假设因特网与您的主机网络的设定都没有问题了,也解决了路由的问题了,那么请问真正的封包是怎么在两部主机之间进行传送的呢?事实上,封包的传送是相当复杂的,而且封包的状态不同 (TCP/UDP) 也会有不一样的传送机制。这里我们仅举一个『相对比较可靠的封包传送方式』来介绍。如下图所示:
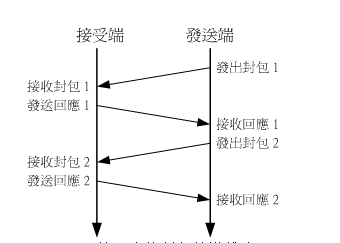
图五、较可靠的封包传送状态 当发送封包者发送出一个封包给接受者后,接受者在『正确的接到』这个封包之后,会回复一个响应封包 ( Acknowledgment ) 给发送者,告诉他接受者已经收到了!当发送端收到这个响应封包后,才会继续发送下一个封包出去,否则就会将刚刚的封包重新发送一次!这种封包的传递方式因为考虑到对方接到的封包的状态,所以算是比较可靠的一种方式。目前因特网上面常见的封包是 TCP 与 UDP ,其中 TCP 的联机方式中,会考虑到较多的参数,他是一种联机模式(Connection Oriented)的可靠传输,至于 UDP 则省略了图五当中那个响应封包的步骤,所以是一种非联机导向的非可靠传输。在一个 TCP 封包的传送过程中,因为至少需要传送与响应等封包来确定传送出去的数据没有问题,所以他是相当可靠的一种传输方式,不过就是传输与响应之间的时间可能会拖比较久一点。至于 UDP 封包就因为少了那个确认的动作,所以虽然他是较不可靠一点,但是速度上就比 TCP 封包要来的快了!底下我们将继续介绍 TCP, UDP 以及 ICMP 等封包信息的内容喔!
TCP, 三向交握,
好了,了解了联机步骤之后,也知道 TCP 与 UDP 封包的建立是有差异存在的!在这个小节当中,我们先就 TCP 封包 Header 的内容作个简单的介绍吧! TCP 封包的 Header 内容主要如下:
表二、TCP 封包的 Header 信息
| Source Port(16) | Destination Port(16) | |||||||
| Sequence Number(32) | ||||||||
| Acknowledgment Number(32) | ||||||||
| Data Offset(4) | Reserved(6) |
U G R |
A C K |
P S H |
R S T |
S Y N |
F I N |
Window(16) |
| Checksum(16) | Urgent Pointer(16) | |||||||
| Options | ||||||||
|
Data ...... Message |
上面的信息都相当的重要,稍微了解一下各个数据:
了解了 TCP 封包的格式之后,再来我们谈一谈里面几个重要的信息吧!事实上,TCP 之所以被称为联机导向的可靠传输,其实是靠上面提到的 Control Flag 来控制封包的旗标,以使 Client 与 Server 端建立起联机的机制。以下图为例:
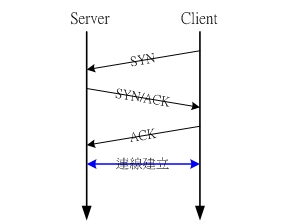
图六、TCP 封包的三向交握 在上图中,SYN 与 ACK 就是 Control Flag 的开关来让 TCP 封包含有的相关信息!Client 端与 Server 端在经过了要求主动建立、回复确认封包、再次确认,最后建立起两边的相关埠口的联机,由于为了建立起最终的联机,需要进行三次封包的要求与确认,因此我们也称这个建立联机前的步骤为『三向交握, Three-way handshake』了。这个动作在建立联机以及防火墙的设定里面是相当重要的喔!
UDP
UDP 的全名是:『User Datagram Protocol, 用户数据流协议』,UDP 与 TCP 不一样, UDP 不提供可靠的传输模式,因为他不是联机导向的一个机制,这是因为在 UDP 的传送过程中,例如图五当中,接受端在接受到封包之后,不会回复响应封包 ( ACK ) 给发送端,所以封包并没有像 TCP 封包有较为严密的验证机制。至于 UDP 的表头资料如下表所示:
表三、UDP 封包的 Header 信息
| UDP Source Port(16) | UDP Destination Port(16) |
| Message Length(16) | UDP checksum(16) |
|
Data ...... Message |
如上所示,UDP 封包仅提供 UDP 使用的埠口(port),表头所占用的信息要比 TCP 少很多,由于每个封包的大小是有限制的,所以一个 UDP 封包,基本上来说,他所能容纳的数据 (Data/Message) 就会比 TCP 封包来的多一些。此外,由于 UDP 封包不需要等待响应封包 (ACK) ,所以传输速度上比较快一点。快虽快,毕竟 UDP 封包比较不够可靠,因此他适用于可靠性要求不高的场合,比如等一下要谈的 DNS 传送当中。
TCP 与 UDP 在传输可靠性、传输量以及传输速度上是各有其优缺点的,所以各有其适用的场合!
ICMP
ICMP 的全称是『Internet Control Message Protocol』。基本上,ICMP 是一个错误侦测与回报的机制,最大的功能就是可以确保我们网络的联机状态,与联机的正确性!不过 ICMP 本身并没有传送的能力,需要藉由 IP 来进行传送。ICMP 有相当多的类别可以侦测与回报,底下是比较常见的几个 ICMP 的类别 (Type):
表四、ICMP 的各项类别所代表的意义
| 类别代号 | 类别名称 | 意义 |
| 0 | Echo Reply | 代表一个响应信息 |
| 3 | Distination Unreachable | 表示目的地不可到达 |
| 4 | Source Quench | 当 router 的负载过时,这个类别码可以用来让发送端停止继续发送讯息 |
| 5 | Redirect | 用来重新导向路由路径的信息 |
| 8 | Echo Request | 请求响应讯息 |
| 11 | Time Exeeded for a Datagram | 当数据封包在某些路由传送的现象中造成逾时状态,此类别码可告知来源该封包已被忽略的讯息 |
| 12 | Parameter Problem on a Datagram | 当一个 ICMP 封包重复之前的错误时,会回复来源主机关于参数错误的讯息 |
| 13 | Timestamp Request | 要求对方送出时间讯息,用以计算路由时间的差异,以满足同步性协议的要求 |
| 14 | Timestamp Replay | 此讯息纯粹是响应 Timestamp Request 用的 |
| 15 | Information Request | 在 RARP 协议应用之前,此讯息是用来在开机时取得网络信息 |
| 16 | Information Reply | 用以响应 Infromation Request 讯息 |
| 17 | Address Mask Request | 这讯息是用来查询子网络 mask 设定信息 |
| 18 | Address Mask Reply | 响应子网络 mask 查询讯息的 |
在 ICMP 的应用当中,比较有名的就是 ping 与 traceroute 了,这两个指令可以用来让我们检查整个网络的问题点呢!关于指令的详细用法,我们在后面章节的『Linux 网络常用指令』当中再继续的介绍。
封包过滤的防火墙概念
由上面的说明当中,我们知道数据的传送其实就是封包的发出与接受的动作啦!并且不同的封包上面都有不一样的表头 ( header ),此外,封包上面通常都会具有四个基本的信息,那就是 socket pair 里面提到的『来源与目的的 IP 以及来源与目的端的 port number』 。当然啦,如果是可靠性联机的 TCP 封包,还包含 Control Flag 里面的 SYN/ACK 等等重要的信息呢!好了,开始动一动脑筋,有没有想到『网络防火墙』的字眼啊?!网络防火墙可以抵挡掉一些可能有问题的封包,那么在 Linux 系统上面是怎么挡掉封包的呢?其实说来也是很简单,既然封包的表头上面已经有这么多的重要信息,那么我就利用一些防火墙机制与软件来进行封包表头的分析,并且设定分析的规则,当发现某些特定的 IP 、特定的埠口或者是特定的封包信息(SYN/ACK等等),那么就将该封包给他丢弃,那就是最基本的防火墙原理了!
举例来说,大家都知道 Telnet 这个服务器是挺危险的,而 Telnet 使用的 port number 为 23 ,所以,当我们使用软件去分析要送进我们主机的封包时,只要发现该封包的目的地是我们主机的 port 23 ,就将该封包丢掉去!那就是最基本的防火墙案例啦!更多的防火墙信息我们会在后头的『简易防火墙』与『认识网络安全』当中进行更多的说明喔!
DNS 的基础观念
除了上面提到的最基本的网络基础概念之外,这里还必须要先谈一个基本的观念,否则后续的主机名称查询设定挺难说明白的!好了,我们知道计算机在网络上面要找寻主机的时后,是利用 IP 来寻址,而以 TCP/UDP/ICMP 等数据来进行传送的,并且传送的过程中还会去检验封包的信息。总归一句话,网络是靠 TCP/IP 家族来达成的,所以必须要知道 IP 之后,计算机才能够连上网络以及传送数据。
问题是,计算机网络是依据人类的需要来建立的,不过人类对于 IP 这一类的数字并不具有敏感性,即使 IP 已经被简化为十进制了,但是人类就是对数字没有办法啊!怎么办?!没关系,反正计算机都有主机名称嘛!那么我就将主机名称与他的 IP 对应起来,未来要连接上该计算机时,只要知道该计算机的主机名称就好了,因为 IP 已经对应到主机名称了嘛!所以人类也容易记忆文字类的主机名称,计算机也可以藉由对应来找到他必须要知道的 IP ,啊!真是皆大欢喜啊!
这个主机名称 (Hostname) 对应 IP 的系统,就是鼎鼎有名的Domain Name System (DNS)咯!也就是说, DNS 这个服务的最大功能就是在进行『主机名称与该主机的 IP 的对应』的一项协定。DNS 在网络环境当中是相当常被使用到的一项协议喔!举个例子来说,像鸟哥我常常会连到奇摩雅虎的 WWW 网站去看最新的新闻,那么我一定需要将奇摩雅虎的 WWW 网站的 IP 背下来吗?!天吶,鸟哥的忘性这么好,怎么可能将 IP 背下来?!不过,如果是要将奇摩站的主机名称背下来的话,那就容易的多了!不就是 http://tw.yahoo.com 吗?!而既然计算机主机只认识 IP 而已,因此当我在浏览器上面输入了『http://tw.yahoo.com』的时后,我的计算机首先就会藉由向 DNS 主机查询 tw.yahoo.com 的 IP 后,再将查询到的 IP 结果回应给我的浏览器,那么我的浏览器就可以藉由该 IP 来连接上主机啦!
发现了吗?我的计算机必须要向 DNS 主机查询 Hostname 对应 IP 的信息喔!那么那部 DNS 主机的 IP 就必须要在我的计算机里面设定好才行,并且必须要是输入 IP 喔,不然我的计算机怎么连到 DNS 主机去要求数据呢?呵呵!在 Linux 里面,DNS 主机 IP 的设定就是在 /etc/resolv.conf 这个档案里面啦!
目前各大 ISP 都有提供他们的 DNS 主机 IP 给他们的用户,好设定客户自己计算机的 DNS 查询主机,不过,如果您忘记了或者是您使用的环境中并没有提供 DNS 主机呢?呵呵!没有关系,那就设定中华电信那个最大的 DNS 主机吧! IP 是 168.95.1.1 咯!要设定好 DNS 之后,未来上网浏览时,才能使用主机名称喔!不然就得一定需要使用 IP 才能上网呢!DNS 是很重要的,他的原理也顶复杂的,更详细的原理我们在后面的『DNS 服务器架设』里面进行更多更详细的说明喔!这里仅提个大纲!
网络布线模式:
-
呀!真累人的网络基础啊!谈完了一些基本的观念之后,接着下来就是实作的部分啰!首先,要让网络能通,自然就需要将所有的计算机以『网络的联机媒体』连接起来,这里指的媒体就是『网络线、集线器或交换器( Hub
或 Switch )、网络卡』等等的硬件配备啦!当然啦,由于选择的媒体不同,布线情况也会有所差异!这里 VBird
以目前最常见于一般小型企业或家庭 LAN 里面的布线『星形联机』来进行说明。这种架构基本上『就是以一个 Hub 或者是 Switch
为中心,进而将所有的计算机连接起来』,以提供各个计算机的网络功能!这种架构的最大优点在于除错较容易!我们底下列出一个很简单的家庭星形架构的联机:
- Host ( 主机 ):只要是连接在网络上面的主要设备,几乎都可以称为主机 (HOST) 。例如服务器 (server), 路由器 ( Router ), 网络打印机, 终端机以及工作站, 还有其它相关的联机控制器材等等,都可以被称为是 Host 哩。
-
Node ( 节点 ):连接在网络上的所有非网络线部分的设备,都可以称为节点,例如上面图七的 PC, ISP 主机,调制解调器, 交换器,
等等,全部都算是 node 喔!当我们要成功的完成 client 与 Server 的联机时,那么在这条联机上的所有 node
都必须没有问题才行!例如交换器要能正确的工作,Server 要能提供正常的服务等等。当我们在进行网络除错时,就是由一个一个的 Node
来着手测试的!
- Client ( 客户端 ):向服务器发送出数据索求封包的 host 就可以称为是 Client 了!举例来说,当 Linux PC 3 向其它服务器要求数据时,那么这部计算机就是 client 啦!而当 Linux NAT 服务器,向 ISP 大型主机要求数据时,在当时的行为他也算是 Client 喔!所以他的身份是很复杂的,不但提供 Client 服务,同时如果他向其它主机要求数据,他就成为 Client 咯!
- Interface ( 网络接口 ):网络接口不一定是网络卡喔!举例来说,当我们使用 ADSL 拨接到 ISP 后,会取得一个额外的网络接口 ( ppp0 ),该接口实际上是没有硬件的 ( 其实是架构在网络卡上面的啦! ),此外,如果架设一个网络卡多个 IP 的设定时 ( IP aliases ),也会在一张网络卡上面产生多个网络接口的喔!
-
Network adapter, Network Interface Card, NIC ( 网络卡
):呵呵!这个指的就是实际的硬件咯!
-
Server ( 服务器 ):当主机有对网络提供服务时,例如 WWW, FTP... ,那么该 host 就可以称为 Server 了!
- Workstation ( 工作站 ):简单的来说,只要没有对网络提供服务的,就可以称为工作站了!例如 Windows PC1, Windows PC2...,不过,事实上工作站对于某些环境来说,还是有差别的。例如某些提供很强大的运算能力的主机,偶而也会被称为『工作站』,实时他仍然有提供网络服务!
-
Linux 核心必须有支持网络卡:
我们在之前的『鸟哥的 Linux 私房菜 -- 基础学习篇』提过了,要让硬件正确无误的工作,您的核心 (Kernel) 就必须要支持该硬件才行,也就是说,需要硬件的驱动程序啦!所以啰,请先确定您购买的网络卡是被 Linux 所支持的,不然的话,您就得向厂商要求驱动程序,然后在自己的 Linux 系统上面编译好才行!
-
网络卡必须具有合法的 IP 以及正确的网络参数设定:
再来,由于我们目前的网络基础是由IP ( Internet Protocol )进行沟通的 ( 由于这个 IP 是经由操作系统的软件给的,所以又称为软件地址( software address ),而由前面的基础介绍后,我们也知道要成功的连上网络,就需要五个主要的参数才行:IP, Network, Netmask, Broadcast, Gateway,这些数据都必须要能正确的设定在您的系统上;
-
数据封包的传送:
嗯!终于连上网络了,不过要能真正的传输数据得需要了解到刚刚上面才提到的『封包格式』内容啦!封包的传送需要将正确的联机建立起来,而联机的建立与 Socket pair 有关,所以我们必须在 Client 端安装正确的 Client 软件,如果是 Server 的话,就得要启动正确的服务,以开启所需要的联机埠口,以用来建立联机并且进行数据的传输啰!
-
经过节点、 Router 或 Gateway 主机:
好了,由于我们是经由 Hub/Switch 进行连接的,所以我们的封包数据一定会经过这个节点才会传送出去!这个时候不禁要想一想, Hub 好还是 Switch 好?这两者有什么不同呢?其实最大的不同来自于『共享网络媒体』与『网络媒体对应』的架构上面!然后由于封包本身记录的 socket pair 让我们的封包就可以藉由一个又一个的 router 传送到目的地!
- 操作系统先依据软件给的 IP 来将数据打包成为待传送的封包,例如 TCP 封包,上面并记录了来源与目的的 IP 与 port;
- 根据封包上面的目的地 IP 资料,并经由 本机上面的 route table 来取得下一个 router 的信息( 若在同一网域内,则 router 可视为本机的网络卡 ),然后将数据送到 router 上面去;
- 重复 router 的行为,最后送到目的地端的 PC,而对方主机接收您的 TCP 封包!
图七、星形网络联机的概要

基本组件:
在图七里面,有哪些基本的网络组件呢?我们先来谈一谈定义吧! ^_^
联机基本要求
好了,如果硬件联机都已经建立了起来,那么我的计算机要经过 Internet 联机到远程的主机时,至少需要哪些正确的网络设定之后,才能够进行联机呢?之前的几个小节都是提到网络基础的设定,这里要稍微介绍的则是主机设定时需要注意的事项:
TCP程序设计:
在看了鸟个的私房菜服务器篇里介绍网络部分,也算是对一些概念有了那么点认识。试着编写一个小程序,完成客户端向服务器端发送数据。
总的来说网络程序是由两个部分组成的--客户端和服务器端.它们的建立步骤一般是:
服务器端
socket-->bind-->listen-->accept
客户端
socket-->connect
可以通过man命令来查看几个函数的用法,以socket为例:
liklon@liklon-laptop:~$ man socket liklon@liklon-laptop:~$
 其他的函数均可以这样查找。
其他的函数均可以这样查找。
(一)socket
int socket(int domain, int type,int protocol)
domain:说明我们网络程序所在的主机采用的通讯协族(AF_UNIX和AF_INET等).
AF_UNIX只能够用于单一的Unix 系统进程间通信,
而AF_INET是针对Internet的,因而可以允许在远程
主机之间通信(当我们 man socket时发现 domain可选项是 PF_*而不是AF_*,因为glibc是posix的实现所以用PF代替了AF,
不过我们都可以使用的).
type:我们网络程序所采用的通讯协议(SOCK_STREAM,SOCK_DGRAM等)
SOCK_STREAM表明我们用的是TCP 协议,这样会提供按顺序的,可靠,双向,面向连接的比特流.
SOCK_DGRAM 表明我们用的是UDP协议,这样只会提供定长的,不可靠,无连接的通信.
protocol:由于我们指定了type,所以这个地方我们一般只要用0来代替就可以了 socket为网络通讯做基本的准备.
成功时返回文件描述符,失败时返回-1,看errno可知道出错的详细情况.
(二)bind
int bind(int sockfd, struct sockaddr *my_addr, int addrlen)
sockfd:是由socket调用返回的文件描述符.
addrlen:是sockaddr结构的长度.
my_addr:是一个指向sockaddr的指针. 在中有 sockaddr的定义
struct sockaddr{
unisgned short as_family;
char sa_data[14];
};
不过由于系统的兼容性,我们一般不用这个头文件,而使用另外一个结构(struct sockaddr_in) 来代替.在中有sockaddr_in的定义
struct sockaddr_in{
unsigned short sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;
unsigned char sin_zero[8];
}
我们主要使用Internet所以
sin_family一般为AF_INET,
sin_addr设置为INADDR_ANY表示可以和任何的主机通信,
sin_port是我们要监听的端口号.sin_zero[8]是用来填充的.
bind将本地的端口同socket返回的文件描述符捆绑在一起.成功是返回0,失败的情况和socket一样
(三)listen
int listen(int sockfd,int backlog)
sockfd:是bind后的文件描述符.
backlog:设置请求排队的最大长度.当有多个客户端程序和服务端相连时, 使用这个表示可以介绍的排队长度.
listen函数将bind的文件描述符变为监听套接字.返回的情况和bind一样.
(四)accept
int accept(int sockfd, struct sockaddr *addr,int *addrlen)
sockfd:是listen后的文件描述符.
addr,addrlen是用来给客户端的程序填写的,服务器端只要传递指针就可以了. bind,listen和accept是服务器端用的函数,
accept调用时,服务器端的程序会一直阻塞到有一个 客户程序发出了连接. accept成功时返回最后的服务器端的文件描述符,
这个时候服务器端可以向该描述符写信息了. 失败时返回-1
(五)connect
int connect(int sockfd, struct sockaddr * serv_addr,int addrlen)
sockfd:socket返回的文件描述符.
serv_addr:储存了服务器端的连接信息.其中sin_add是服务端的地址
addrlen:serv_addr的长度
connect函数是客户端用来同服务端连接的.成功时返回0,sockfd是同服务端通讯的文件描述符 失败时返回-1.
服务器端程序:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <netdb.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
//int socket(int domain, int type, int protocol);
//int bind(int sockfd, const struct sockaddr *addr,
// socklen_t addrlen);
#define PORT 2222
int main(int argc,char **argv){
int socketfd,newsockfd;
socklen_t len_addr;
struct sockaddr_in server_addr;
struct sockaddr_in client_addr;
int rByte;
char buf[1024];
/*创建套接字,获取socketfd描述符*/
if((socketfd = socket(AF_INET,SOCK_STREAM,0)) < 0){
perror("socket error\n");
exit(1);
}
bzero(&server_addr,sizeof(struct sockaddr_in)); //清0
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
//绑定socketfd到IP地址
if(bind(socketfd,(struct sockaddr*)(&server_addr),sizeof(struct sockaddr)) < 0){
perror("bind error\n");
exit(1);
}
//监听
if(listen(socketfd,10) < 0){
perror("listen error\n");
exit(1);
}
// int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
while(1){
len_addr = sizeof(struct sockaddr_in); //等待连接
if((newsockfd = accept(socketfd,(struct sockaddr *)(&client_addr),&len_addr)) < 0){
perror("accept error\n");
exit(1);
}
fprintf(stderr,"server connect from %s\n",inet_ntoa(client_addr.sin_addr));
if((rByte = read(newsockfd,buf,1024)) < 0){
perror("read error\n");
exit(1);
}
buf[rByte] = '\0';
printf("%s\n",buf);
close(newsockfd);
}
}
客户端程序:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <netdb.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define PORT 2222
int main(int argc,char **argv){
int sockfd;
struct sockaddr_in server_addr;
struct hostent *host;
char buf[1024] = "eepw-->liklon";
if(argc != 2){
printf("please enter xxx xxx\n");
exit(1);
}
//struct hostent *gethostbyname(const char *name);
if((host = gethostbyname(argv[1])) == NULL){
perror("gethostbyname error\n");
exit(1);
}
/*创建套接字,获取socketfd描述符*/
if((sockfd = socket(AF_INET,SOCK_STREAM,0)) < 0){
perror("socket error\n");
exit(1);
}
bzero(&server_addr,sizeof(struct sockaddr_in)); //清0
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr = *((struct in_addr*)(host->h_addr));
if(connect(sockfd,(struct sockaddr *)(&server_addr),sizeof(struct sockaddr))==-1){
perror("Connect Error");
exit(1);
}
write(sockfd,buf,14);
close(sockfd);
}
效果图:

回复
| 有奖活动 | |
|---|---|
| 硬核工程师专属补给计划——填盲盒 | |
| “我踩过的那些坑”主题活动——第002期 | |
| 【EEPW电子工程师创研计划】技术变现通道已开启~ | |
| 发原创文章 【每月瓜分千元赏金 凭实力攒钱买好礼~】 | |
| 【EEPW在线】E起听工程师的声音! | |
| 高校联络员开始招募啦!有惊喜!! | |
| 【工程师专属福利】每天30秒,积分轻松拿!EEPW宠粉打卡计划启动! | |
| 送您一块开发板,2025年“我要开发板活动”又开始了! | |
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

