
二十、线程同步--条件变量
条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起使用。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其它的某个线程改变了条件变量,它将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。一般说来,条件变量被用来进行线承间的同步。
1.条件变量的结构为pthread_cond_t
2.条件变量的初始化
int pthread_cond_init ((pthread_cond_t *__cond,__const pthread_condattr_t *__cond_attr));
其中cond是一个指向结构pthread_cond_t的指针,cond_attr是一个指向结构pthread_condattr_t的指针。结构pthread_condattr_t是条件变量的属性结构,和互斥锁一样我们可以用它来设置条件变量是进程内可用还是进程间可用,默认值是PTHREAD_ PROCESS_PRIVATE,即此条件变量被同一进程内的各个线程使用。注意初始化条件变量只有未被使用时才能重新初始化或被释放。
3.条件变量的释放
释放一个条件变量的函数为pthread_cond_ destroy(pthread_cond_t cond)
4.条件变量的等待
(1)函数pthread_cond_wait()使线程阻塞在一个条件变量上。它的函数原型为:
extern int pthread_cond_wait_P ((pthread_cond_t *__cond,pthread_mutex_t *__mutex));
线程解开mutex指向的锁并被条件变量cond阻塞。线程可以被函数pthread_cond_signal和函数pthread_cond_broadcast唤醒,但是要注意的是,条件变量只是起阻塞和唤醒线程的作用,具体的判断条件还需用户给出,例如一个变量是否为0等等,这一点我们从后面的例子中可以看到。线程被唤醒后,它将重新检查判断条件是否满足,如果还不满足,一般说来线程应该仍阻塞在这里,被等待被下一次唤醒。这个过程一般用while语句实现。
(2)另一个用来阻塞线程的函数是pthread_cond_timedwait(),它的原型为:
extern int pthread_cond_timedwait_P (pthread_cond_t *__cond,pthread_mutex_t *__mutex, __const struct timespec *__abstime);
它比函数pthread_cond_wait()多了一个时间参数,经历abstime段时间后,即使条件变量不满足,阻塞也被解除。
5.条件变量的解除改变
函数pthread_cond_signal()的原型为:
extern int pthread_cond_signal_P ((pthread_cond_t *__cond));
它用来释放被阻塞在条件变量cond上的一个线程。多个线程阻塞在此条件变量上时,哪一个线程被唤醒是由线程的调度策略 所决定的。要注意的是,必须用保护条件变量的互斥锁来保护这个函数,否则条件满足信号又可能在测试条件和调用pthread_cond_wait函数之间被发出,从而造成无限制的等待。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
/*
int pthread_numtex_init()
*/
pthread_mutex_t mutex;
pthread_cond_t cond_haha;
void *pthreadFunc(void *arg);
int main()
{
pthread_t pthread;
int count = 0;
int res;
void *pthreadResult;
res = pthread_mutex_init(&mutex,NULL);
if(res != 0)
{
perror("mutex inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_cond_init(&cond_haha,NULL);
if(res != 0)
{
perror("cond_haha inint error\n");
exit(EXIT_FAILURE);
}
res = pthread_create(&pthread,NULL,pthreadFunc,NULL); //创建线程
if(res != 0)
{
perror("pthread_create error\n");
exit(EXIT_FAILURE);
}
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
if(count == 5) pthread_cond_wait(&cond_haha,&mutex);
printf("-->eepw\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
printf("wait --> pthread finish\n");
res = pthread_join(pthread,&pthreadResult);
if(res != 0)
{
perror("pthread_join error\n");
exit(EXIT_FAILURE);
}
pthread_mutex_destroy(&mutex); //销毁信号量
pthread_cond_destroy(&cond_haha);
exit(EXIT_SUCCESS);
}
void *pthreadFunc(void *arg)
{
int count = 0;
while(count++ < 10)
{
pthread_mutex_lock(&mutex);
if(count == 5) pthread_cond_signal(&cond_haha);
printf("-->liklon\n");
pthread_mutex_unlock(&mutex);
sleep(1);
}
pthread_exit(NULL);
}

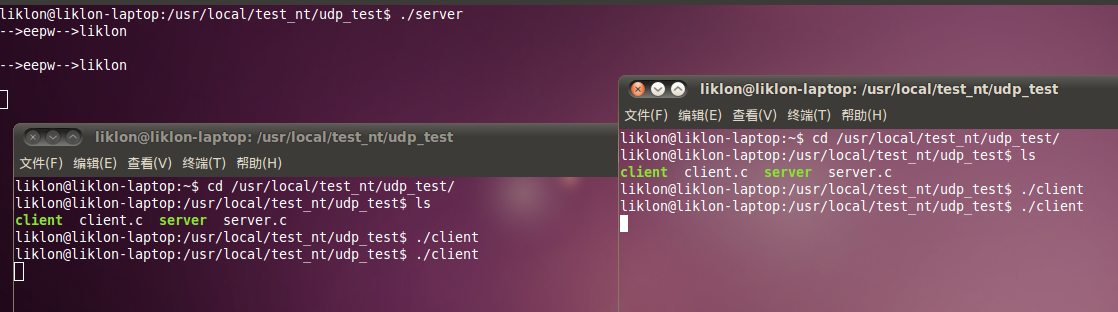
可以和上一段代码相互比较!!!



 其他的函数均可以这样查找。
其他的函数均可以这样查找。


 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

