图2 – CorePac 存储器增强
相应地,局域 L2 存储器是高达 1MB 的统一存储器(最初宣布推出的器件为 512KB 或 1MB)。此外,该存储器也可配置为全高速缓存、全存储器映射 SRAM(默认),或是 32、64、128、256 或 512KB 四路集关联高速缓存选项的组合。
至共享存储器子系统的存取路径经过精心的重新设计,能够显著降低至较高级存储器的时延,无论所有CorePac和数据 I/O 是否处于繁忙状态,均能维持相同的效率。
二级存储器效率 —— 与之前的系列产品相比,LL2 存储器器件和控制器的时钟运行速率更高。C66x LL2 存储器以等同于 CPU 时钟的时钟速率运行。更高的时钟频率可实现更快的访问时间,从而减少了因 L1 高速缓存失效造成的停滞,在此情况下必须从 LL2 高速缓存或 SRAM 获取存储器)。光这一项改进就自动使得从 C64X+ 或 C67X 器件进行应用升级实现了很大的速度提升,而且无需为 C66x 指令集进行重新编译。
此外,无论是对用户隐藏的还是由软件命令驱动的高速缓存一致性操作都会变得更高效,而且需要执行的周期数也更少。反之,这也意味着自动的高速缓存一致性操作(例如检测、数据移出)对处理器的干扰更小,因而停滞周期数也更少。手动的高速缓存一致性操作(例如全局或模块回写和/或无效)占用较少的周期即可完成,这就意味着在为共享存储器判优的过程中,实现CorePac 之间或 CorePac 与 DMA 主系统的同步将需要更短的等待时间。
共享存储器效率 —— 为进一步提高共享存储器的执行效率,在 CorePac 内置了扩展存储器控制器 (XMC)。对共享内部存储器 (SL2/SL3) 和外部存储器 (DDR3 SRAM) 来说,XMC 是通向 MSMC 的通道,且架构的构建基础实施在此前具有共享二级(SL2)存储器(比如TMS320C6472 DSP)的器件之上。
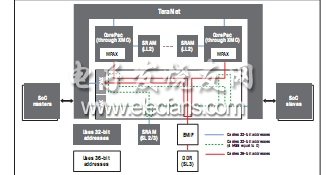
图 3 - 共享存储器架构
在以前具有 SL2 存储器的器件上,通向 SL2 的存取路径与通向 LL2的存取路径一样,在邻近内部接口处均有一个预取缓冲器。预取功能可隐藏对共享 RAM 库的访问时延,并可优化代码执行及对只读数据的存取(全面支持写操作)。XMC 虽然也遵循相同的目标,但是却进一步扩展添加了强大得多的预取功能,从而对程序执行和 R/W 数据获取提供了可与 LL2 相媲美的最佳性能。预取功能不仅能在访问存储器之前通过拉近存储器和 C66x DSP 内核之间的距离来降低存取时延,而且还能缓解其他 CorePac 和数据 I/O 通过 MSMC 争夺同一存储器资源的竞争局面。
MSMC 通过 256 位宽的总线与 XMC 相连,而 XMC 则可直接连接至用于内部 SL2/SL3 RAM 的 4 个宽 1024 位存储器组。内部存储器组使 XMC 中的预取逻辑功能能够在未来每次请求访问物理 RAM 之前获取程序和数据,从而避免后续访问停滞在 XMC。MSMC 可通过另一 256 位接口与外部存储器接口控制器直接相连,进一步将 CorePac 的高带宽接口一直扩展到外部存储器。
对于外部存储器而言,KeyStone架构可通过与共享内部存储器相同的通道进行访问,从而较之前的架构实现了显著的增强。该通道的宽度是之前器件的两倍,而速度则为一半,从而大幅降低了到达外部 DDR3 存储器控制器(通过 XMC 和 MSMC)的时延。在此前的 C6000 DSP 中以及众多的嵌入式处理器架构中,外部 CPU 和高速缓存访问是通过芯片级互连进行发布的,而 XMC 则可提供更为直接的最优通道。当从外部存储器执行程序时,其可大幅提高 L1/L2 高速缓存效率,并在多个内核与数据 I/O 对外部存储器并行判优时能够显著降低所带来的迟滞。
对于内部和外部存储器,所有的数据 I/O 流量都可通过多条直接通道进入 MSMC 到达芯片,而不是通过 CorePac 存储器控制器,从而在当数据 I/O 要访问 CorePacs 当前没有访问(例如,当 CorePac 从 SL2 执行,而数据 I/O往返于 DDR3 时)的存储器端点时,能使两者处于完全正交的状态;而且在 XMC 预取缓冲器后可提供判优以对 CorePacs 隐藏存储器组之间的冲突。
此外,XMC 还为数据和程序预取嵌入了多流预取缓冲器。程序预取缓冲器可为来自 L1P 和 L2 的读取请求提供服务,从而使其能够在 CPU 需要之前预取高达 128 字节的程序数据。数据预取缓冲器可为来自 L1D 和 L2 的读取请求提供服务。数据预取单元能够支持 8 个预取流,且每个流都能独立地从地址增加方向或地址减少方向预取数据。针对进入 DSP 内核的数据流,预取功能能够有助于减少强制失效损失。在多内核环境中,预取功能还能通过分散带宽峰值来提升性能。为在不增加负面影响的情况下利用预取实现性能提升,可在 16MB 范围内将存储器配置为启用或禁用预取属性。
外部存储器效率——除了将外部存储器连接到 MSMC 所带来的优势,KeyStone 外部存储器还包含了对外部存储器控制器 (EMIF) 的显著改进。KeyStone 架构能够以 1333MT/s以上的速率支持高性能 DDR3 SDRAM 存储器。虽然总线能配置成 16 或 32 位(为节省面板空间和功耗),但其实际支持的总线宽高达 64 位数据宽度。该架构相对于之前的架构具有更大的宽度以及更快的速度,从而允许集成多个更高性能的内核、加速器和数据 I/O。
高速缓存一致性控制——通常在多内核器件以及多器件系统内,数据作为处理的一部分在内核之间共享。KeyStone 架构可提供一些改进措施,以简化共享内部与外部存储器的一致性管理操作。
在 KeyStone 架构中,LL2 存储器始终与 L1D 高速缓存保持一致,所以不需要对一致性管理进行特殊的配置(虽然利用 L1D 一致性命令可实现一些性能优化)。SL2 和 SL3 这两种共享存储器不能由硬件来保障与 L1 和 L2 高速缓存的同步。因此需要软件控制往返于数据 I/O 页面的传输,以及对多内核之间共享缓冲器的访问。
为简化该过程,已将 fence 操作作为新的 MFENCE 指令添加到 CorePac 中。当与简单的 CPU 环路组合使用时,能将 MFENCE 用于实施 fence 操作,以保障读/写访问群组之间的序列一致性。能将其用于对可能从不同路径到达的特定端点的存储器请求进行同步。此外,对于多处理器算法,还可将其用于以特定顺序实现对存储器的存取,而这-顺序从所有 CPU 角度来看都一样。这可大幅简化共享数据段所需的一致性协议。
共享存储器保护与地址扩展 — C64x+ 和 C67x DSP 架构均将存储器保护作为内部存储器设计(L1、L2、SL2)的一部分。KeyStone 架构将存储器保护扩展至外部存储器,同时还增强了对内部存储器进行保护的灵活性。另外,MSMC 允许将外部存储器的地址空间从 32 位扩展至 36 位。
可为每个 C66x DSP 分配唯一的权限 ID (PrivlD) 值。可为数据 I/O 主系统分配一个 PrivID,EDMA 则例外,但它可以继承为每次传输进行配置的主系统的 PrivID 值。KeyStone 器件总共可支持 16 个 PrivID 值。存储器保护属性分别为管理员用户和普通用户分配了读/写/执行访问权限。
局域存储器的存储保护 —— C66x CorePac可提供由软件控制的请求者到存储器映射的灵活性,从而进一步扩展了此前 C6000 架构的存储器保护协议。所有存储器请求者(C66x CPU、EDMA、导航器、PCIe、SRIO 等)均拥有相关联的特权 ID。内部存储器控制器可以区分多达 6 个不同的请求者,并配置所有其他请求者。由于 KeyStone 器件集成了更多的内核以及更多的 DMA 主系统(I/O 和加速器),这一数目已不够用。KeyStone CorePac 允许将系统主控器的 ID 映射到保护逻辑中使用的 ID,以使应用能够获得量身打造的强大保护功能。

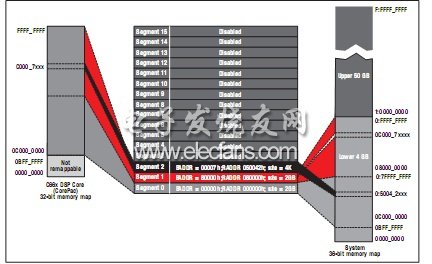
图 4 - 存储器保护属性
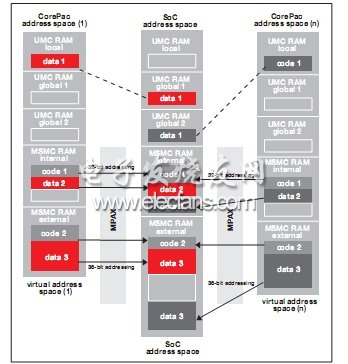
共享存储器的存储器保护 —— 共享存储器拥有多个存储器保护和地址扩展 (MPAX) 单元。C66x DSP 可通过 XMC 中的局域 MPAX 访问 MSMC 通道,而数据 I/O 则通过 MSMC 中的MPAX 逻辑访问 MSMC,并分别对内部共享存储器和外部存储器进行控制。
MPAX 单元将存储器保护和地址扩展结合成一步完成。正如对局域存储器的访问一样,MPAX 的运行基础为每个交易事务承载的特权 ID,用以代表存储器的请求者。对于每个 PrivID,相关联的 MPAX 单元在内部共享存储器和外部存储器中均支持最多 16 个存储段的定义。每个存储段均独立配置,并提供各自的存储器保护地址扩展属性。每个存储段的大小可以是2 的任意次方,范围介于 4KB 到 4GB 之间。地址扩展功能可将外部存储空间从 32 位地址扩展至 36 位。

 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

