
前言
在客户使用基于Cortex-M7内核的STM32F7xx实际测试中,发现同等主频下基于Cortex-M4内核的STM32F4xx芯片执行同样一段简单程序在时间上还要快于STM32F7xx。这个会影响到客户切换到STM32F7xx的信心,也对ST以及ARM宣传上Cortex-M7内核执行时间远快于Cortex-M4内核的说法提出质疑,本文将针对具体案例分析这一情况的产生以及解决办法。
问题描述
客户测试复杂程序运行时间,比如同样180MHz主频下,STM32F7xx执行Coremark测试程序时间远小于STM32F4xx的执行时间;也就是STM32F7xx的性能更佳,运算执行效率更好。但当客户顺序执行程序,尤其是简单程序时发现STM32F7xx执行时间大于STM32F4xx的执行时间,比如运行下面的同样的测试代码,就有明显差距:
volatile uint16_t i;
static volatile uint16_t j = 0;
i = 0;
while(i<300)
{
i++;
}
if(j < 100)
{
j ++;
}
else
{
j = 0;
}
为方便量化时间,使用Timer2计数方式对这段时间进行计数,Timer2运行在90MHz,向上计数,Test_Counter数据用于输出计数数值,增加后代码如下:
volatile uint16_t i;
static volatile uint16_t j = 0;
TIM2->CNT = 0;
__HAL_TIM_ENABLE(&htim2);
i = 0;
while(i<300)
{
i++;
}
if(j < 100)
{
j ++;
}
else
{
j = 0;
}
__HAL_TIM_DISABLE(&htim2);
Test_Counter = __HAL_TIM_GET_COUNTER(&htim2);
通过上面的修改后测试下来,Test_Counter数据分别为:
STM32F446 数据为 1543
STM32F746 数据为 1836
如果使用Keil自带的States cycles计算方法得到如下数据,后面会按照这个来计算执行时间数据。
STM32F446 数据为 3009
STM32F746 数据为 3635
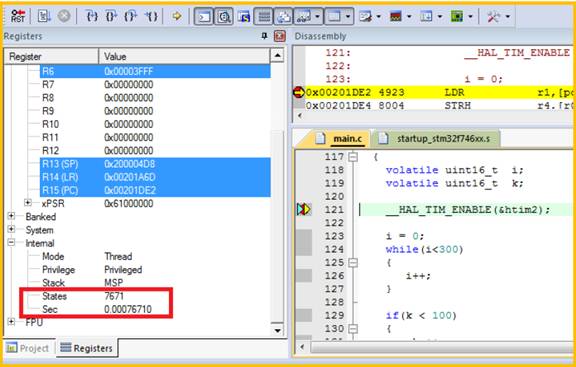
原因分析:
上面的测试都是在使用了Cache以及ART加速方法测得,如果针对STM32F7xx的性能优化可以参考AN4667 "STM32F7 Series systemarchitecture and performance"这篇应用文档的描述,本例已经对文档描述部分做过优化,但问题依然是STM32F7xx速度慢于STM32F4xx。两颗芯片运行同样代码,比较两颗芯片汇编代码也是相同的:
LDRH r2,[sp,#0x00]
ADDS r2,r2,#1
STRH r2,[sp,#0x00]
LDRH r2,[sp,#0x00]
CMP r2,r3
BCC 0x00000128
通过查看ARM Cortex-M7内核文档发现下面描述:

反映到本例中发现定义的i数据为16-bit数据,同样也在汇编代码上发现了STRB这个汇编代码;这样在RMW(read-modify-write)机制下,当定义为byte以及half-word数据时将有一个先读取数据,修改后再写入数据的过程,这个读取-修改-写入的过程正是能够影响到内核执行效率的问题点,如果定义为32-bit就避免了这个问题的发生。
问题解决:
按照文档说明,我们将16-bit定义数据,改为32-bit的定义数据,即:
volatile uint32_t i;
static volatile uint16_t j = 0;
生成的汇编代码如下:
LDR r0,[sp,#0x00]
ADDS r0,r0,#1
STR r0,[sp,#0x00]
CMP r0,r1
BCC 0x08001F28
测试下来结果如下:
STM32F446 数据为 2102
STM32F746 数据为 1807
可以看到不管是STM32F4xx还是STM32F7xx,当数据定义为32-bit时都有显著的速度提升,当然STM32F7xx的提升更加明显,同样测试条件下STM32F7xx执行时间小于STM32F4xx的执行时间。
因为32-bit数据定义会增加内存,并且有时候定义为byte或halfword更方便,还需要提升速度的话我们看到同样是内核文件给出的说明,可以将RMW机制屏蔽掉:
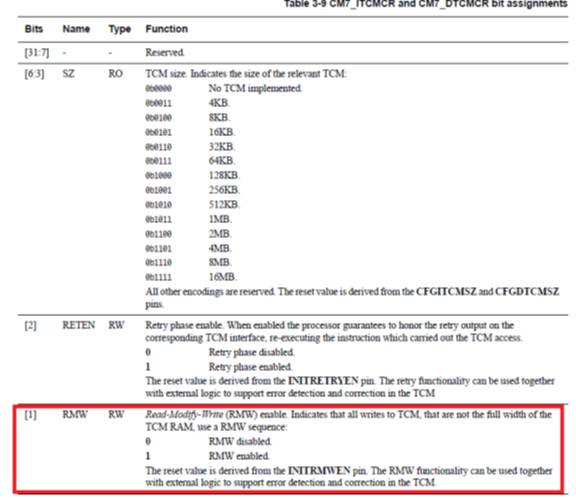
实际上就是对CM7_DTCMCR寄存器的第1位写0,即可以在程序中有下面的操作:
__IO uint32_t * DTCM_CR =(uint32_t*)(0xE000EF94);
* DTCM_CR &= 0xFFFFFFFD; /* Disable read-modify-write */
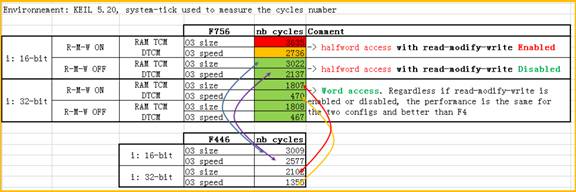
禁止RMW后测试下来数据如下:
16-bit定义数据STM32F746 测试cycles数据为 3022
32-bit定义数据STM32F746 测试cycles数据为 1808
可以对比上面的测试数据也可以看到当禁止RMW后STM32F7xx性能也是优于STM32F4xx的。具体测试数据如下:
结论:
需要提升STM32F7xx执行时间,发挥出最大效能时,请参考AN4667,同时需要注意RMW对内核性能发挥的影响。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

