
半导体厂商开发的硬件再怎么厉害,也需要软件工具的加持,重复制造轮子不是一个好主意,为了充分挖掘处理器的性能,各个厂家都发布了各种软件框架和工具,比如Intel的OpenVINO,Nvidia的TensorRT等等。
这里重点介绍英特尔发布的针对AI工作负载的一款部署神器--OpenVINO。
OpenVINO是英特尔推出的一款全面的工具套件,用于快速部署应用和解决方案,支持计算机视觉的CNN网络结构超过150余种。
我们有了各种开源框架,比如tensorflow,pytorch,mxnet,caffe2等,为什么还要推荐OpenVINO来作为部署工具呢?
当模型训练结束后,上线部署时,就会遇到各种问题,比如,模型性能是否满足线上要求,模型如何嵌入到原有工程系统,推理线程的并发路数是否满足,这些问题决定着投入产出比。只有深入且准确的理解深度学习框架,才能更好的完成这些任务,满足上线要求。实际情况是,新的算法模型和所用框架在不停的变化,这个时候恨不得工程师什么框架都熟练掌握,令人失望的是,这种人才目前是稀缺的。
OpenVINO是一个Pipeline工具集,同时可以兼容各种开源框架训练好的模型,拥有算法模型上线部署的各种能力,只要掌握了该工具,你可以轻松的将预训练模型在Intel的CPU上快速部署起来。
对于AI工作负载来说,OpenVINO提供了深度学习推理套件(DLDT),该套件可以将各种开源框架训练好的模型进行线上部署,除此之外,还包含了图片处理工具包OpenCV,视频处理工具包Media SDK。
在做推理的时候,大多数情况需要前处理和后处理,前处理如通道变换,取均值,归一化,Resize等,后处理是推理后,需要将检测框等特征叠加至原图等,都可以使用OpenVINO工具套件里的API接口完成。
对于算法工程师来说,OpenCV已经非常熟悉,这里重点讲一下深度学习部署套件DLDT。
DLDT分为两部分:
模型优化器(Model Optimizer)
推理引擎(Inference Engine)
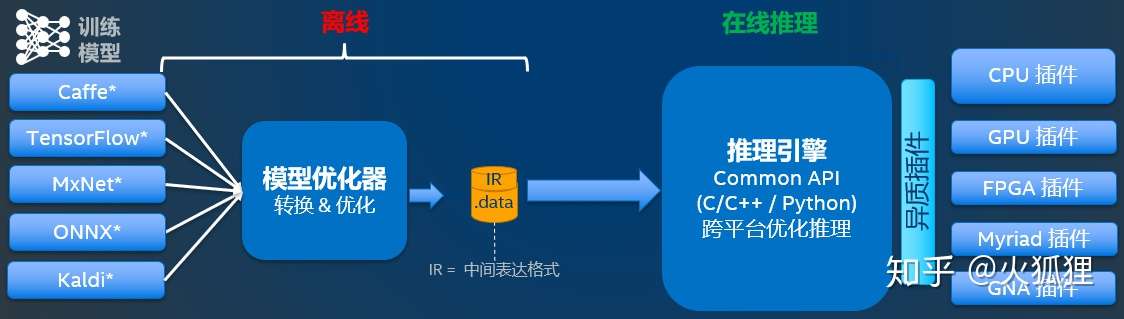
其中,模型优化器是线下模型转换,推理引擎是部署在设备上运行的AI负载。
模型优化器是一个python脚本工具,用于将开源框架训练好的模型转化为推理引擎可以识别的中间表达,其实就是两个文件,xml和bin文件,前者是网络结构的描述,后者是权重文件。模型优化器的作用包括压缩模型和加速,比如,去掉推理无用的操作(Dropout),层的融合(Conv + BN + Relu),以及内存优化。
推理引擎是一个支持C\C++和python的一套API接口,需要开发人员自己实现推理过程的开发,开发流程其实非常的简单,核心流程如下:
装载处理器的插件库
读取网络结构和权重
配置输入和输出参数
装载模型
创建推理请求
准备输入Data
推理
结果处理
下面给出一段C++的代码例子
// 创建推理core,管理处理器和插件InferenceEngine::Core core;// 读取网络结构和权重CNNNetReader network_reader;network_reader.ReadNetwork("Model.xml");network_reader.ReadWeights("Model.bin");// 配置输入输出参数auto network = network_reader.getNetwork();InferenceEngine::InputsDataMap input_info(network.getInputsInfo());InferenceEngine::OutputsDataMap output_info(network.getOutputsInfo());/** Iterating over all input info**/for (auto &item : input_info) {
auto input_data = item.second;
input_data->setPrecision(Precision::U8);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setResizeAlgorithm(RESIZE_BILINEAR);
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);}/** Iterating over all output info**/for (auto &item : output_info) {
auto output_data = item.second;
output_data->setPrecision(Precision::FP32);
output_data->setLayout(Layout::NC);}// 装载网络结构到设备auto executable_network = core.LoadNetwork(network, "CPU");std::map<std::string, std::string> config = {{ PluginConfigParams::KEY_PERF_COUNT, PluginConfigParams::YES }};auto executable_network = core.LoadNetwork(network, "CPU", config);// 创建推理请求auto infer_request = executable_network.CreateInferRequest();// 准备输入Dataor (auto & item : inputInfo) {
auto input_name = item->first;
/** Getting input blob **/
auto input = infer_request.GetBlob(input_name);
/** Fill input tensor with planes. First b channel, then g and r channels **/
...}// 推理sync_infer_request->Infer();// 结果处理for (auto &item : output_info) {
auto output_name = item.first;
auto output = infer_request.GetBlob(output_name);
{
auto const memLocker = output->cbuffer(); // use const memory locker // output_buffer is valid as long as the lifetime of memLocker const float *output_buffer = memLocker.as<const float *>();
// process result ...
}}推理过程只需要开发一次,只要模型的输入和输出不变,剩下的就是训练模型和模型优化工作了。
这是一款非常给力的专门做推理的工具,并且有intel在不停的开发和优化新的网络结构,有人维护和开发这件事很重要。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

