
缓存是我们项目应用肯定会使用,是我们数据库的守护神,能够保证数据库的稳定,能够提高整个系统的性能。一般我们采用市面上的redis、memcahce方案;redis已经非常强大了,每秒支持几万的连接时不成问题。
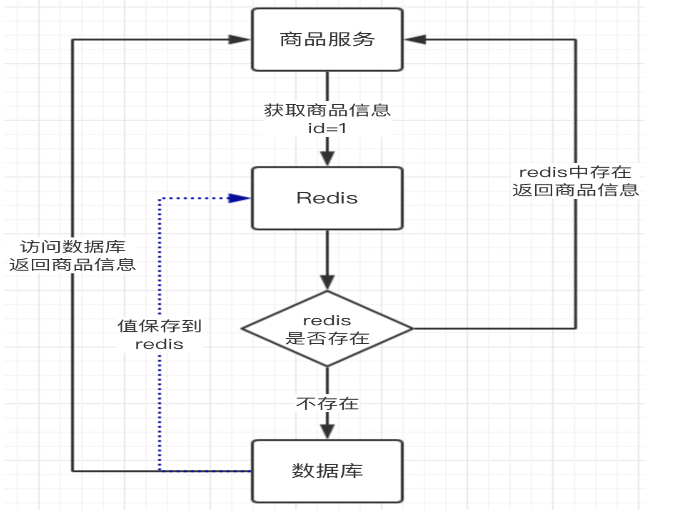
上图商品服务要获取商品信息时,先从redis缓存中获取,缓存中不存在再到数据库中取;数据库的资源时比较宝贵的,这样的设计就能把一些请求转移到redis上面去。这是我们小伙伴常用的缓存设计,绝大部分的缓存也就设计到此了。但只有这样的设计,真的我们就可以安枕无忧了吗?老顾带着大家了解一下雪崩,穿透,击穿的含义。
缓存雪崩
雪崩是指我们一般在设置缓存的时候都会设置一个缓存过期时间,如果一些缓存过期时间在同一刻,也就是缓存同时过期了。这个时候有大量请求过来,发现缓存中不存在,就直接到数据库中获取,就像雪崩一样同时打到数据库上面,这样就会导致数据库负载高,很有可能就会崩溃。
解决方案一:
发现缓存不存在,在读取数据库时,再保存到redis缓存中,采用队列的方式或加锁的方式,进行排队访问数据库,这样就能够避免同时打到数据库上。
解决方案二:
这个方案就比较简单,雪崩是因为过期时间在同一刻导致的,那我们就可以在设置过期时间分散开。如在原有的过期时间的基础上加上一个随机数,比如:1~10分钟,这样就不会放生在同一刻缓存失效了。
解决方案三:
设置二级缓存机制,这样就能够保证即时第一层缓存失效了,还有第二级缓存的保障;不过就增加了系统复杂性。
缓存穿透
穿透是指在查询一个不存在的数据,如商品id=10000,系统就不存在id为10000的数据。按照缓存设计的原理,缓存中找不到此商品,就会到数据库中查询,也没有找到。这样的请求都会打到数据库中,缓存在这个场景中就相当于没有。恶意的人利用这个漏洞发起攻击,直接把数据库搞崩溃。
解决方案一:
最常见的方法就是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的map中,一定不存在的数据会被这个map过滤掉,这样就避免了访问到数据库。
解决方案二:
就是把空值也缓存起来,如商品id=10000,数据库查询虽然没有找到,但会在redis中保存一个空值。这种方案就会碰到2个问题。
问题一:
空值做了缓存,这样就无形了增加了很多没有意义的缓存,内存吃紧。比较有效的方式就是在这些值上面设置一个过期时间,让起自动删除
问题二:
有可能与业务存在不一致的窗口时间,如:虽然商品ID=10000现在不存在,我们现在在redis中保存了一个空值,但业务后来就真的有了商品id为10000的数据,这样数据库和缓存的信息就不一致,导致业务出现问题。此时就可以利用消息中间件等方式系统剔除掉此缓存数据
缓存击穿
击穿是指某些数据被大量请求,也就是“热点”数据,一旦出现缓存过期时,就会有大量的请求打到后端的数据库,这样就会导致数据库崩溃
解决方案一:检测更新
最容易想到的是这些热点数据设置永不过期,就不存在此问题。这样就会出现一个问题,那缓存怎么去更新呢?
方法一:
可以做一个后台服务,专门用来做数据缓存的更新。每隔30分钟更新一下这些热点缓存数据。不过这样就增加了系统复杂度。
方法二:
方法一过于复杂,我们可以改造一下redis的缓存结构,在缓存业务数据的时候,再保存跟业务数据关联的过期时间key。每次请求过来时,判断一下此业务数据的是否要到过期时间了,如:此值还有1分钟就过期了,这样就服务本身主动去数据库查询一次,做一个缓存的更新。
解决方案二:分级缓存
分级缓存,可采用二级缓存的方式缓存此热点数据。
采用L1(一级缓存)和L2(二级缓存)缓存方式,L1缓存失效时间短,L2缓存失效时间长。请求优先从L1缓存获取数据,如果L1缓存未命中则加锁,只有1个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到L1缓存和L2缓存中,而其他线程依旧从L2缓存获取数据并返回。
这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰L1缓存,不能同时将L1和L2中的缓存同时淘汰。L2缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
解决方案三:加锁
也就是在获取数据时,redis缓存不存在,在访问数据库时,通过加锁的方式获取数据库的值,这样就保证了访问数据库只有一个请求过来,从而保证数据库的负载。
缓存是我们项目应用肯定会使用,是我们数据库的守护神,能够保证数据库的稳定,能够提高整个系统的性能。一般我们采用市面上的redis、memcahce方案;redis已经非常强大了,每秒支持几万的连接时不成问题。
上图商品服务要获取商品信息时,先从redis缓存中获取,缓存中不存在再到数据库中取;数据库的资源时比较宝贵的,这样的设计就能把一些请求转移到redis上面去。这是我们小伙伴常用的缓存设计,绝大部分的缓存也就设计到此了。但只有这样的设计,真的我们就可以安枕无忧了吗?老顾带着大家了解一下雪崩,穿透,击穿的含义。
缓存雪崩
雪崩是指我们一般在设置缓存的时候都会设置一个缓存过期时间,如果一些缓存过期时间在同一刻,也就是缓存同时过期了。这个时候有大量请求过来,发现缓存中不存在,就直接到数据库中获取,就像雪崩一样同时打到数据库上面,这样就会导致数据库负载高,很有可能就会崩溃。
解决方案一:
发现缓存不存在,在读取数据库时,再保存到redis缓存中,采用队列的方式或加锁的方式,进行排队访问数据库,这样就能够避免同时打到数据库上。
解决方案二:
这个方案就比较简单,雪崩是因为过期时间在同一刻导致的,那我们就可以在设置过期时间分散开。如在原有的过期时间的基础上加上一个随机数,比如:1~10分钟,这样就不会放生在同一刻缓存失效了。
解决方案三:
设置二级缓存机制,这样就能够保证即时第一层缓存失效了,还有第二级缓存的保障;不过就增加了系统复杂性。
缓存穿透
穿透是指在查询一个不存在的数据,如商品id=10000,系统就不存在id为10000的数据。按照缓存设计的原理,缓存中找不到此商品,就会到数据库中查询,也没有找到。这样的请求都会打到数据库中,缓存在这个场景中就相当于没有。恶意的人利用这个漏洞发起攻击,直接把数据库搞崩溃。
解决方案一:
最常见的方法就是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的map中,一定不存在的数据会被这个map过滤掉,这样就避免了访问到数据库。
解决方案二:
就是把空值也缓存起来,如商品id=10000,数据库查询虽然没有找到,但会在redis中保存一个空值。这种方案就会碰到2个问题。
问题一:
空值做了缓存,这样就无形了增加了很多没有意义的缓存,内存吃紧。比较有效的方式就是在这些值上面设置一个过期时间,让起自动删除
问题二:
有可能与业务存在不一致的窗口时间,如:虽然商品ID=10000现在不存在,我们现在在redis中保存了一个空值,但业务后来就真的有了商品id为10000的数据,这样数据库和缓存的信息就不一致,导致业务出现问题。此时就可以利用消息中间件等方式系统剔除掉此缓存数据
缓存击穿
击穿是指某些数据被大量请求,也就是“热点”数据,一旦出现缓存过期时,就会有大量的请求打到后端的数据库,这样就会导致数据库崩溃
解决方案一:检测更新
最容易想到的是这些热点数据设置永不过期,就不存在此问题。这样就会出现一个问题,那缓存怎么去更新呢?
方法一:
可以做一个后台服务,专门用来做数据缓存的更新。每隔30分钟更新一下这些热点缓存数据。不过这样就增加了系统复杂度。
方法二:
方法一过于复杂,我们可以改造一下redis的缓存结构,在缓存业务数据的时候,再保存跟业务数据关联的过期时间key。每次请求过来时,判断一下此业务数据的是否要到过期时间了,如:此值还有1分钟就过期了,这样就服务本身主动去数据库查询一次,做一个缓存的更新。
解决方案二:分级缓存
分级缓存,可采用二级缓存的方式缓存此热点数据。
采用L1(一级缓存)和L2(二级缓存)缓存方式,L1缓存失效时间短,L2缓存失效时间长。请求优先从L1缓存获取数据,如果L1缓存未命中则加锁,只有1个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到L1缓存和L2缓存中,而其他线程依旧从L2缓存获取数据并返回。
这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰L1缓存,不能同时将L1和L2中的缓存同时淘汰。L2缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
解决方案三:加锁
也就是在获取数据时,redis缓存不存在,在访问数据库时,通过加锁的方式获取数据库的值,这样就保证了访问数据库只有一个请求过来,从而保证数据库的负载。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

