
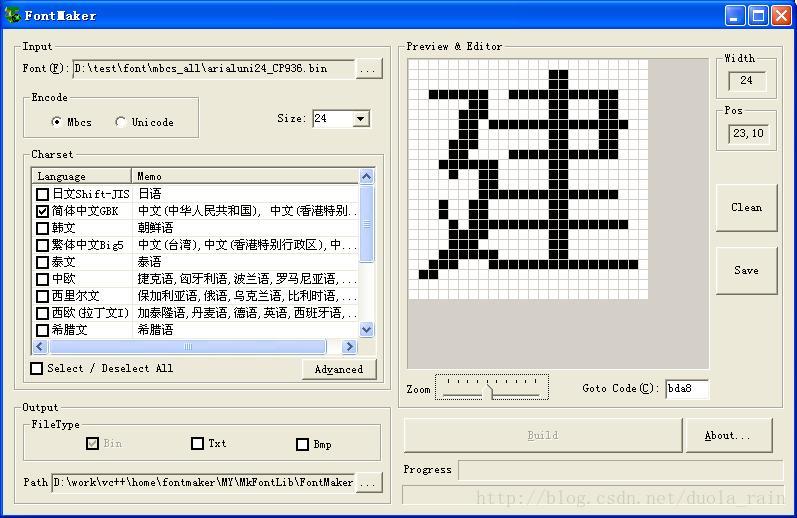
(该图就是字库软件主页面,ENCODE 编码选择UNICODE ,size 可以选择小一点的16x16的这样字库空间大概是1.3M多一点,FileType 选择BIN就好)
1. 转换字库,操作步骤如下:
1). 选择一个您要转换的矢量字体文件(*.ttf)。
先将c:\windows\fonts 目录下的字体文件拷贝(ctrl+c)出来,然后本软件即可选择。
建议去网上找一个ArialUni.ttf字库(可找本人提供),目前linux系统用的就是这个,字符非常全面。
2). 选择编码类型(MBCS or Unicode),根据需求而定。
3). 选择字体大小,根据需求而定,目前只支持16,24,32,40,48,56,本软件可根据需求而改成大字体 ( > 56 )。
4). 选择需要转换的字符集(支持多选),根据需求而定。比如:我要用到简体中文,则必须选简体中文,同时还可选其它。
5). 选择输出文件。(BIN 文件始终默认输出,其它可选)
6). 选择输出目录,即将您生成的文件存放到您选择的这个目录中。
7). 点击 build 按钮,稍等片刻,即可生成您所想要的字库文件。
注意: 如果您选择的是MBCS 编码方式,又有选择多个字符集,则会输出多份上述文件。
如果您选择的是NICODE编码方式,不论你选多少个字符集,都只会输出一份上述文件。
如果生成字库失败,则有可能你选择的字体文件(*.TTF)原本就不包含该字符集的字符信息。 比如:宋体中不存在韩文字符,即用宋体生成的字库无法支持韩文显示。
参考办法: 对照系统自带的字符映射表,里面就可以选择不同的字体,字符集(打开“高级查看”)进行参照。
开启字符映射表的方法:
1. 以命令方式运行开启,直接键入 "charmap"即可。
2. 程序-->附件-->系统工具--->字符映射表
2. 字库预览,操作步骤如下:
1). 选择一个您要预览的字库文件(*.bin)。将会自动打开分析出其编码类型,点阵大小,包含的字符集。
2). 在 goto code:后面的编辑框中,输入您要查看字符的编码(如果当前选择的字库*.BIN 是unicode编码,则输入unicode码,否则输入mbcs 编码),回车后即可看到其显示效果,还可得知其字符实际显示宽度。
CP932, 日文Shift-JIS, 如:日语
CP936, 简体中文GBK, 如:中文(中华人民共和国), 中文(香港特别行政区), 中文(新加坡)
CP949, 韩文, 如:朝鲜语
CP950, 繁体中文Big5, 如;中文(台湾), 中文(澳门特别行政区)
CP874, 泰文, 如:泰语
CP1250, 中欧, 如:捷克语,匈牙利语,波兰语,罗马尼亚语,克罗地亚语,斯洛伐克语,阿尔巴尼亚语,斯洛文尼亚语,塞尔维亚语(拉丁文)
CP1251, 西里尔文, 如:保加利亚语,俄语,乌克兰语,比利时语,马其顿语(FYROM),哈萨克语,吉尔吉斯语,鞑靼语,蒙古语,阿塞拜疆语,乌兹别克语,塞尔维亚语
CP1252, 西欧(拉丁文I), 如:加泰隆语,丹麦语,德语,英语,西班牙语,芬兰语,法语,冰岛语,意大利语,荷兰语,挪威语,葡萄牙语,印度尼西亚语,巴士克语,南非语,法罗语,马来语,斯瓦希里语,加里西亚语,瑞典语
CP1253, 希腊文, 如:希腊语
CP1254, 土耳其文, 如:土耳其语,阿塞拜疆语,乌兹别克语
CP1255, 希伯来文, 如:希伯来语
CP1256, 阿拉伯文, 如:乌都语,波斯语,阿拉伯语(伊拉克,埃及,利比亚,阿尔及利亚,摩洛哥,突尼斯,阿曼,也门,叙利亚,约旦,黎巴嫩,科威特,阿联酋,巴林,卡塔尔)
CP1257, 波罗的海文, 如:爱沙尼亚语,拉脱维亚语,立陶宛语,
CP1258, 越南, 如:越南语
unicode 可以由上述字符集根据需求自由合成。
2. 支持 BIN(*.bin), TXT(*.txt), BMP(*.bmp) 文件输出。
A. BIN 文件,即字库文件(必生成):存储的是我们最终需要用到的点阵字库信息。其文件结构由四大部分组成:文件头、段信息、检索表、点阵信息。
1). 文件头,指的是文件的前十六个字节(BYTE),描述信息如下结构:
typedef struct tagFontLibHeader{
BYTE magic[4]; //'U'(or 'M'), 'F', 'L', X 'U'(or 'M')---Unicode(or MBCS) Font Library, X: 表示版本号. 分高低4位。如 0x12表示 Ver 1.2
DWORD Size; /* File total size */
BYTE nSection; //MBCS:是否包含检索表。 Unicode:共分几段数据
BYTE YSize; /* height of font */
WORD wCpFlag; // codepageflag: bit0~bit13 每个bit分别代表一个CodePage 标志,如果是1,则表示当前CodePage 被选定,否则为非选定。
char reserved[4]; // 预留字节
} FL_Header;
2). 段信息,只针对 UNICODE 编码有效,占字节数:nSection*sizeof(FL_SECTION_INF)。结构如下:
typedef struct tagFlSectionInfo{
WORD First; /* first character */
WORD Last; /* last character */
DWORD OffAddr; /* 指向的是当前SECTION包含的 UFL_CHAR_INFO第一个字符信息的起始地址 */
} FL_SECTION_INF, *PFL_SECTION_INF;
3). 检索表,只针对非等宽的MBCS(不包含简中、繁中、日文、韩文,因这些都将等宽处理,故无需检索表)和 UNICODE 字库有效。
typedef struct tagUflCharInfo{
#ifdef SUPPORT_MAX_FONT // 如采用大字体结构,最大可支持248点阵
DWORD OffAddr; // 当前字符点阵数据的起始地址
BYTE Width; // 字符点阵的像素的宽度
#else
DWORD OffAddr : 26; // 当前字符点阵数据的起始地址
DWORD Width : 6; // 字符点阵的像素的宽度( 目前最大支持 56 点阵)
#endif
} UFL_CHAR_INDEX;
如果是非等宽的MBCS字库,则占字节数为:0xff * sizeof(UFL_CHAR_INDEX);
如果是Unicode字库,则占字节数为:((xxx[0].Last - xxx[0].First + 1)+...+(xxx[nSection-1].Last - xxx[nSection-1].First + 1)) * sizeof(UFL_CHAR_INDEX);
4). 点阵信息,即当前所有包含字符集中字符的点阵信息集合。数据存储方式为:横向高到底位存储。如: 10110011 00011010 即为 B3. 1A
例如:显示编码 code = xxxx 的字符。分为以下三种情况,分别操作步骤如下:
(1). 非等宽的MBCS字库
a. 先读出FL_Header信息;
b. 根据这个sizeof(FL_Header) + code * 2找到code的 UFL_CHAR_INDEX信息;
c. 根据UFL_CHAR_INDEX的OffAddr再找到当前code的点阵信息;
d. 最后根据FL_Header.Ysize、UFL_CHAR_INDEX.Width、以及点阵信息即可show出当前字符。
(2). 等宽的 MBCS字库 (包括简中、繁中、日文、韩文)
a. 先读出FL_Header信息;
b. 计算出code在当前字符集中的索引值(index),然后根据这个sizeof(FL_Header) + index * (FL_Header.Ysize/8*FL_Header.Ysize)找到code的点阵信息;
c. 然后根据FL_Header.Ysize与点阵信息即可show当前字符。
计算出当前code在你当前字符集(codepage)中位置,即索引值。此函数主要针对MBCS编码中的简中,繁中,日文,韩文,
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂