
实验五 互斥体
要整明白互斥体,首先要了解使用互斥体时,可能面对的一个有极大可能会使OS崩溃的问题:优先级反转。
啥是优先级反转?假设A、B、C三个任务,优先级A>B>C,A和C对同一个资源X有需求,如果C在使用X时锁定资源并满足触发A的条件,那么A就会进入运行状态而使C失去解锁的机会。由于A无法锁定X,那么只能进入等待态,并等C解锁X后才能运行。
如果A等待C解锁X的过程中,B所等待的事件也来临,那么毫无疑问,B就要优先于A和C而运行了。这样,ABC三个任务的运行情况就不再受优先级的约束,造成优先级反转的现象,很容易恶化操作系统运行情况。
为了避免这个情况的出现,μTenux中设置了2种机制去规避:优先级置顶和优先级继承。
所谓优先级置顶,就是将锁定互斥体的任务的优先级暂时提升至互斥体所设定的优先级。
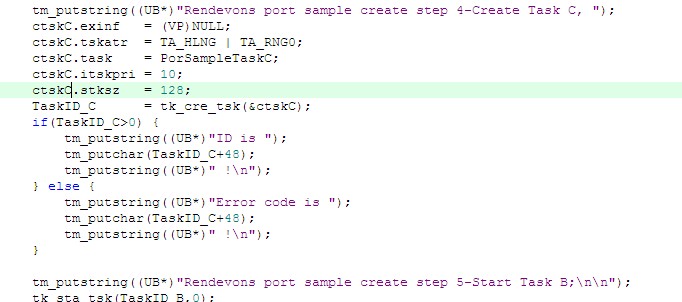
实验源代码就是使用这种机制,代码中cmtx.mtxatr = TA_TFIFO|TA_CEILING;cmtx.ceilpri = 15;置顶优先级设置的是15,而任务A和B的优先级则都是20.
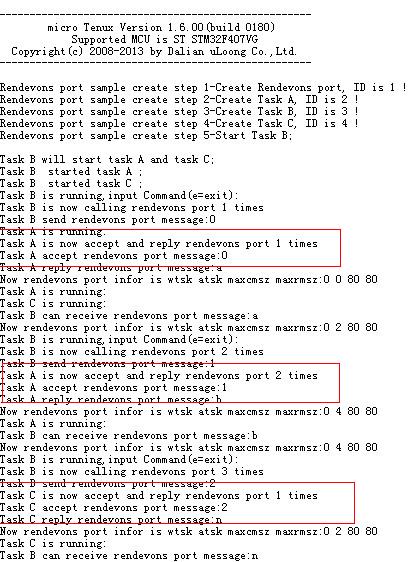
编译,下载,看打印信息。

从打印信息不难看出来,任何锁定互斥体Mutex的任务的优先级均被提升至互斥体定义的优先级15.
以保证锁定互斥体的任务能够顺利解锁,并释放给其他任务使用。
另外一种机制就是优先级继承,与优先级置顶不同,这种机制直接将锁定互斥体的任务的优先级提升至某个值,这个值由正在等待锁定这个互斥体的任务的最高优先级来决定。
修改实验源代码,cmtx.mtxatr = TA_TFIFO|TA_INHERIT;cmtx.ceilpri = 15;置顶优先级设置的是15,而任务A、B的优先级则分别是16、20,并使B在锁定互斥体后再调用任务A。
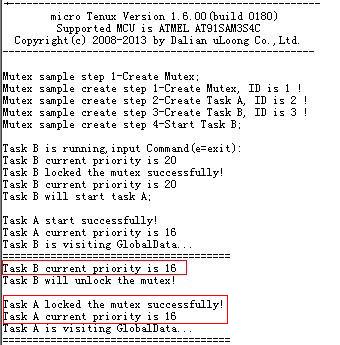
编译下载,从打印信息可以看出来,虽然设定互斥体的ceilpri为15,但是实际上锁定互斥体的任务的优先级在锁定后,都被提升为16,也就是等待锁定互斥体的任务的最高优先级,即A的优先级16.
实验五思考题
1) 本实验中演示了两个同优先级任务使用互斥体进行交替的方式,如果不使用互斥体的优先级置顶属性,或不使用互斥体的优先级继承属性,结果如何?
简单分析一下,如果不使用TA_INHERIT或TA_CEILING属性来构建互斥体,仅仅是使用TA_TPRI或TA_TFIFO来构建互斥体,很可能会出现优先级高的任务(不同优先级情况下)或先运行的任务(相同优先级)一直在操作互斥体。
立马实验,修改互斥体mtxatr的属性。发现无论A、B的优先级如何设定、mtxatr的属性只要不是TA_INHERIT或TA_CEILING,永远都只会有一个任务在操作互斥体,不会修改优先级,也不会交替执行。

如果要验证优先级反转,假设优先级由高到低的三个任务A、B、C,A和C操作互斥体,而B不对互斥体进行操作。
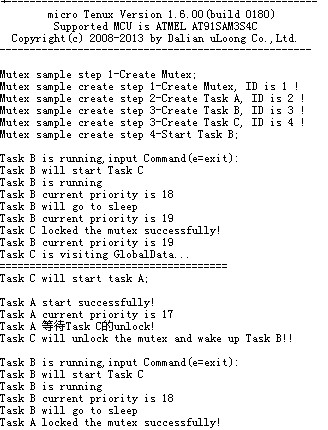
观察串口打印信息可以发现,A在等待TaskC解锁的时期,B能够优先于A执行,优先级反转鸟。
2)本实验中演示了两个同优先级任务使用事件标志进行交替的方式,如果把一个任务的优先级提高,
结果如何?什么情况下,会使用到这种方式?
简要分析一下,如果优先级不同,那么优先级高的任务会一直操作互斥体。
修改,编译,下载,run......
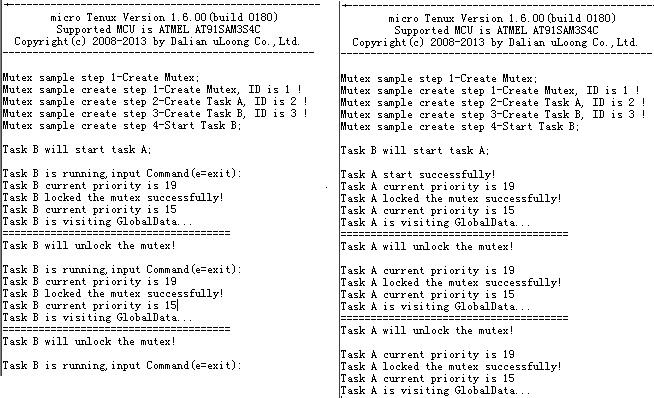
任务优先级还是按照优先级置顶的机制变化了,但是仅有较高优先级的任务在操作互斥体。
如果为较高优先级的任务设置合适的事件标志,可以保证较高优先级任务的资源独享,而不被其他任务破坏。
TBC......










 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

