
ARM Cortex-M3处理器
Cortex-M3处理器是一个低功耗的处理器,具有门数少, 中断延迟小, 调试容易等特点。它是为功耗和价格敏感的应用领域而专门设计的、具有较高性能的处理器,应用范围可从低端微控制器到复杂SoC。
Cortex-M3处理器使用了ARM v7-M体系结构,是一个可综合的、高度可配置的处理器。它包含了一个高效的哈佛结构三级流水线,可提供1.25DMIPS/MHz的性能。在一个具有32个物理中断的标准处理器实现上(0.13um Metro @50MHz),达到了突出的0.06mW/MHz能效比。
为降低器件成本,Cortex-M3处理器采用了与系统部件紧耦合的实现方法,来缩小芯片面积,其内核面积比现有的三级流水线内核缩小了30%。Cortex-M3处理器实现了Thumb-2指令集架构,具有很高的代码密度,可降低存储器需求,并能达到非常接近32位ARM指令集的性能。
对于系统和软件开发,Cortex-M3处理器具有以下优势:
。小的处理器内核、系统和存储器,可降低器件成本;
。完整的电源管理,很低的功耗;
。突出的处理器性能,可满足挑战性的应用需求;
。快速的中断处理,满足高速、临界的控制应用;
。可选的存储器保护单元(MPU),提供平台级的安全性;
。增强的系统调试功能,可加快开发进程;
。没有汇编代码要求,简化系统开发;
。宽广的适用范围:从超低成本微控制器到高性能SoC。
Cortex-M3处理器在高性能内核基础上,集成了多种系统外设,可以满足不同应用对成本和性能的要求。处理器是全部可综合、高度可定制的(包括物理中断、系统调试等),Cortex-M3还有一个可选的细粒度的(fine-granularity)存储器保护单元(MPU)和一个嵌入式跟踪宏单元(ETM)。
1.2.1 处理器组件
图 1 2 Cortex-M3部件图
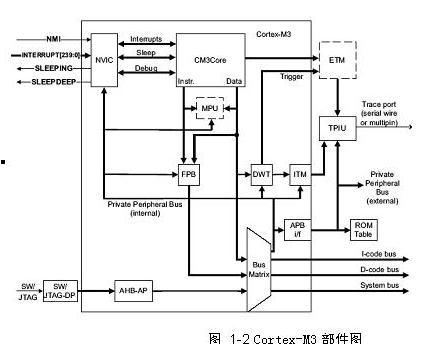
注意:ETM和MPU是可选组件,在某些实现中可能不存在
Cortex-M3处理器主要包括:
• 处理器内核
• 与处理器核紧密结合的嵌套向量中断控制器(NVIC)以实现低延迟的中断处理
• 存储器保护单元(MPU),可选部件MPU实现存储器保护。
• 总线接口
• 调试接口
1.2.2 Cortex-M3的层次和实现选项
处理器组件有两个层次,如图1-1所示,这是RTL设计层次。ETM、TPIU、SW/JTAG-DP和ROM表四个组件在Cortex-M3层的外部,因为这些组件要么是可选的,要么就是在实现和使用时可以灵活改变的。实际的实现可能与图1-2不一样,可能的实现选项:
。TPIU
TPIU是ITM、ETM(如果存在)和片外跟踪端口分析器之间传输Cortex-M3跟踪数据的桥梁。TPIU可以设置成支持低开销调试的串行引脚跟踪,或者用于更高带宽跟踪的多引脚跟踪。 TPIU是与CoreSight兼容的。
TPIU的实现选项有:
• 如果系统中有ETM组件,那么就有TPIU格式器,否则就没有。
• 多个TPIU中的一个就可以跟踪多核的实现。
• ARM TPIU部件可以被特定的CoreSight相应TPIU替代.
• 在一个实际器件中,可能没有TPIU。
注意
如果没有TPIU,那么Contex-M3就没有跟踪能力。
。SW/JTAG-DP
处理器可以设置成有SW-DP 或者 JTAG-DP 调试端口,或者两者都有。调试端口提供对系统中所有的外设寄存器、存储器、处理器寄存器的调试访问。
SW/JTAG-DP的实现选项有:
• 在实现中可能只有SW-DP或JTAG-DP,也可能都有。
• ARM SW-DP可能被合作方专用的配合CoreSight技术的SW-DP替代。
• ARM JTAG-DP可能被特定的CoreSight技术的JTAG-DP替代。
• 可能包含其他特定的测试接口,与SW-DP或JTAG-DP并联。
。ROM表
如果系统中加入额外的调试组件,ROM存储器表将进行修改。
1.2.3 处理器内核
处理器内核是ARMv7-M架构的。Cortex-M3内核是建立在一个高性能哈佛结构的三级流水线基础上的,可满足事件驱动的应用需求。通过广泛采用时钟选通等技术,改进了每个时钟周期的性能,包括单周期的32x32乘法和硬件除法,获得了优异的能效比。另外,通过一个基于堆栈的异常模式的实现,显著地缩小了内核的物理尺寸。Cortex-M3内核实现了Thumb-2指令集——传统Thumb指令集的一个超集,既获得了传统32位代码的性能,又具有16位的高代码密度。
Cortex-M3内核具有如下特点:
• ARMv7-M Thumb-2指令集架构(ISA)的子集,包括了所有16位和32位的Thumb-2基本指令,不包含SIMD、DSP和ARM系统访问。
• 采用哈佛处理器结构,在取指的同时可以读取/存储数据。
• 三级流水线。
• 单周期32位乘法。
• 硬件除法。
• Thumb和Debug状态。
• Handler和Thread模式。
• 处理器状态自动保存与恢复,保证低延迟的ISR进入和退出。
• 可打断-继续LDM/STM, PUSH/POP。
• 支持ARMv6的BE8/LE(大小端)。
• ARMv6不对齐访问。
寄存器
• 13个32位的通用寄存器。
• 链接寄存器(LR)。
• 程序计数器 (PC)。
• 程序状态寄存器xPSR。
• 2个分段堆栈指针寄存器。
存储器接口
处理器采用哈佛结构,在取指的同时可以读取/存储数据。访问存储器由以下部件控制:
• 一个独立的加载和存储单元(LSU),把读写操作从算术逻辑单元(ALU)中独立出来。
• 3个字长的入口预取单元。每次取一个字长的指令,可以是两条Thumb指令、一个字对齐的Thumb-2指令、或者一个半字对齐的Thumb-2指令的高/低半字、或者另一个半字对齐的Thumb-2指令的低/高半字。所有从内核取指的地址都是字对齐的。如果一条Thumb-2指令是半字对齐的,那么取这条指令就需要两次取指。然而,有了3个入口预取缓冲器就可以保证只有在取第一条半字的Thumb-2指令时,才需要一个周期的取指延迟。
1.2.4 嵌套向量中断控制器(NVIC)
Cortex-M3处理器紧密结合一个可配置的中断控制器(NVIC),提供了工业领先的中断处理性能。标准的NVIC实现包括一个不可屏蔽中断(NMI),加上具有优先级的32个通用物理中断。通过简单的综合选择,控制器可以被配置为1-244个物理中断。另外,抢占式优先级的数目,可以在综合时配置到255个。
与处理器内核的紧密结合,使处理器可以更快地执行中断服务程序(ISR)。典型情况下,从中断发生到进入服务可减少70%的周期数,这是通过寄存器硬件堆栈,加上退出和重启多寄存器Load-Store操作完成的。这种实现也意味着不需要任何汇编代码来完成寄存器数据传送,大大简化了代码。
NVIC采用尾链(Tail-Chaining)技术,简化了在激活与挂起的中断之间的数据传送。它用简单的6个周期的取指,取代了传统的串行堆栈通常需要超过30个时钟周期的Push-Pop操作。
为了提高低功耗特性,NVIC设计了三种睡眠方式。其深度睡眠(Deep-Sleep)功能可以输出信号到其他系统模块,使整个器件快速关闭。
NVIC为低延迟实现异常处理提供了方便。主要有以下特征:
• 可配置1~240个外部中断。
• 可配置优先级位数3~8位。
• 支持电平和脉冲(边沿)中断。
• 可以动态重新分配中断优先级。
• 优先级分组。
• 支持尾链(tail-chaining)中断。
• 进入中断时,处理器状态自动保存,退出中断时状态自动恢复,无额外指令开销。
1.2.5 总线矩阵
ARM Cortex-M3处理器集成了一个AMBA AHB-Lite总线来连接系统外设,并降低系统集成的复杂性。总线矩阵支持不对齐的数据访问,使不同的数据类型可以在存储器中紧密衔接(不因为数据需要对齐而留出空隙),可显著降低SRAM的需求和系统成本。
总线矩阵将处理器、调试接口连接到外部总线。总线矩阵连接到以下外部总线:
• ICode总线。这是一条32位的AHB-Lite总线,主要用于从指令空间中取指和取向量。
• DCode总线。这是一条32位的AHB-Lite总线,主要用于从指令空间的数据读写和调试访问。
• 系统总线。这是一条32位的AHB-Lite总线,主要用于从系统空间中取指、取向量、读写数据和调试访问。
• PPB。这是一条32位的APB (v2.0)总线,主要用于从PPB空间读写数据和调试访问。
总线矩阵还控制:
• 不对齐访问。总线矩阵把不对齐的处理器访问转化成对齐的访问。
• 位绑定(bit banding)。 总线矩阵把位绑定的别名(alias)访问转换成位绑定的区域访问。完成如下操作:
— 对位绑定的装载,提取位域 。
— 对位绑定的存储,读-修改-写变成原子操作。
• 写缓冲。总线矩阵有一个写缓冲器,使总线等待脱离处理器内核。
1.2.6 集成调试
ARM Cortex-M3实现了一个完整的硬件调试解决方案,通过一个传统的JTAG口或一个适合小封装器件的2线串行调试口(SWD),可以获得很高的处理器系统可视度。
对于系统跟踪,处理器在数据观察点基础上集成了一个可选的ETM(嵌入式跟踪宏单元),它可以被配置为特定的系统事件触发。为了简化这些系统事件的处理,一个串行观测器(Serial Wire Viewer,SWV)可以通过一个引脚输出标准的ASCII数据流。
Flash修补技术,使器件和系统开发者在调试或运行过程中,可以修补从ROM到SRAM或Flash的代码错误,可避免昂贵的重定制。
Cortex-M3有关系统调试的几个组件:FPB、DWT和ITM。
FPB
FPB单元实现了硬件断点和从代码空间到系统空间的修正存取。FPB有八个比较器:
• 6个指令比较器,可以各自被配置成实现把取指从指令空间重映射到系统空间,或者实现一个硬件断点。
• 2个文字(literal)比较器。可以把文字存取从指令空间重映射到系统空间。
DWT
DWT单元含有以下的调试功能:
• 它有四个比较器,每个都能设置成一个硬件观察点、一个ETM触发器、一个PC采样事件触发器,或者一个数据地址采样事件触发器。
• 性能分析用的几个计数器或数据匹配事件触发器。
• 可设置成在特定间隔发射一个PC采样值或中断事件信息。
ITM
ITM是一个应用驱动的跟踪源,它支持应用程序事件跟踪和printf风格的调试。
ITM提供以下跟踪信息的来源:
• 软件跟踪。 软件可以直接操作ITM有关寄存器,引发信息包发出。
• 硬件跟踪。 信息包由DWT产生,然后由ITM发出。
• 时间戳(time stamping)。与信息包相关的时间戳的发射。
1.2.7 可选组件
ARM Cortex-M3有二个可选组件:存储器保护单元(MPU)、嵌入式跟踪宏单元(ETM)。
细粒度的MPU设计,使多任务的应用可以实现安全特权,以及分离代码、数据和堆栈。在类似汽车等许多嵌入式应用中,这类需求正变得越来越普遍。
嵌入式跟踪单元(ETM)提供了一种远小于传统跟踪单元范围的指令跟踪捕获,使许多低价器件(如MCU)可以实现跟踪调试。
1.2.8 Cortex-M3处理器应用
Cortex-M3处理器的特性,使它适合很大范围的应用,主要包括:
价格敏感的设备——通用MCU、智能玩具、个人电子设备
。小的核可以降低硅片面积
。紧密结合系统外设可缩小面积、降低开发成本
。Thumb-2代码可减小指令存储器达30%
。SWD允许使用较小的引脚数和封装
。在ISR、Boot代码中无需汇编代码
。单周期的Read/Modify/Write,更紧凑的数据打包
。确定的中断处理
。系统更新时的修补能力(ROM到Flash、SRAM)
低功耗设备——Zigbee、PAN(BlueTooth)、医疗电子设备
。低功耗内核:0.047mW/MHz(0.13um,ARM Metro Lab,50MHz)
。高级时钟选通技术降低功耗
。集成的睡眠模式
。系统部件的功耗控制
。高效率允许较低的时钟源
。快速完成任务、增加睡眠时间,降低总的功耗
高性能设备——超低价格手机、汽车应用、大容量存储设备;
。性能可达1.25 DMIPS/MHz
。执行Thumb指令时,比ARM7处理器性能高70%
。执行ARM指令时,比ARM7处理器性能高35%
。硬件除法——更好的算法实现
。快速中断处理
。可选的MPU针对特定应用
。调试与跟踪能力
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

