
读/写自旋锁同样是在保护SMP体系下的共享数据结构而引入的,它的引入是为了增加内核的并发能力。只要内核控制路径没有对数据结构进行修改,读/写自旋锁就允许多个内核控制路径同时读同一数据结构。如果一个内核控制路径想对这个结构进行写操作,那么它必须首先获取读/写锁的写锁,写锁授权独占访问这个资源。这样设计的目的,即允许对数据结构并发读可以提高系统性能。
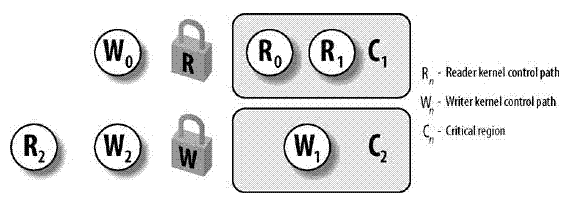
下图显示有两个受读/写锁保护的临界区(CI和C2)。内核控制路径R0和R1正在同时读取C1中的数据结构,而W0正等待获取写锁。内核控制路径W1正对C2中的数据结构进行写操作,而R2和W2分别等待获取读锁和写锁。
每个读/写自旋锁都是一个rwlock_t结构:
typedef struct {
raw_rwlock_t raw_lock;
#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
typedef struct {
volatile unsigned int lock;
} raw_rwlock_t;
其lock字段是一个32位的字段,分为两个不同的部分:
(1)24位计数器,表示对受保护的数据结构并发地进行读操作的内核控制路径的数目。这个计数器的二进制补码存放在这个字段的0~23位。
(2)“未锁”标志字段,当没有内核控制路径在读或写时设置该位,否则清0。这个“未锁”标志存放在lock字段的第24位。
注意,如果自旋锁为空(设置了“未锁”标志且无读者),那么lock字段的值为0x01000000;如果写者已经获得自旋锁(“未锁”标志清0且无读者),那么lock字段的值为0x00000000;如果一个、两个或多个进程因为读获取了自旋锁,那么,lock字段的值为Ox00ffffff,Ox00fffffe等(“未锁”标志清0表示写锁定,不允许写该数据结构的进程,读者个数的二进制补码在0~23位上;如果全为0,则表示有一个写进程在操作此数据结构)。与spinlock_t结构一样,rwlock_t结构也包括break_lock字段。
rwlock_init宏把读/写自旋锁的lock字段初始化为0x01000000(“未锁”),把break_lock初始化为0,算法类似spin_lock_init。进程获得读写自旋锁的方式不仅有是否设置了内核抢占选项而不同外,还跟读或写的操作相关。前者的算法跟自旋锁机制几乎一样,下面我们就重点讨论后者:
1 为读获取和释放一个锁
read_lock宏,作用于读/写自旋锁的地址*lock,与上一篇博文所描述的spin_lock宏非常相似。如果编译内核时选择了内核抢占选项,read_lock宏执行与spin_lock()非常相似的操作,只有一点不同:该宏执行_raw_read_trylock( )函数以在第2步有效地获取读/写自旋锁。
void __lockfunc _read_lock(rwlock_t *lock)
{
preempt_disable();
rwlock_acquire_read(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, _raw_read_trylock, _raw_read_lock);
}
在没有定义调试自旋锁操作时rwlock_acquire_read为空函数,我们不去管它。所以_read_lock的实务函数是_raw_read_trylock:
# define _raw_read_trylock(rwlock) __raw_read_trylock(&(rwlock)->raw_lock)
static inline int __raw_read_trylock(raw_rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock;
atomic_dec(count);
if (atomic_read(count) >= 0)
return 1;
atomic_inc(count);
return 0;
}
读/写锁计数器lock字段是通过原子操作来访问的。注意,尽管如此,但整个函数对计数器的操作并不是原子性的,利用原子操作主要目的是禁止内核抢占。例如,在用if语句完成对计数器值的测试之后并返回1之前,计数器的值可能发生变化。不过,函数能够正常工作:实际上,只有在递减之前计数器的值不为0或负数的情况下,函数才返回1,因为计数器等于0x01000000表示没有任何进程占用锁,等于Ox00ffffff表示有一个读者,等于0x00000000表示有一个写者(因为只可能有一个写者)。
如果编译内核时没有选择内核抢占选项,read_lock宏产生下面的汇编语言代码:
movl $rwlp->lock,%eax
lock; subl $1,(%eax)
jns 1f
call _ _read_lock_failed
1:
这里,__read_lock_failed()是下列汇编语言函数:
_ _read_lock_failed:
lock; incl (%eax)
1: pause
cmpl $1,(%eax)
js 1b
lock; decl (%eax)
js _ _read_lock_failed
ret
read_lock宏原子地把自旋锁的值减1,由此增加读者的个数。如果递减操作产生一个非负值,就获得自旋锁;否则就算作失败。我们看到lock字段的值由Ox00ffffff到0x00000000要减多少次才可能出现负值,所以几乎很难出现调用__read_lock_failed()函数的情况。该函数原子地增加lock字段以取消由read_lock宏执行的递减操作,然后循环,直到lock字段变为正数(大于或等于0)。接下来,__read_lock_failed()又试图获取自旋锁(正好在cmpl指令之后,另一个内核控制路径可能为写获取自旋锁)。
释放读自旋锁是相当简单的,因为read_unlock宏只需要使用汇编语言指令简单地增加lock字段的计数器:
lock; incl rwlp->lock
以减少读者的计数,然后调用preempt_enable()重新启用内核抢占。
2 为写获取或释放一个锁
write_lock宏实现的方式与spin_lock()和read_lock()相似。例如,如果支持内核抢占,则该函数禁用内核抢占并通过调用_raw_write_trylock()立即获得锁。如果该函数返回0,说明锁已经被占用,因此,该宏像前面博文描述的那样重新启用内核抢占并开始忙等待循环。
#define write_lock(lock) _write_lock(lock)
void __lockfunc _write_lock(rwlock_t *lock)
{
preempt_disable();
rwlock_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, _raw_write_trylock, _raw_write_lock);
}
_raw_write_trylock()函数描述如下:
int _raw_write_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
if (atomic_sub_and_test(0x01000000, count))
return 1;
atomic_add(0x01000000, count);
return 0;
}
static __inline__ int atomic_sub_and_test(int i, atomic_t *v)
{
unsigned char c;
__asm__ __volatile__(
LOCK "subl %2,%0; sete %1"
:"=m" (v->counter), "=qm" (c)
:"ir" (i), "m" (v->counter) : "memory");
return c;
}
函数_raw_write_trylock()调用tomic_sub_and_test(0x01000000, count)从读/写自旋锁lock->lock的值中减去0x01000000,从而清除未上锁标志(看见没有?正好是第24位)。如果减操作产生0值(没有读者),则获取锁并返回1;否则,函数原子地在自旋锁的值上加0x01000000,以取消减操作。
释放写锁同样非常简单,因为write_unlock宏只需使用汇编语言指令:
lock; addl $0x01000000,rwlp
把lock字段中的“未锁”标识置位,然后再调用preempt_enable()。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

