
本文是近期学习CMA模块的一个学习笔记,方便日后遗忘的时候,回来查询以便迅速恢复上下文。
学习的基本方法是这样的:一开始,我自己先提出了若干的问题,然后带着这些问题查看网上的资料,代码,最后整理形成这样以问题为导向的index,顺便也向笨叔叔致敬。笨叔叔写了一本书叫做《奔跑吧Linux内核》,采用了问答的方式描述了4.x Linux内核中的进程管理、内存管理,同步和中断子系统。7月将和大家见面,敬请期待。
阅读本文最好手边有一份linux source code,我使用的是4.4.6版本。
一、什么是CMA
CMA,Contiguous Memory Allocator,是内存管理子系统中的一个模块,负责物理地址连续的内存分配。一般系统会在启动过程中,从整个memory中配置一段连续内存用于CMA,然后内核其他的模块可以通过CMA的接口API进行连续内存的分配。CMA的核心并不是设计精巧的算法来管理地址连续的内存块,实际上它的底层还是依赖内核伙伴系统这样的内存管理机制,或者说CMA是处于需要连续内存块的其他内核模块(例如DMA mapping framework)和内存管理模块之间的一个中间层模块,主要功能包括:
1、解析DTS或者命令行中的参数,确定CMA内存的区域,这样的区域我们定义为CMA area。
2、提供cma_alloc和cma_release两个接口函数用于分配和释放CMA pages
3、记录和跟踪CMA area中各个pages的状态
4、调用伙伴系统接口,进行真正的内存分配。
二、内核中为何建立CMA模块?
Linux内核中已经提供了各种内存分配的接口,为何还有建立CMA这种连续内存分配的机制呢?
我们先来看看内核哪些模块有物理地址连续的需求。huge page模块需要物理地址连续是显而易见的。大家都熟悉的处理器(不要太古老),例如ARM64,其内存管理单元都可以支持多个页面大小(4k、64K、2M或者更大的page size),但在大多数CPU架构上,Linux内核总是倾向使用最小的page size,即4K page size。Page size大于4K的page统称为“huge page”。对于一个2M的huge page,MMU会把一个连续的2M的虚拟地址mapping到连续的、2M的物理地址上去,当然,这2M size的物理地址段必须是由512个地址连续的4k page frame组成。
当然,更多的连续内存的分配需求来自形形色色的驱动。例如现在大家的手机都有视频功能,camer功能,这类驱动都需要非常大块的内存,而且有DMA用来进行外设和大块内存之间的数据交换。对于嵌入式设备,一般不会有IOMMU,而且DMA也不具备scatter-getter功能,这时候,驱动分配的大块内存(DMA buffer)必须是物理地址连续的。
顺便说一句,huge page的连续内存需求和驱动DMA buffer还是有不同的,例如在对齐要求上,一个2M的huge page,其底层的2M 的物理页面的首地址需要对齐在2M上,一般而言,DMA buffer不会有这么高的对齐要求。因此,我们这里讲的CMA主要是为设备驱动准备的,huge page相关的内容不在本文中描述。
我们来一个实际的例子吧:我的手机,像素是1300W的,一个像素需要3B,那么拍摄一幅图片需要的内存大概是1300W x 3B = 26MB。通过内存管理系统分配26M的内存,压力可是不小。当然,在系统启动之处,伙伴系统中的大块内存比较大,也许分配26M不算什么,但是随着系统的运行,内存不断的分配、释放,大块内存不断的裂解,再裂解,这时候,内存碎片化导致分配地址连续的大块内存变得不是那么的容易了,怎么办?作为驱动工程师,我们有两个选择:其一是在启动时分配用于视频采集的DMA buffer,另外一个方案是当实际使用camer设备的时候分配DMA buffer。前者的选择是可靠的,但它有一个缺点,即当照相机不使用时(大多数时间内camera其实都是空闲的),预留的那些DMA BUFFER的内存实际上是浪费了(特别在内存配置不大的系统上更是如此)。后一种选择不会浪费内存,但是不可靠,随着内存碎片化,大的、连续的内存分配变得越来越困难,一旦内存分配失败,camera功能就会缺失,估计用户不会答应。
这就是驱动工程师面临的困境,为了解决这个问题,各个驱动各出奇招,但是都不能非常完美的解决问题。最终来自Michal Nazarewicz的CMA补丁将可以把各个驱动工程师的烦恼“一洗了之”。对于CMA 内存,当前驱动没有分配使用的时候,这些memory可以内核的被其他的模块使用(当然有一定的要求),而当驱动分配CMA内存后,那些被其他模块使用的内存需要吐出来,形成物理地址连续的大块内存,给具体的驱动来使用。
三、CMA模块的蓝图是怎样的?
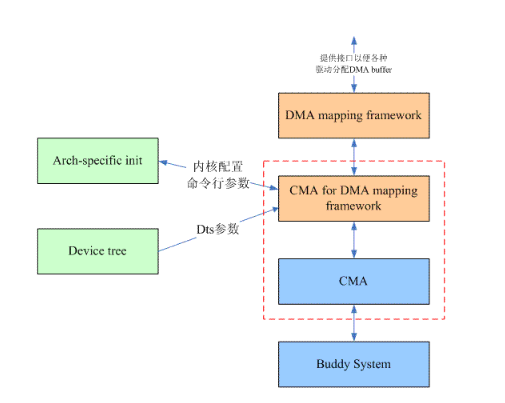
了解一个模块,先不要深入细节,我们先远远的看看CMA在整个系统中的位置。虽然用于解决驱动的内存分配问题,但是驱动并不会直接调用CMA模块的接口,而是通过DMA mapping framework来间接使用CMA的服务。一开始,CMA area的概念是全局的,通过内核配置参数和命令行参数,内核可以定位到Global CMA area在内存中的起始地址和大小(注:这里的Global的意思是针对所有的driver而言的)。并在初始化的时候,调用dma_conTIguous_reserve函数,将指定的memory region保留给Global CMA area使用。人性是贪婪的,驱动亦然,很快,有些驱动想吃独食,不愿意和其他驱动共享CMA,因此出现两种CMA area:Global CMA area给大家共享,而per device CMA可以给指定的一个或者几个驱动使用。这时候,命令行参数不是那么合适了,因此引入了device tree中的reserved memory node的概念。当然,为了兼容,内核仍然支持CMA的command line参数。
三、CMA模块如何管理和配置CMA area?
在CMA模块中,struct cma数据结构用来抽象一个CMA area,具体定义如下:
struct cma {
unsigned long base_pfn;
unsigned long count;
unsigned long *bitmap;
unsigned int order_per_bit; /* Order of pages represented by one bit */
struct mutex lock;
};
cma模块使用bitmap来管理其内存的分配,0表示free,1表示已经分配。具体内存管理的单位和struct cma中的order_per_bit成员相关,如果order_per_bit等于0,表示按照一个一个page来分配和释放,如果order_per_bit等于1,表示按照2个page组成的block来分配和释放,以此类推。struct cma中的bitmap成员就是管理该cma area内存的bit map。count成员说明了该cma area内存有多少个page。它和order_per_bit一起决定了bitmap指针指向内存的大小。base_pfn定义了该CMA area的起始page frame number,base_pfn和count一起定义了该CMA area在内存在的位置。
我们前面说过了,CMA模块需要管理若干个CMA area,有gloal的,有per device的,代码如下:
struct cma cma_areas[MAX_CMA_AREAS];
每一个struct cma抽象了一个CMA area,标识了一个物理地址连续的memory area。调用cma_alloc分配的连续内存就是从CMA area中获得的。具体有多少个CMA area是编译时决定了,而具体要配置多少个CMA area是和系统设计相关,你可以为特定的驱动准备一个CMA area,也可以只建立一个通用的CMA area,供多个驱动使用(本文重点描述这个共用的CMA area)。
房子建好了,但是还空着,要想金屋藏娇,还需要一个CMA配置过程。配置CMA内存区有两种方法,一种是通过dts的reserved memory,另外一种是通过command line参数和内核配置参数。
device tree中可以包含reserved-memory node,在该节点的child node中,可以定义各种保留内存的信息。compaTIble属性是shared-dma-pool的那个节点是专门用于建立 global CMA area的,而其他的child node都是for per device CMA area的。
Global CMA area的初始化可以参考定义如下:
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
具体的setup过程倒是比较简单,从device tree中可以获取该memory range的起始地址和大小,调用cma_init_reserved_mem函数即可以注册一个CMA area。需要补充说明的是:CMA对应的reserved memory节点必须有reusable属性,不能有no-map的属性。具体reusable属性的reserved memory有这样的特性,即在驱动不使用这些内存的时候,OS可以使用这些内存(当然有限制条件),而当驱动从这个CMA area分配memory的时候,OS可以reclaim这些内存,让驱动可以使用它。no-map属性和地址映射相关,如果没有no-map属性,那么OS会为这段memory创建地址映射,象其他普通内存一样。但是有no-map属性的往往是专用于某个设备驱动,在驱动中会进行io remap,如果OS已经对这段地址进行了mapping,而驱动又一次mapping,这样就有不同的虚拟地址mapping到同一个物理地址上去,在某些ARCH上(ARMv6之后的cpu),会造成不可预知的后果。而CMA这个场景,reserved memory必须要mapping好,这样才能用于其他内存分配场景,例如page cache。
per device CMA area的注册过程和各自具体的驱动相关,但是最终会dma_declare_conTIguous这个接口函数,为一个指定的设备而注册CMA area,这里就不详述了。
通过命令行参数也可以建立cma area。我们可以通过cma=nn[MG]@[start[MG][-end[MG]]]这样命令行参数来指明Global CMA area在整个物理内存中的位置。在初始化过程中,内核会解析这些命令行参数,获取CMA area的位置(起始地址,大小),并调用cma_declare_conTIguous接口函数向CMA模块进行注册(当然,和device tree传参类似,最终也是调用cma_init_reserved_mem接口函数)。除了命令行参数,通过内核配置(CMA_SIZE_MBYTES和CMA_SIZE_PERCENTAGE)也可以确定CMA area的参数。
四、memblock、CMA和伙伴系统的初始化顺序是怎样的?
套用一句广告词:CMA并不进行内存管理,它只是”内存管理机制“的搬运工。也就是说,CMA area的内存最终还是要并入伙伴系统进行管理。在这样大方向的指导下,CMA模块的初始化必须要在适当的时机,以适当的方式插入到内存管理(包括memblock和伙伴系统)初始化过程中。
内存管理子系统进行初始化的时候,首先是memblock掌控全局的,这时候需要确定整个系统的的内存布局,简单说就是了解整个memory的分布情况,哪些是memory block是memory type,哪些memory block是reserved type。毫无疑问,CMA area对应的当然是reserved type。最先进行的是memory type的内存块的建立,可以参考如下代码:
setup_arch--->setup_machine_fdt--->early_init_dt_scan--->early_init_dt_scan_nodes--->memblock_add
随后会建立reserved type的memory block,可以参考如下代码:
setup_arch--->arm64_memblock_init--->early_init_fdt_scan_reserved_mem--->__fdt_scan_reserved_mem--->memblock_reserve
完成上面的初始化之后,memblock模块已经通过device tree构建了整个系统的内存全貌:哪些是普通内存区域,哪些是保留内存区域。对于那些reserved memory,我们还需要进行初始化,代码如下:
setup_arch--->arm64_memblock_init--->early_init_fdt_scan_reserved_mem--->fdt_init_reserved_mem--->__reserved_mem_init_node
上面的代码会scan内核中的一个特定的section(还记得前面RESERVEDMEM_OF_DECLARE的定义吗?),如果匹配就会调用相应的初始化函数,而对于Global CMA area而言,这个初始化函数就是rmem_cma_setup。当然,如果有需要,具体的驱动也可以定义自己的CMA area,初始化的思路都是一样的。
至此,通过device tree,所有的内核模块要保留的内存都已经搞清楚了(不仅仅是CMA保留内存),是时候通过命令行参数保留CMA内存了,具体的调用如下:
setup_arch--->arm64_memblock_init--->dma_contiguous_reserve
实际上,在构建CMA area上,device tree的功能已经完全碾压命令行参数,因此dma_contiguous_reserve有可能没有实际的作用。如果没有通过命令行或者内核配置文件来定义Global CMA area,那么这个函数调用当然不会起什么作用,如果device tree已经设定了Global CMA area,那么其实dma_contiguous_reserve也不会真正reserve memory(device tree优先级高于命令行)。
如果有配置命令行参数,而且device tree并没有设定Global CMA area,那么dma_contiguous_reserve才会真正有作用。那么根据配置参数可以有两种场景:一种是CMA area是固定位置的,即参数给出了确定的起始地址和大小,这种情况比较简单,直接调用memblock_reserve就OK了,另外一种情况是动态分配的,这时候,需要调用memblock的内存分配接口memblock_alloc_range来为CMA area分配内存。
memblock始终是初始化阶段的内存管理模块,最终我们还是要转向伙伴系统,具体的代码如下:
start_kernel--->mm_init--->mem_init--->free_all_bootmem--->free_low_memory_core_early--->__free_memory_core
在上面的过程中,free memory被释放到伙伴系统中,而reserved memory不会进入伙伴系统,对于CMA area,我们之前说过,最终被由伙伴系统管理,因此,在初始化的过程中,CMA area的内存会全部导入伙伴系统(方便其他应用可以通过伙伴系统分配内存)。具体代码如下:
core_initcall(cma_init_reserved_areas);
至此,所有的CMA area的内存进入伙伴系统。
五、CMA是如何工作的?
1、准备知识
如果想要了解CMA是如何运作的,你可能需要知道一点点关于migrate types和pageblocks的知识。当从伙伴系统请求内存的时候,我们需要提供了一个gfp_mask的参数。它有很多的功能,不过在CMA这个场景,它用来指定请求页面的迁移类型(migrate type)。migrate type有很多中,其中有一个是MIGRATE_MOVABLE类型,被标记为MIGRATE_MOVABLE的page说明该页面上的数据是可以迁移的。也就是说,如果需要,我们可以分配一个新的page,copy数据到这个new page上去,释放这个page。而完成这样的操作对系统没有任何的影响。我们来举一个简单的例子:对于内核中的data section,其对应的page不是是movable的,因为一旦移动数据,那么内核模块就无法访问那些页面上的全局变量了。而对于page cache这样的页面,其实是可以搬移的,只要让指针指向新的page就OK了。
伙伴系统不会跟踪每一个page frame的迁移类型,实际上它是按照pageblock为单位进行管理的,memory zone中会有一个bitmap,指明该zone中每一个pageblock的migrate type。在处理内存分配请求的时候,一般会首先从和请求相同migrate type(gfp_mask)的pageblocks中分配页面。如果分配不成功,不同migrate type的pageblocks中也会考虑,甚至可能改变pageblock的migrate type。这意味着一个non-movable页面请求也可以从migrate type是movable的pageblock中分配。这一点CMA是不能接受的,所以我们引入了一个新的migrate type:MIGRATE_CMA。这种迁移类型具有一个重要性质:只有可移动的页面可以从MIGRATE_CMA的pageblock中分配。
2、初始化CMA area
static int __init cma_activate_area(struct cma *cma)
{
int bitmap_size = BITS_TO_LONGS(cma_bitmap_maxno(cma)) * sizeof(long);
unsigned long base_pfn = cma->base_pfn, pfn = base_pfn;
unsigned i = cma->count >> pageblock_order;
struct zone *zone; -----------------------------(1)
cma->bitmap = kzalloc(bitmap_size, GFP_KERNEL); ----分配内存
zone = page_zone(pfn_to_page(pfn)); ---找到page对应的memory zone
do {--------------------------(2)
unsigned j;
base_pfn = pfn;
for (j = pageblock_nr_pages; j; --j, pfn++) {-------------(3)
if (page_zone(pfn_to_page(pfn)) != zone)
goto err;
}
init_cma_reserved_pageblock(pfn_to_page(base_pfn));----------(4)
} while (--i);
mutex_init(&cma->lock);
return 0;
err:
kfree(cma->bitmap);
cma->count = 0;
return -EINVAL;
}
(1)CMA area有一个bitmap来管理各个page的状态,这里bitmap_size给出了bitmap需要多少的内存。i变量表示该CMA area有多少个pageblock。
(2)遍历该CMA area中的所有的pageblock。
(3)确保CMA area中的所有page都是在一个memory zone内,同时累加了pfn,从而得到下一个pageblock的初始page frame number。
(4)将该pageblock导入到伙伴系统,并且将migrate type设定为MIGRATE_CMA。
2、分配连续内存
cma_alloc用来从指定的CMA area上分配count个连续的page frame,按照align对齐。具体的代码就不再分析了,比较简单,实际上就是从bitmap上搜索free page的过程,一旦搜索到,就调用alloc_contig_range向伙伴系统申请内存。需要注意的是,CMA内存分配过程是一个比较“重”的操作,可能涉及页面迁移、页面回收等操作,因此不适合用于atomic context。
3、释放连续内存
分配连续内存的逆过程,除了bitmap的操作之外,最重要的就是调用free_contig_range,将指定的pages返回伙伴系统。
参考文献:
LWN上的若干和CMA相关的文档,包括:
1、A deep dive into CMA
2、A reworked contiguous memory allocator
3、CMA and ARM
4、Contiguous memory allocation for drivers
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

