
前言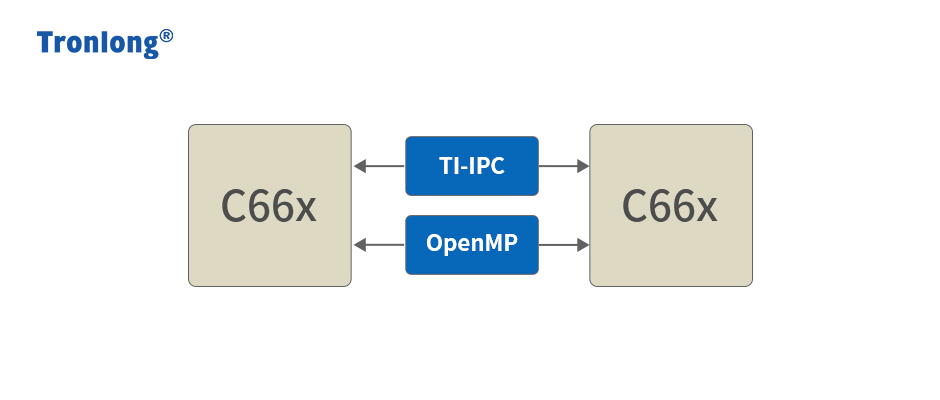
嵌入式领域的处理器已向多核架构迅速发展,TI公司的KeyStone架构的TMS320C6678是目前市面上性能最高的多核DSP处理器。TMS320C6678集成8核C66xDSP处理器,每个内核频率高达1.25GHz,提供每秒高达40GMAC定点运算和20GFLOP浮点运算能力;1片TMS320C6678提供等效达10GHz的内核频率,单精度浮点并行运算能力理论上可达160GFLOP,是TS201S的50倍、C67x+的115.2倍,适合于诸如油气勘探、雷达信号处理、图像处理以及定位导航等对定浮点运算能力及实时性有较高要求的超高性能计算应用。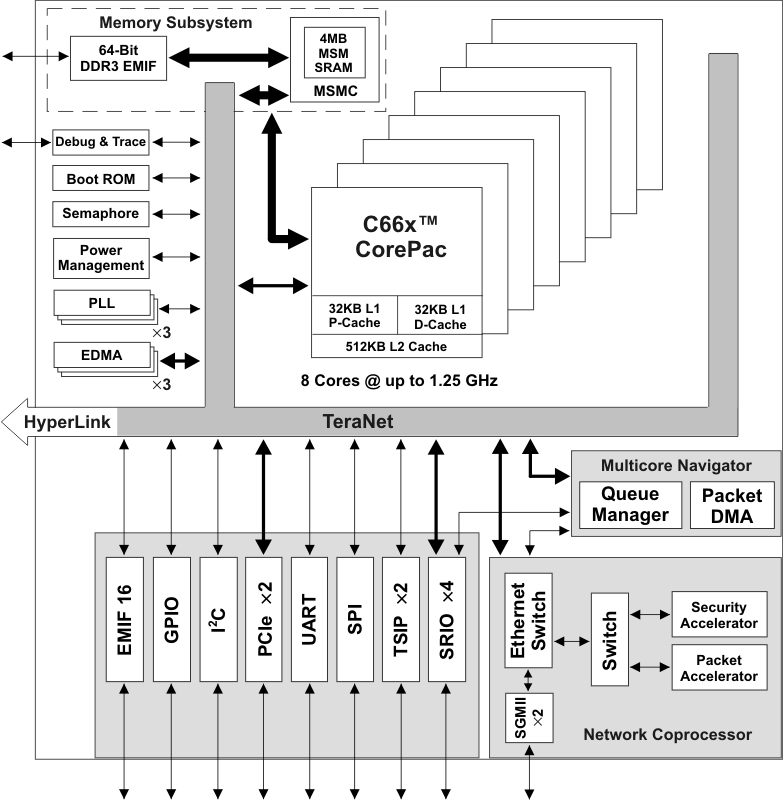
然而,核间通信是多核处理器系统所面临的主要难点,通信机制的优劣直接影响多核处理器的性能,高效的通信机制是发挥多核处理器高性能的重要保障。
创龙科技(Tronlong)专注于DSP、ARM、FPGA多核异构技术开发,本文为您介绍TMS320C6678处理器开发中比较常用的两种多核通信方式:TI-IPC和OpenMP,以及多核编程注意事项。
1硬件平台
本文基于创龙科技TL6678-EasyEVM评估板进行演示。
TL6678-EasyEVM是一款基于TIKeyStone架构c6000系列TMS320C6678八核C66x定点/浮点高性能处理器设计的高端多核DSP评估板,由核心板与底板组成。核心板经过专业的PCBLayout和高低温测试验证,稳定可靠,可满足各种工业应用环境。
评估板接口资源丰富,引出双路千兆网口、SRIO、PCIe等高速通信接口,方便用户快速进行产品方案评估与技术预研。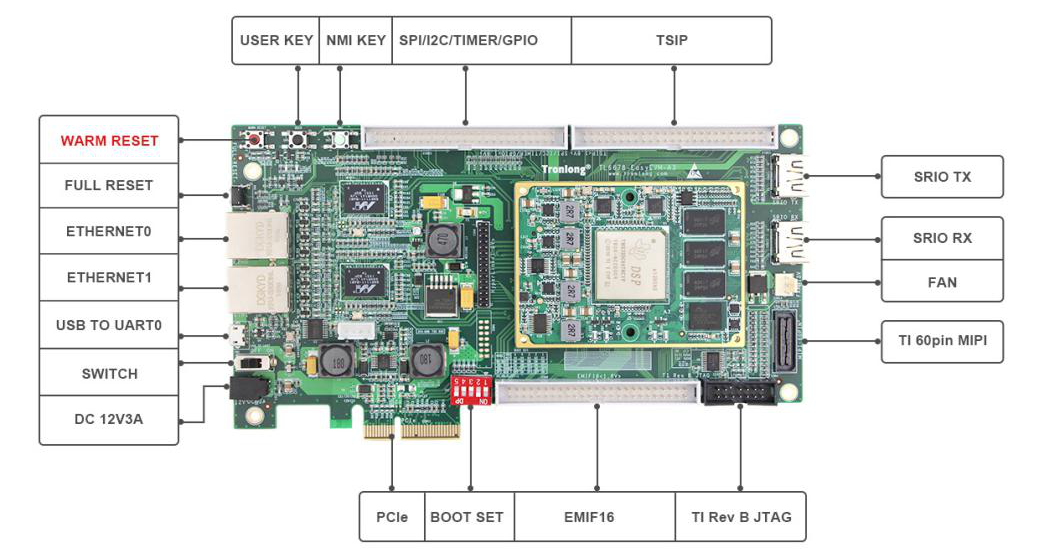
TL6678-EasyEVM评估板
开发案例主要包括:
(1)裸机开发案例
(2)RTOS(SYS/BIOS)开发案例
(3)IPC、OpenMP多核开发案例
(4)SRIO、PCIe、双千兆网口开发案例
(5)图像处理开发案例
(6)DSP算法开发案例
(7)串口、网络远程升级开发案例
C66xDSP视频教程、中文手册、产品资料(用户手册、核心板硬件资料、产品规格书)可点:site.tronlong.com/pfdownload直接获取。
2TI-IPC
2.1简介
TI-IPC(Inter-ProcessorCommunication)组件提供与处理器硬件无关的API,可用于多核处理器核间通信、同一处理器进程间通信和设备间通信。API支持消息传递、流和链接列表,它们在单处理器和多处理器中配置均可兼容。
TI-IPC被设计在运行SYS/BIOS应用程序的处理器上使用,一般为DSP处理器(如TMS320C6678、TMS320C6657),但在某些情况下亦可能是ARM处理器。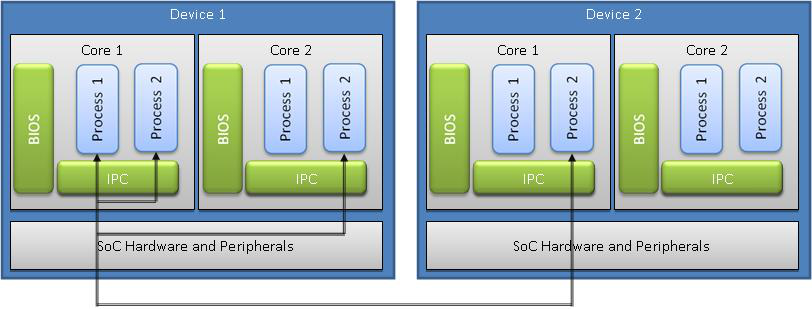
IPC常见的通信模块如下:
表1
| Ipc | 提供Ipc_start()函数,并允许配置启动顺序 |
| MessageQ | 大小可变的消息传递模块 |
| Notify | 以中断方式实现轻量数据传输的模块 |
| ListMp | 用于实现对链接列表的互斥访问 |
| GateMp | 用于实现对共享资源的互斥访问 |
| HeapBufMp | 大小固定的共享内存堆 |
| HeapMenMp | 大小可变的共享内存堆 |
| SharedRegion | 用于维护共享内存区域 |
| List | 用于创建双向链接列表 |
| MultiProc | 用于管理多核处理器核心ID |
| NameServer | 用于应用程序基于本地名称检索,以及存储变量值 |
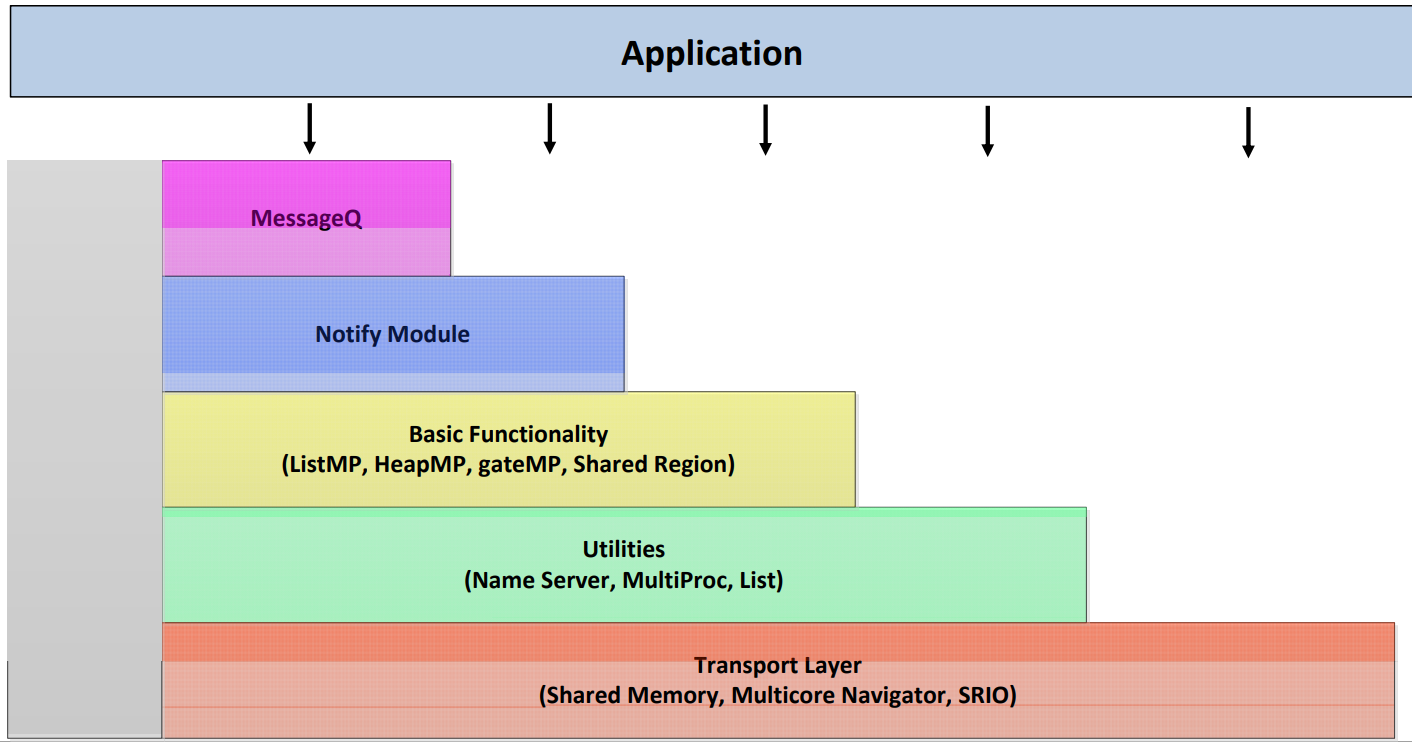
2.2常用模块
2.2.1MessageQ
该模块具有如下特点:
(1)兼容性强,可在不更改运行代码的情况移植至另一个支持TI-IPCMessageQ的处理器或其他传输层(如SharedMemory、MulticoreNavigator、SRIO)。
(2)支持可变长度消息的结构化发送与接收。
(3)单个MessageQ队列支持单个reader和多个writer。
(4)消息接收支持超时机制。
(5)reader可根据消息头部信息对writer进行确认后再回复。
(6)Ipc_start()会帮助用户完成下图中灰色框内的功能,用户仅需关注红色框中的内容即可。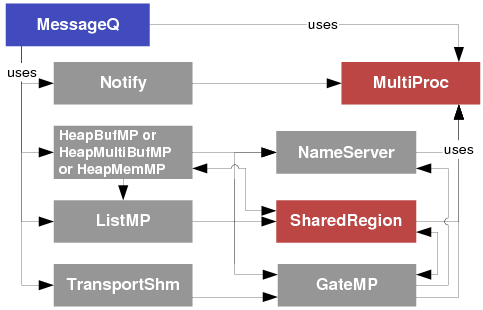
MessageQ通过消息队列发送和接收消息。reader是一个从消息队列中读取消息的线程,writer是一个将消息写入消息队列的线程。每个消息队列都有一个reader,但可有多个writer。
■reader:调用MessageQ_create()、MessageQ_get()、MessageQ_free()和MessageQ_delete()。
■writer:调用MessageQ_open()、MessageQ_alloc()、MessageQ_put()和MessageQ_close()。
MessageQ常见的工作流程如下所示。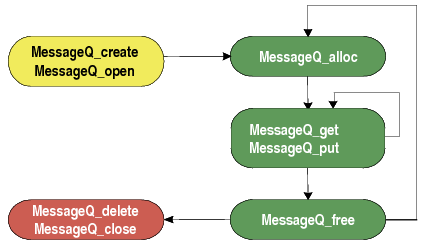
下面以多核IPC通信的shmIpcBenchmark案例为例,分析代码中MessageQ的使用,见图中注释。

2.2.2Notify
该模块具有如下特点:
(1)可独立于MessageQ模块进行使用。
(2)着重于多核通知功能,是更为简单的多核通信形式。
(3)仅可基于SharedMemroy方式进行使用。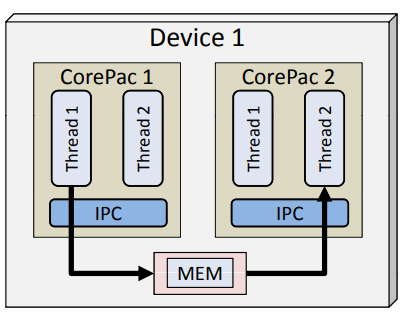
Notify通过硬件中断传输消息,Receiver注册Notify事件中断,Sender通过Notify发送事件中断,从而实现通知并携带小量消息的目的。
■Receiver:调用Notify_registerEvent()注册事件中断服务函数。
■Sender:调用Notify_sendEvent()发送事件中断。
Notify常见的工作流程如下所示。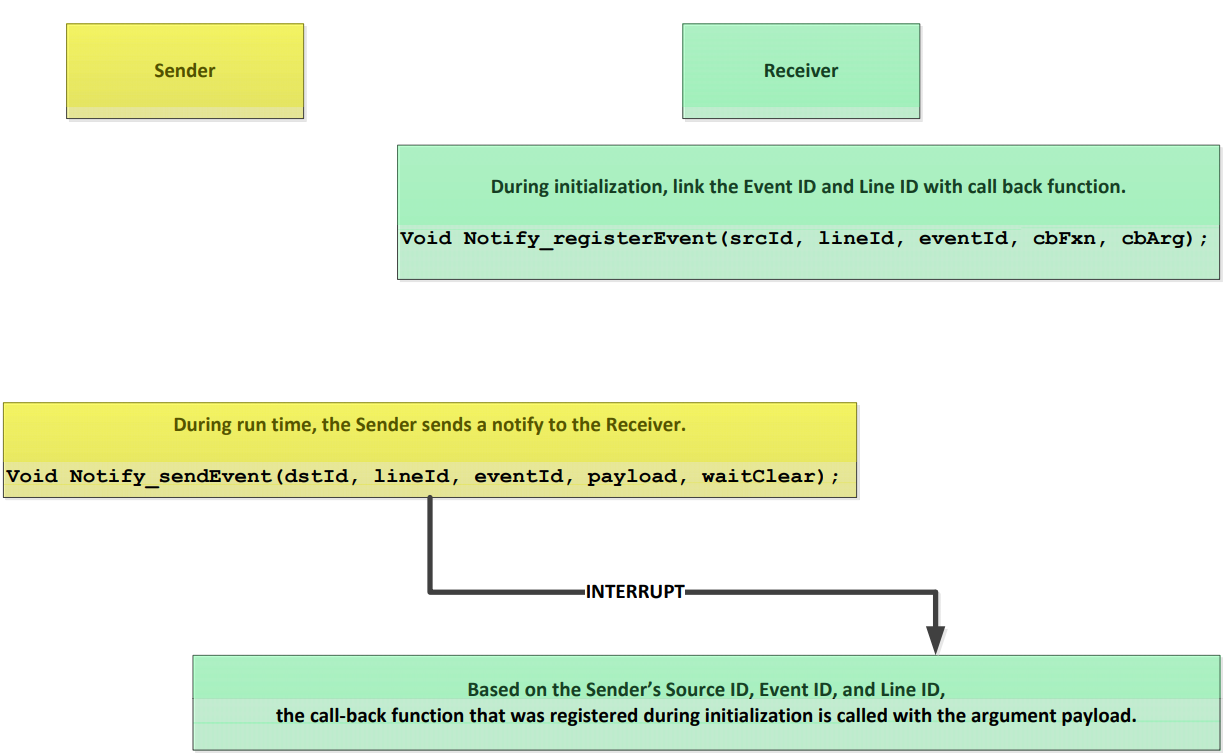
2.3物理传输方式
TI-IPC的数据传输需结合特定物理硬件与底层驱动,方可实现两个线程在同一个设备或跨设备间进行通信。常用三种的物理传输方式包括SharedMemory、MulticoreNavigator和SRIO,具体说明如下。
表2
| 传输方式 | 优点 | 缺点 |
| SharedMemory | 使用简单,速率较高 | 仅可用于单个设备IPC通信,可能与其他使用SharedMemory的任务存在竞争 |
| MulticoreNavigator | 速率最高,消耗CPU周期最少 | 仅可用于单个设备IPC通信 |
| SRIO | 可用于跨设备IPC通信 | 速率最低 |
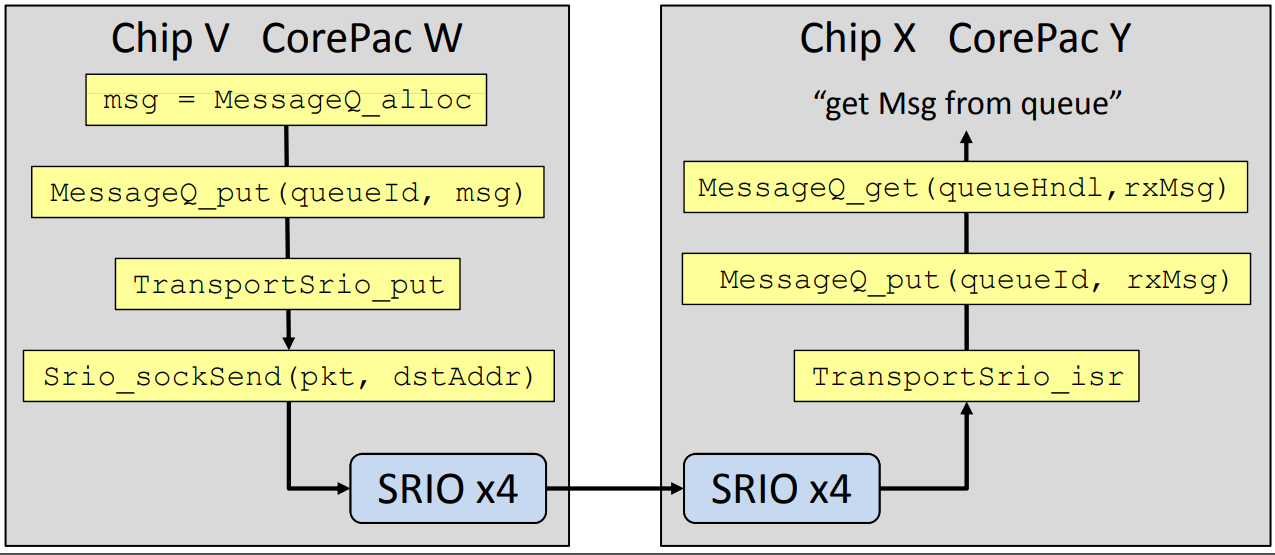
下图为使用MulticoreNavigator、SRIO的API调用流程,用户仅需关注MessageQ部分操作即可,其他模块均由系统自动调用。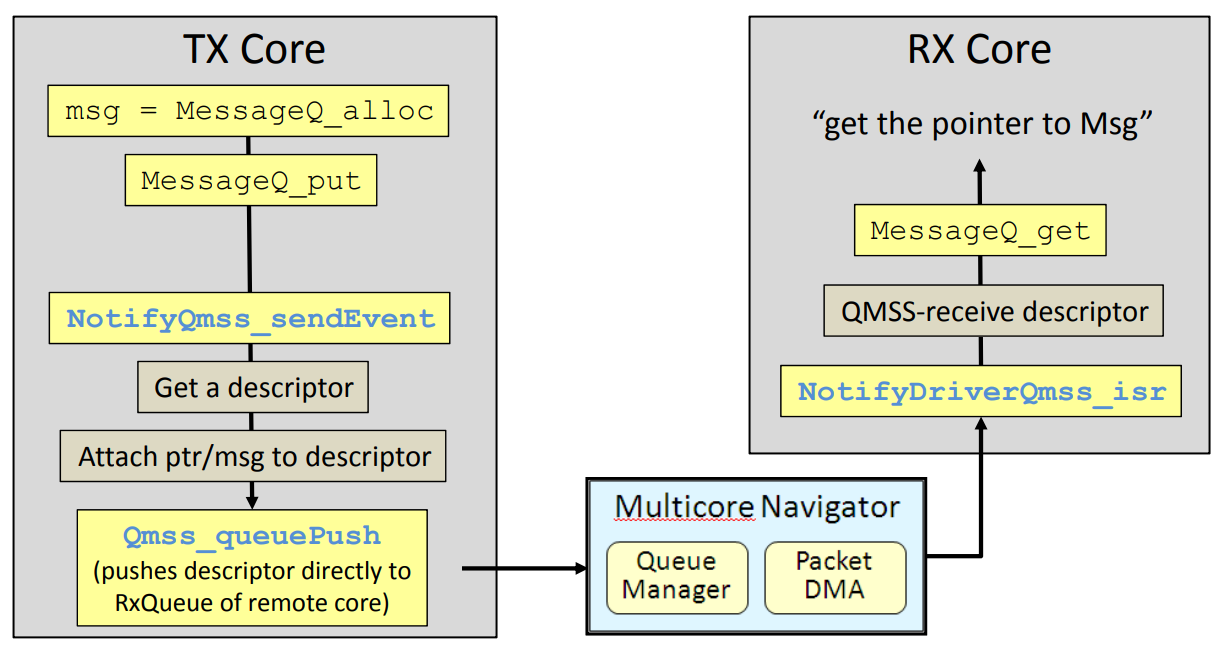
3OpenMP
3.1简介OpenMP是一种多核开发软件框架,其主要特性如下:
(1)可跨平台使用,代码兼容性强。
(2)以共享内存为通信基础。
(3)支持C++/C++以及Fortran语言。
(4)一般基于SYS/BIOS运行。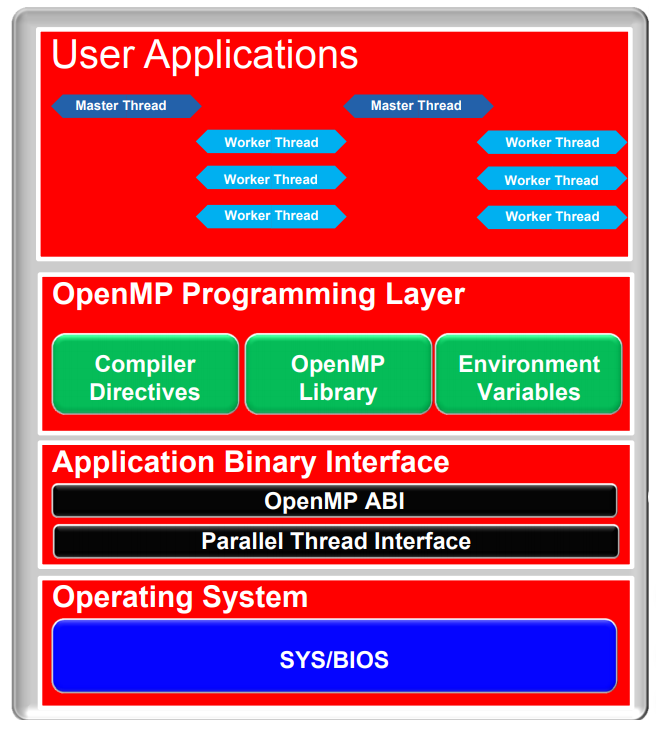
3.2基本语法
#pragmaomp指令[子句[[[,]子句]...]
{
...
}
表3
| 指令 | 说明 |
| parallel | 开始并行执行语句 |
| for | 在多个线程中并行执行for循环 |
| sections | 包含多个可并行执行的sectone结构体 |
| single | 单线程执行 |
| master | 主线程执行 |
| critical | 任意时刻仅可被单个线程执行 |
| barrier | 指定屏障,用于同步所有线程 |
| taskwait | 等待子线程完成 |
| atomic | 确保指定内存位置执行原子更新操作 |
| flush | 使线程当前内存数据与实际内存数据一致 |
| ordered | 并行执行的for循环将按循环体变量顺序执行 |
| threadprivate | 指定变量为本地存储 |
表4
| 子句 | 说明 |
| default | 控制parallel或task结构体中变量数据的共享属性 |
| shared | parallel或task结构中,一个或多个变量为共享变量 |
| private | 一个或多个变量为本地变量 |
| firstprivate | 一个或多个变量为本地变量,且变量值为并行结构执行前的值 |
| lastprivate | 一个或多个变量为本地变量,且变量值为并行结构执行后的值 |
| reduction | 一个或多个变量为本地变量,但变量值将根据不同的运算符来决定,执行完成后变量值将被更新 |
| copyin | 使线程本地变量值与主线程变量值相同 |
| copyprivate | 使属于parallel区域的变量值在不同线程中相同 |
| schedule | 设置for循环并行执行方式:dynamic、guided、runtime和static |
| num_threads | 线程数目 |
| if | 并行语句执行条件 |
| nowait | 忽略线程同步等待 |
以裸机的omp_matavec案例为例,使用场景的概要流程图如下。
C66xx_0核心创建主线程,通过OpenMP框架加载matvec算法至C66xx_0~C66xx_7核心进行并行运算,从而减少C66xx_0核心负载,并可加快运算速度。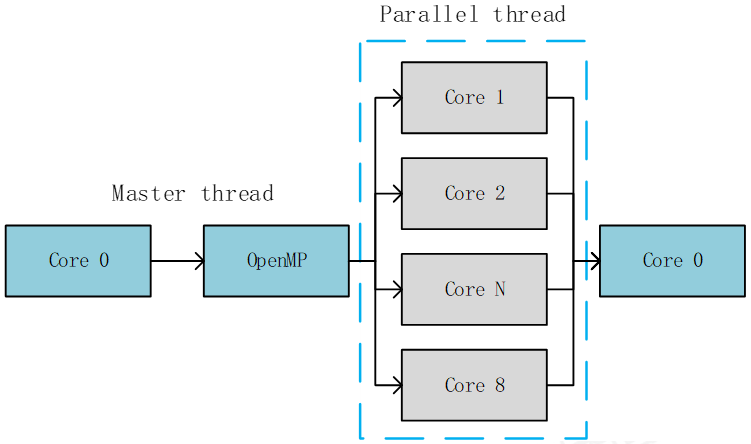
3.3代码分析
以裸机的omp_matavec案例为例进行代码分析,见图中注释。
4多核编程注意事项
4.1多核单/多镜像
在开发过程中,需将程序可执行文件分别加载至对应的核心运行。此时需了解多核单/多镜像的优缺点,再根据实际情况进行选择。
多核单镜像
多核单镜像指所有核心运行完全相同的用户程序。
优点:仅需维护一个工程,管理便捷。
缺点:需兼容多个核心代码,程序可执行文件较大。
多核多镜像
多核多镜像指不同核心运行不同的用户程序。
优点:无需考虑各核心功能的兼容性,单个程序可执行文件较小。
缺点:需维护多个工程,管理不便。
4.2外设访问
所有核心共享外设,如SRIO、PCIe、Ethernet、SPI、I2C、EMIF等。在对外设进行初始化后,所有核心可在任意时间对外设进行读写,无需再次初始化。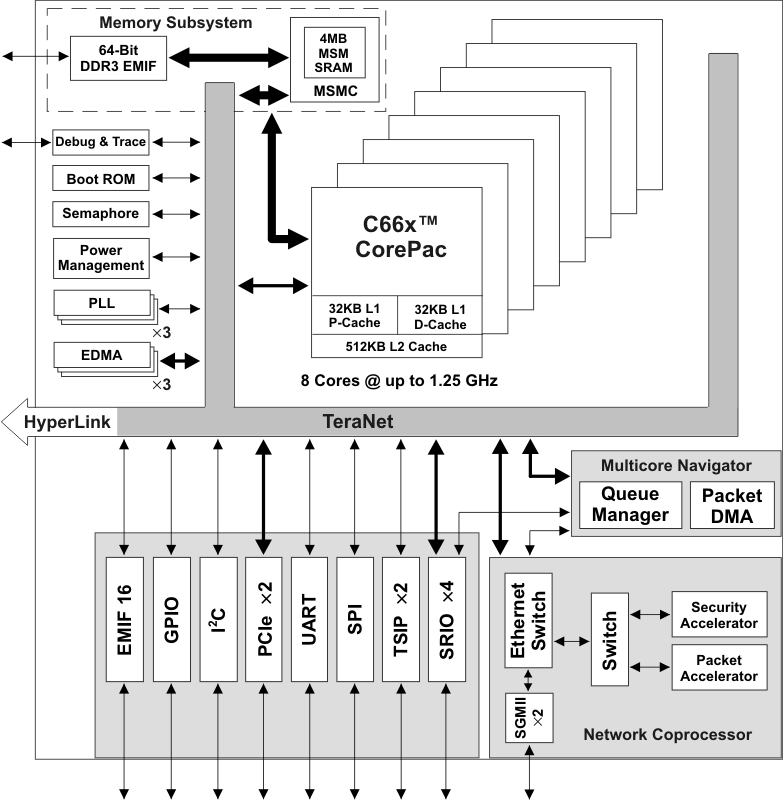
4.3数据存储
(1)注意区分全局与局部地址。
L1/L2SRAM有全局与局部两个地址,全局地址可被所有核心访问,但局部地址仅可被指定核心访问。
以C66xx_0核心的L2SRAM为例,对应的全局地址为0x10800000,局部地址为0x00800000。C66xx_0核心使用0x10800000或0x00800000,均可访问C66xx_0核心的L2SRAM。而C66xx_1核心使用0x00800000仅可访问C66xx_1核心的L2SRAM,使用0x10800000方可访问C66xx_0核心的L2SRAM。
L2SRAM全局与局部地址对应关系如下表:
表5
| 核心 | 全局地址 | 局部地址 |
| C66xx_0 | 0x10800000 | 0x00800000 |
| C66xx_1 | 0x11800000 | 0x00800000 |
| C66xx_2 | 0x12800000 | 0x00800000 |
| C66xx_3 | 0x13800000 | 0x00800000 |
| C66xx_4 | 0x14800000 | 0x00800000 |
| C66xx_5 | 0x15800000 | 0x00800000 |
| C66xx_6 | 0x16800000 | 0x00800000 |
| C66xx_7 | 0x17800000 | 0x00800000 |
(2)注意避免内存冲突。
如数据需存放至MSMCSRAM、ddr3共享内存设备,请将对应内存划分为MSMCSRAM_MASTER段(主核使用)与MSMCSRAM_SLAVE段(从核使用),从而避免运行时内存冲突。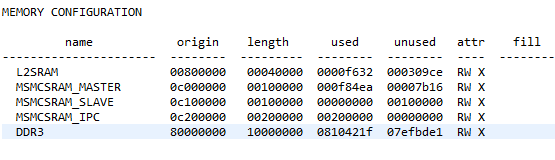
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

