
应用于工业和医疗领域的基于AI的系统,正越来越多地从研究项目和原型走向产品化阶段。这也就带来了专门针对边缘器件的关键需求,例如在低价格、低功耗和低时延下提高算力和性能。此外,AI科学家正在不断创新,旨在开发出更新颖的算法和模型,这就需要对不同的硬件架构进行优化。
赛灵思自适应计算加速平台(ACAP),可用于为一系列应用中的核心工业功能和医疗功能加速,如电动机控制(控制算法)、机器人(运动规划)、医疗成像(超声波束成型)等,但我们这次重点介绍AI。
赛灵思与当下AI发展
2018年收购深鉴科技(Deephi),加上Zynq®UltraScale+™MPSoC的自适应计算特质,赛灵思一跃成为AI推断领域的前沿厂商。Deephi曾发表全球首篇有关压缩和稀疏神经网络的论文文《深度压缩》(DeepCompression)。深度压缩这种方法能在不损失预测准确度的情况下成数量级地压缩神经网络(模型经深度压缩后,能加快推断速度3-4倍,提高能效3-7倍)。赛灵思ZynqUltraScale+MPSoC的核心组件包括应用处理器(Arm®Cortex-A53)、实时处理器(ARMCortex-R5)和可编程逻辑(PL)。这种平台能将压缩后的输出神经网络部署在PL中实现的深度学习单元(DPU)上,为压缩后的神经网络提速,使之发挥出更高性能。因为DPU实现在PL中,它的大小可以根据不同的并行化程度进行改变,并且还可以根据您选择的平台中可用的硬件资源,部署为单核、双核或三核甚至更多。
2017年,为进一步发挥自适应计算能力,赛灵思发布了INT8DPU,从浮点(FP32)变为整数(INT8),在保持良好精度的同时,大大节省了内存、存储空间和带宽。
接下来,一个严重的问题出现了:在工作中使用大量深度学习框架(TensorFlow、Caffe、Darknet等)的AI科学家希望在赛灵思产品组合中尝试多种硬件平台,为他们的用例找到最佳方案。此外,他们还希望在开发工作中使用他们最熟悉的语言。为此,2019年,赛灵思推出了名为ViTIsAI™的统一软件平台工具来满足上述需求。开发者通过该平台,可以使用常见的编程语言处理常见深度学习框架中的各种模型,而且能够支持从边缘到云任何器件的产品。此外,ViTIsAI自带50多种预训练、预优化的开源AI模型(赛灵思ModelZoo),可以用定制数据集进行再训练,与其他从头开始培训和优化模型的方案相比,ViTIsAI有利于AI软件开发者从一个更高的起点启动设计。
赛灵思面向当今AI应用的“六把刀”:
·减少资源的使用–较低精度(INT8)的压缩神经网络能减少DSP、查找表(LUT)的使用,并降低存储器占用
·降低功耗–资源使用量的减少自然有利于降低功耗
·减小BOM成本–在成本不变的情况下使用更多的可用资源,含外部功能
·支持深度学习框架–包括Caffe、PyTorch和TensorFlow
·统一的开发工具–使用赛灵思ViTIs和VitisAI,支持从边缘到云端的任意器件开发
·最大限度不更改AI软件开发者的基本工作流程
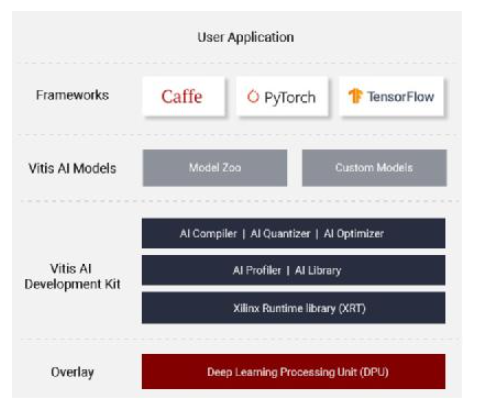
面向赛灵思硬件平台AI推断开发的赛灵思VitisAI开发平台
赛灵思与未来的AI
作为当今AI领域扮演重要角色的技术提供商,赛灵思通过自己的硬件平台提供自适应计算能力,持续为塑造AI的未来而不懈努力。其中两项赛灵思正在开发的多种未来自适应计算方法包括:
·INT4DPU
·FINN–高速可扩展的量化神经网络推断
注释:本节中讨论的方法目前还没有被赛灵思产品化,在本文中讨论的目的是展现赛灵思硬件平台的自适应计算功能。
A.INT4DPU
INT8在AI推断方面提供了比浮点运算显著提高的性能。展望边缘计算在未来的性能要求,我认为需要在降低或保持资源需求的前提下提高性能并降低时延,这样一来INT4优化将成为必然,届时,硬件性能可以随着时间的推移而不断改进。从INT8DPU升级到INT4DPU,已经在现场完成部署的现有赛灵思器件,能在减少逻辑和片上存储器占用同时,实现高达77%的性能提升。
在INT4DPU上部署神经网络的第一步是实现整个量化过程的硬件友好。INT4量化方法可以划分为三类:
1.量化机制
2.量化设计硬件友好度
3.量化感知训练
赛灵思使用量化感知训练(QAT)。为有效改善低比特与全精度神经网络的精度差异提供了关键技术。QAT选用的算法是逐层量化感知训练。这种方法可以用于图像分类、姿态估计、2D与3D检测、语义分割和多任务处理。
在其他开发流程保持不变的基础上,用户只需将导入训练后的模型通过赛灵思VitisAI运行,最终生成可为目标平台部署的模型。除了已经介绍过的更低比特推断带来的如降低资源占用、降低功耗、降低BOM成本,支持常见的深度学习框架和编程语言等优势外,相比于INT8,INT4DPU还能带来2倍到15倍的性能提升。
B.FINN
赛灵思研究实验室在2017年发表了第一篇有关FINN项目的论文,讨论了第二代FINN框架(FINN-R),这种端到端工具提供设计空间探索,并支持在赛灵思硬件平台上自动完成全定制推断引擎的创建。
与VitisAI相似,FINN-R支持多种常见的深度学习框架(Caffe、TensorFlow、DarkNet)并允许用户以边缘和云端的多种硬件平台为开发目标(Ultra96、PYNQ-Z1和AWSF1实例)。
FINN-R有一个主要目标:针对给定的设计约束集和专门的神经网络,找出可以实现的最佳硬件实现方案并自动完成此目标,以便用户立即在他们的赛灵思硬件平台上获得由此带来的优势。FINN-R如何达成这个目标?方法是完整的推断加速器架构选择和FINN-R工具链。用户有两种不同的架构可供选择:
一种是为用户的神经网络量身定制的架构,称作数据流架构(DF);另一种则是数据流流水线架构(MO),用于卸载相大部分的计算负载并通过流水线迭代。
FINN-R工具链的构成包括前端、中间表达和后端。它导入量化神经网络(QNN)并为DF和MO架构输出部署包。如今的FINN-R能够为BinaryNet、Darknet、Tensorpack提供前端,而且更重要的是,由于它的模块性质,通过添加额外的前端它就能为新出现的QNN框架提供支持。用户可以随意选择部署包,只要保证选择的部署包在自己的设计约束下是最佳硬件实现方案。
FINN和INT4DPU的主要差别在于FINN可以为任何低比特神经网络生成定制化硬件实现方案,其中的权重、激活函数和层数可以有不同精度。此外,FINN还丰富的定制空间,如层数和运算符。这对于在给定的硬性设计约束条件下优化设计性能非常有价值。另一方面,就常见的深度学习框架而言,INT4DPU的模型推断加速性能比今天的INT8DPU高77%,而且在硬件资源固定的条件下,能将模型部署到从边缘到云端的任何器件上。这两个流程进一步丰富了用户运用赛灵思平台加速推断、打造AI未来的大量应用选择。
结论
AI和机器学习的重要性毋庸置疑。固定架构确实可以很好地满足当今某些应用场景,然而展望未来,机器学习的模型和它们的需求在不断变化,新的、未知的需求也在不断涌现。而无论如何变化,这些模型也将不断基于需求变化。赛灵思的自适应计算加速平台既能满足了当今的AI需求,也能自适应不断演进发展的AI未来需求。也就是说,借助计算平台,可以支持AI开发者立足当下开展设计,同时通过可以应对未来变化的嵌入式平台为未来的AI布局做好准备。现在我要拿出我的瑞士军刀,开一罐豆子当晚餐。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

