
如果在没有嵌入式处理器供应商提供的合适工具和软件的支持下,既想设计高能效的边缘人工智能(AI)系统,同时又要加快产品上市时间,这项工作难免会冗长乏味。面临的一系列挑战包括选择恰当的深度学习模型、针对性能和精度目标对模型进行训练和优化,以及学习使用在嵌入式边缘处理器上部署模型的专用工具。
从模型选择到在处理器上部署,TI可免费提供相关工具、软件和服务,为您深度神经网络(DNN)开发工作流程的每一步保驾护航。下面让我们来了解如何不借助手动工具或手动编程来选择模型、随时随地训练模型并将其无缝部署到TI处理器上,从而实现硬件加速推理。
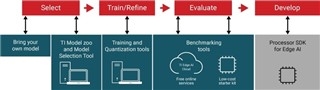
图1: 边缘AI应用的开发流程
第1步:选择模型
边缘AI系统开发的首要任务是选择合适的DNN模型,同时要兼顾系统的性能、精度和功耗目标。GitHub上的TI边缘AI Model Zoo等工具可助您加速此流程。
Model Zoo广泛汇集了TensorFlow、PyTorch和MXNet框架中常用的开源深度学习模型。这些模型在公共数据集上经过预训练和优化,可以在TI适用于边缘AI的处理器上高效运行。TI会定期使用开源社区中的新模型以及TI设计的模型对Model Zoo进行更新,为您提供性能和精度经过优化的广泛模型选择。
Model Zoo囊括数百个模型,TI模型选择工具(如图2所示)可以帮助您在不编写任何代码的情况下,通过查看和比较性能统计数据(如推理吞吐量、延迟、精度和双倍数据速率带宽),快速比较和找到适合您AI任务的模型。
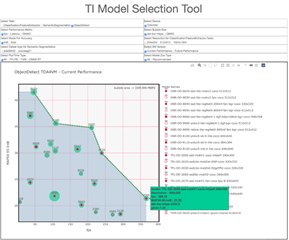
图2:TI 模型选择工具
第2步:训练和优化模型
选择模型后,下一步是在TI处理器上对其进行训练或优化,以获得出色的性能和精度。凭借我们的软件架构和开发环境,您可随时随地训练模型。
从TI Model Zoo中选择模型时,借助训练脚本可让您在自定义数据集上为特定任务快速传输和训练模型,而无需花费较长时间从头开始训练或使用手动工具。训练脚本、框架扩展和量化感知培训工具可帮助您优化自己的DNN模型。
第3步:评估模型性能
在开发边缘AI应用之前,需要在实际硬件上评估模型性能。
TI提供灵活的软件架构和开发环境,您可以在TensorFlow Lite、ONNX RunTime或TVM和支持Neo AI DLR的SageMaker Neo运行环境引擎三者中选择习惯的业界标准Python或C++应用编程接口(API),只需编写几行代码,即可随时随地训练自己的模型,并将模型编译和部署到TI硬件上。在这些业界通用运行环境引擎的后端,我们的TI深度学习(TIDL)模型编译和运行环境工具可让您针对TI的硬件编译模型,将编译后的图或子图部署到深度学习硬件加速器上,并在无需任何手动工具的情况下实现卓越的处理器推理性能。
在编译步骤中,训练后量化工具可以自动将浮点模型转换为定点模型。该工具可通过配置文件实现层级混合精度量化(8位和16位),从而能够足够灵活地调整模型编译,以获得出色的性能和精度。
不同常用模型的运算方式各不相同。同样位于GitHub上的TI边缘AI基准工具可帮助您为TI Model Zoo中的模型无缝匹配DNN模型功能,并作为自定义模型的参考。
评估TI处理器模型性能的方式有两种:TDA4VM入门套件评估模块(EVM)或TI Edge AI Cloud,后者是一项免费在线服务,可支持远程访问TDA4VM EVM,以评估深度学习推理性能。借助针对不同任务和运行时引擎组合的数个示例脚本,五分钟之内便可在TI硬件上编程、部署和运行加速推理,同时收集基准测试数据。
第4步:部署边缘AI应用程序
您可以使用开源Linux®和业界通用的API来将模型部署到TI硬件上。然而,将深度学习模型部署到硬件加速器上只是难题的冰山一角。
为帮助您快速构建高效的边缘AI应用,TI采用了GStreamer框架。借助在主机Arm®内核上运行的GStreamer插件,您可以自动将计算密集型任务的端到端信号链加速部署到硬件加速器和数字信号处理内核上。
图3展示了适用于边缘AI的Linux Processor SDK的软件栈和组件。
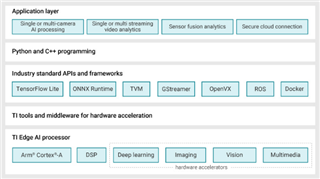
图3:适用于边缘AI的Linux Processor SDK组件
结语
如果您对本文中提及的工具感到陌生或有所担忧,请放宽心,因为即使您想要开发和部署AI模型或构建AI应用,也不必成为AI专家。TI Edge AI Academy能够帮助您在自学、课堂环境中通过测验学习AI基础知识,并深入了解AI系统和软件编程。实验室提供了构建“Hello World” AI应用的分步代码,而带有摄像头捕获和显示功能的端到端高级应用使您能够按照自己的节奏顺利开发AI应用。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

