
介绍
此页面可帮助您在Raspberry Pi或Google Coral或Jetson Nano等替代品上构建深度学习模式。有关深度学习及其限制的更多一般信息,请参阅深度学习。本页更多地介绍一般原则,因此您可以很好地了解它的工作原理以及您的网络可以在哪个板上运行。有关软件安装的分步方法,请参见 Raspberry Pi 4 和替代品的深度学习软件。
Tensor
一个广泛使用的深度学习软件包是TensorFlow。让我们从名称开始。什么是tensor?
你可以有一个数字列表。这在数学中称为向量。
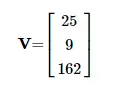
如果向此列表添加维度,则会得到一个矩阵。
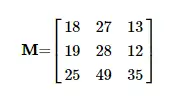
例如,通过这种方式,您可以显示黑白图像。每个值代表一个像素值。行数等于高度,列数与图像的宽度匹配。如果你再次向矩阵添加一个额外的维度,你会得到一个tensor。

彼此重叠的 2D 矩阵堆栈。或者换句话说,一个矩阵,其中各个数字被一个向量所取代,一个数字列表。例如 RGB 图片。每个单独的像素(矩阵中的元素)由三个元素组成;一个 R、G 和 B 分量。 这是tensor(n维数字数组)的最简化定义。

TensorFlow和数学中的张量之间的定义存在细微差异。
在数学中,tensor不仅仅是矩阵中的数字集合。在这里,tensor必须遵守某些变换规则。这些规则与在不改变其结果的情况下改变tensor所在的坐标系有关。大多数tensor都是 3D 的,并且具有与 Rubric 立方体相同数量的元素。每个单独的立方体通过一组正交向量预测物理对象在应力(tensor)下将如何变形。
如果观察者在现实世界中占据另一个位置,物体本身的变形不会改变;显然,它仍然是同一个对象。但是,给定此新位置,所有向量或公式都将更改。它们将以变形的结果保持不变的方式发生变化。可以把它想象成两座塔顶之间的距离。无论你站在哪里,这都不会改变。然而,从你的位置到这些顶部绘制矢量会根据你的位置、你的原点而变化。
在tensor的上下文中,甚至还有第三个含义,即神经tensor网络。
这个特殊神经网络中的tensor在两个实体之间建立了关系。狗有尾巴,狗是哺乳动物,哺乳动物需要氧气等。
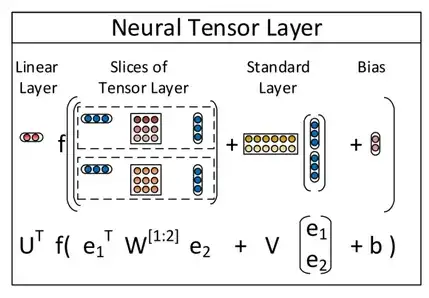
最后两个定义只是为了完整起见而给出的。许多人认为TensorFlow与这些解释之一有关。事实并非如此。
重量矩阵
TensorFlow和其他深度学习软件最重要的构建块是n维数组。本节介绍这些数组的用法。每个深度学习应用程序都由给定的神经节点拓扑组成。每个神经节点通常构造如下。
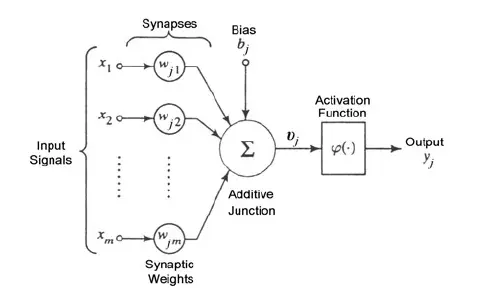
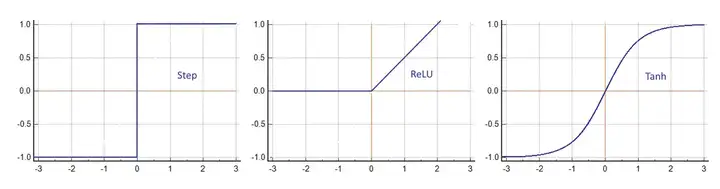
每个输入乘以一个权重并相加。与偏差一起,结果进入激活函数φ。这可以是简单的步进运算,也可以是更复杂的函数,例如双曲正切。
输出是网络中下一层的输入。网络可以由许多层组成,每层都有数千个单独的神经元。
如果您查看一个层,则相同的输入数组可以应用于不同的权重数组。每个都有不同的结果,以便可以从单个输入中提取各种特征。
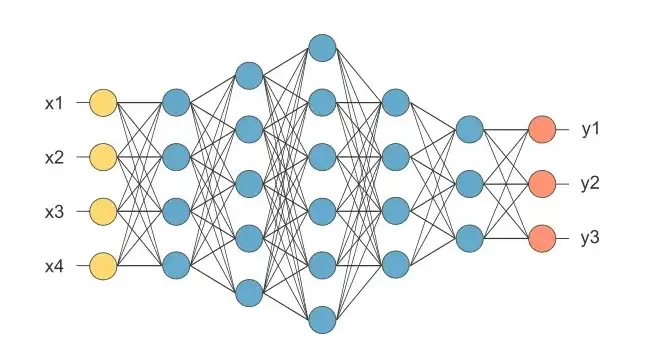
在上面的网络中,四个输入(黄色)都完全连接到第一层的四个神经元(蓝色)。它们连接到下一层的五个神经元。跟随另一个由六个神经元组成的内层。经过连续两层四层和三层后,达到具有三个通道的输出(橙色)。
这样的方案导致向量矩阵乘法。
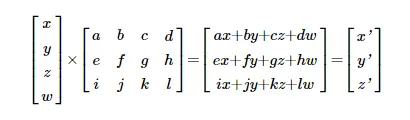
这里,四个值(x,y,z,w)的输入层与权重矩阵相乘。x 输入的权重 a,b,c,d,导致输出端出现 x'。y' 输出的权重 e,f,g,h 等。还有其他方法可以描述这种乘法,例如,
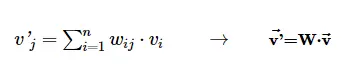
其中 v 是输入向量 (x,y,z,w),v' 是输出 (x',y',z')。 向量矩阵乘法是 TensorFlow 中执行最多的操作之一,因此得名。
GPU
在将所有点放在一起之前,首先在 GPU 硬件中绕道而行。GPU 代表图形处理单元,一种最初设计用于将 CPU 从沉闷的屏幕渲染任务中解放出来的设备。 多年来,GPU变得更加强大。如今,它们拥有超过21亿个晶体管,能够执行大规模的并行计算。 特别是在计算屏幕上每个像素的游戏中,需要这些计算能力。 移动查看器的位置时,例如,当英雄开始运行时,必须重新计算所有顶点。而这每秒25次以获得平滑过渡。每个顶点都需要旋转和平移。公式为:
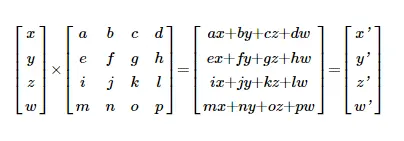
这里 (x,y,z,w) 是 3D 中的初始像素位置,(x',y',z',w') 是矩阵运算后的新位置。如您所见,这种类型的算术与神经网络相同。还有另一个兴趣点。当你看x'时,它是四个乘积(ax+by+cz+dw)的总和。另一方面,y' 也是一个求和 (ex+fy+gz+hw)。但是要计算y',不需要知道决定x'(a,b,c和d)的值。它们彼此无关。您可以同时计算 x'和 y'。还有 z' 和 w' 就此而言。理论上,与其他结果没有关系的每个计算都可以同时执行。因此,GPU 的非常并行的架构。当今(2023 年)最快的 GPU 每秒能够达到惊人的 125 TFLOP。
这就是 GPU 加速背后的整个想法。将所有张量传输到 GPU 内存,并让设备在花费 CPU 的一小部分时间内执行所有矢量矩阵计算。如果没有令人印象深刻的GPU计算能力,深度学习几乎是不可能的。
TPU
在深度学习的巨大市场潜力的推动下,一些制造商将GPU替换为TPU,即Tensor处理单元。除了矢量矩阵乘法,GPU 还有其他任务要做,例如顶点插值和着色、H264 压缩、驱动 HDMI 显示器等。通过仅将所有晶体管用于Tensor点积,吞吐量增加,功耗降低。第一代仅适用于 8 位整数,后者也适用于浮点数。下面嵌入式板上的 TPU 都是基于整数的,除了 Jetson Nano。在此处阅读深入的文章。
GPU陷阱
关于 GPU 算术,必须考虑几点。
首先,坚持矩阵。GPU 架构专为这种操作而设计。编写一个广泛的 if-else 结构对于 GPU 和整体性能来说是灾难性的。
另一点是内存交换会消耗很多效率。越来越多的数据从CPU内存(图像通常所在的位置)和GPU内存的数据传输正在成为一个严重的瓶颈。您在 NVIDIA 的每个文档中一遍又一遍地阅读相同的内容;矢量矩阵点积越大,执行速度越快。
在这方面,请记住,Raspberry 及其替代品通常有一个用于 CPU 和 GPU 的大 RAM。它们仅共享相同的 DDR4 芯片。您的神经网络不仅必须适合程序内存,而且还必须在 RAM 中留出空间,以便 CPU 内核可以运行。这有时会对网络或要识别的对象数量施加限制。在这种情况下,选择另一块具有更多 RAM 的电路板可能是唯一的解决方案。所有这些都与GPU具有内存库的PC中的图形卡形成鲜明对比。
另一个区别是视频卡上的 GPU 使用浮点或半浮点,有时也称为小浮点。树莓上的嵌入式 GPU 或替代板上的 TPU 使用 8 位或 16 位整数。您的神经网络必须适应这些格式。如果无法做到这一点,请选择另一个具有浮点运算的板,例如 Jetson Nano。
最后一个建议,不要过多地超频 GPU。它们以低于 CPU 的频率正常工作。ARM内核中的一些Mali GPU运行低至400 MHz。 超频可以在冬季工作,但应用程序可能会在仲夏动摇。请记住,突然崩溃的是您在客户端的视觉应用程序,而不是您简单地重新启动游戏。
当然,页面上关于Raspberry上计算机视觉的评论也适用于这里。
Showstopper
您不能在 Raspberry Pi 或替代方案上训练深度学习模型。如果您没有计划环游世界,则不会。这些板缺乏计算机能力来执行训练期间所需的大量浮点多加法。即使是Google Coral也无法训练网络,因为该板上的TPU仅适用于特殊的预编译TensorFlow网络。只有网络中的最后一层可以稍作更改。尽管Jetson Nano具有浮点CUDA,但它仍然不能很好地在可接受的时间内训练网络。一夜之间完成是NVIDIA在这里的建议。因此,最后,您只能在这些板上导入并运行已训练的模型。
云服务
如前所述,训练不是Raspberry Pi的选项,也不是任何其他小型SBC的选择。但是,有一条逃生路线。所有主要的科技公司都有云服务。其中许多还包括运行配备 GPU 的 Linux 虚拟机的选项。现在,您拥有了触手可及的 CUDA 加速的最先进的 CPU。最好的免费服务之一是谷歌,GDrive 上有 15 GB 的免费空间,每天至少有 12 小时的免费计算机时间。现在,只需一个简单的 Raspberry Pi 就可以在一定程度上训练您的深度学习模型。转移训练(部分调整重量而不改变拓扑)是可行的,因为这是一项相对容易的任务,您可以在几个小时内完成。另一方面,训练复杂的 GAN 需要更多的资源。它可能会迫使您购买额外的电力。
实践
第一步是安装操作系统,通常是Linux的衍生产品,如Ubuntu或Debian。这是容易的部分。
困难的部分是安装深度学习模型。您必须弄清楚是否需要任何其他库(OpenCV)或驱动程序(GPU支持)。请注意,只有 Jetson Nano 支持 CUDA,这是 PC 上使用的大多数深度学习软件包。如果您想加速神经网络,所有其他板都需要不同的 GPU 支持。Raspberry Pi 或替代方案的 GPU 驱动程序的开发是一个持续的过程。查看网络上的社区。
最后一步是将神经网络降低到可接受的比例。著名的 AlexNet 每 帧具有原始的 2 .3亿次浮点运算。这永远不会在简单的单个 ARM 计算机或移动设备上快速运行。大多数模型都有某种减少策略。YOLO有Tiny YOLO,Caffe有Caffe2,TensorFlow有TensorFlow Lite。它们都使用以下一种或多种技术。
减小输入大小。较小的图像在第一层上节省了大量计算。
减少要分类的对象数量;它修剪了许多内层的大小。
尽可能将神经网络从浮点数移植到字节。这也大大降低了内存负载。
另一种策略是将浮点数减少到单个比特,即XNOR网络。 这里讨论了这个迷人的想法。
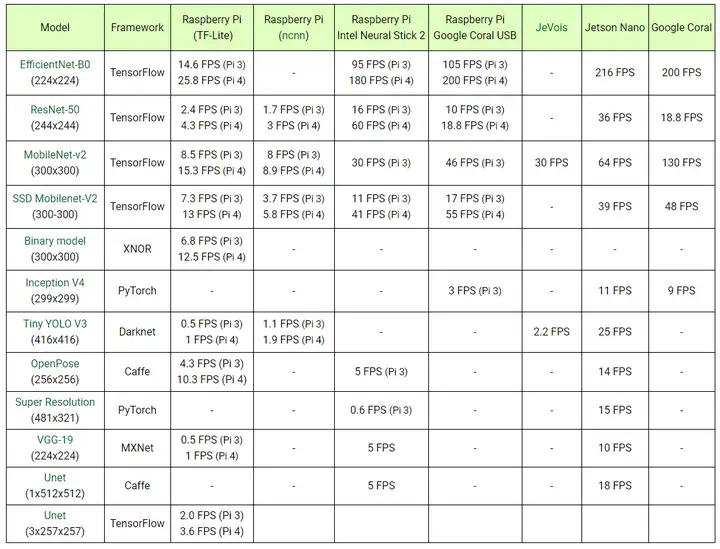
树莓派和替代品的比较。
Jetson Nano vs Google Coral vs Intel Neural stick,这里是比较。列表中的三个奇怪的是JeVois,Intel Neural Stick和Google Colar USB加速器。第一个有一个板载摄像头,可以做很多事情,你可以在这里阅读。
Intel Neural Stick和Google Colar 加速器是带有特殊 TPU 芯片的 USB 加密狗,可执行所有Tensor计算。Intel Neural Stick附带一个工具集,用于将 TensorFlow、Caffe 或 MXNet 模型迁移到神经棒的工作中间表示 (IR) 图像中。
Google Coral与特殊的预编译TensorFlow Lite网络配合使用。如果神经网络的拓扑及其所需的操作可以在TensorFlow中描述,那么它可能在Google Coral上运行良好。但是,由于其少量的 1 GB RAM,内存短缺仍然是一个问题。
Google USB加速器具有特殊的后端编译器,可将TensorFlow Lite文件转换为加密狗TPU的可执行模型。
Jetson Nano是唯一具有浮点GPU加速功能的单板计算机。它支持大多数模型,因为所有框架如TensorFlow,Caffe,PyTorch,YOLO,MXNet和其他在给定时间都使用的CUDA GPU支持库。价格也非常有竞争力。这与蓬勃发展的深度学习市场有关,英伟达不想失去其突出地位。
并非所有型号都可以在每台设备上运行。大多数情况下是由于内存不足或硬件和/或软件不兼容。在这些情况下,可以使用多种解决方案。但是,它们的开发将非常耗时,并且结果通常会令人失望。
Benchmarks总是需要讨论的。有些人可能会发现其他 FPS 使用相同的模型。这一切都与所使用的方法有关。我们使用Python,NVIDIA使用C++,谷歌使用他们的TensorFlow和TensorFlow Lite。Raspberry Pi 3 B+具有板载2.0 USB接口。两种神经棒都可以处理3.0,这意味着它们可以更快地执行。另一方面,新的Raspberry Pi 4 B具有USB 3.0,与其前身相比,这将导致更高的FPS。
表中显示的数字纯粹是从输入到输出执行所需的时间。不考虑其他过程,例如捕获和缩放图像。顺便说一下,不使用超频。
树莓派和深度学习
我们在 GitHub 上放置了一个深度学习库和几个深度学习网络。结合简单的C++示例代码,您可以在裸露的树莓派上构建深度学习应用程序。它非常用户友好。此页面上的更多信息。

上面是在裸树莓派上运行的 TensorFlow Lite 模型(带有 COCO 训练集MobileNetV1_SSD 300x300)的印象。
使用像 Ubuntu 这样的 64 位操作系统,如果您超频到 24 FPS,您将获得 1925MHz 。
使用像Raspbian这样的常规32位系统,一旦超频到17FPS,您将获得2000MHz 。
树莓派和最近的替代品
下面在Raspberry Pi和适合实现深度学习模型的最新替代方案之间进行选择。 大多数芯片上都有广泛的GPU或TPU硬件。请注意,报价是从 2023 年 1 月开始的,即全球芯片严重短缺之前的价格。GPU 速度以 TOPS 表示,代表 Tera Operations P er Second。当然,最高分将是当您使用 8 位整数时。大多数供应商给出这个 8 位分数。如果你想在TFLOPS(Tera Floating Operations Per S econd)中有一个印象,请将数字除以四。虽然有些GPU不能处理单个8位,比如Jetson Nano,但分数仍然在TOPS,只是出于比较的原因。
















单个微型 (40x48 mm) 可插拔模块,具有完整的 I/O 和Edge TPU加速器。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

