
1 前言
这篇是为了公司内部的技术分享而准备的材料,当然在公司内部,如果我敢从2008年开始讲,早就被打死了。还有,就是NDA的内容肯定是略略略了。
如果让我用一句话总结我这些年做Arm服务器的心路历程,那就是 “筚路蓝缕,以启山林”。
2 第一波浪潮(2008-2013)
Arm服务器的第一波浪潮,是一家叫Calexda开始,也是由它结束的。虽然我觉得2011的官宣Armv8架构,就是32bit 服务器的终结。但是第一波的浪潮的起伏,并不仅仅是32bit,64bit 那么简单,还有一个词Microserver,微服务器。也是当时产业界,包括x86阵营的共同探索。技术上,商业逻辑上,都不错的产品,在市场上,没有成功。
我个人得到的一个观察:服务器市场是个求稳的保守的市场,相对于活跃的终端市场。
2.1 启程 2008
Calxeda的一开始目标就是 降低数据中心的耗能,并且提高相同空间的计算力密度。请记住这两个目标,此时此刻,我们的初心依旧。
那一年市面上还是Cortex-A8的产品,而基于第一款多核Ccortex-A9的产品要到3年后才上市。(好怀念那个2,3年才发布一款产品的慢速时代)。
那时Intel的Xeon还是4个核,当然主频已经3.xGhz了,而AMD的45nm Opteron CPU也刚刚上市。
那一年IBM刚刚宣布Power产品线,而且上来就高山仰止的高达64个核。
苹果发布了iPhone 3G,就是iPhone2。(对,那时还是3G时代。)
2.1.1 Calxeda 2011
2010年Smooth Stone正式改名字为Calxeda,把总部搬到了Austin。
2011年 Calxeda发布它的芯片基于A9的芯片EnergyCore ECX-1000。
图2.1 CalexdaEnergyCore架构
这其实是一个值得细看的一款设计,4核cortex-a9组成的处理器模块,比较中规中矩,I/O controllers部分也是常规接口(常规接口并不容易,一个好产品的核心是常规部分做到业界一流)。但是管理引擎(management engine)和交换引擎(Fabric Switch)部分就是技术非常创新之举。
EnergyCore Fabric是一个集成的L2 switch支持mesh, butterfly tree, 2D Torus拓扑,虚拟端口之间的带宽可以按1 Gb/sec, 2.5Gb/sec, 5 Gb/sec, 核10 Gb/sec的不同规格分配。通过它,服务器节点可以自己自主成网,不必通过on top switch,因此Calexda的一块板块上有4个芯片,也就是16个核心。因此才有可以高达480个核的服务器系统。
这个设计理念是合理的,如果你设计一块非常低成本的服务器芯片,但是配套的网络仍然是昂贵的话,高密度的设计,只会增加成本。这个fabric可以将1024个系统板,也就是4096个芯片用10G网络接口,集联为系统。
EnergyCore ManagementEngine是一个集成BMC,支持IMP2.0和DCMI,还支持远程调试SoL协议。管理引擎最强的地方在于功耗管理,Calexda这款服务器芯片的功耗可以从4w到1w动态调整。

图2.2 4个节点的Calexda系统板
2011年,我加入Arm网络市场部。那时我关注的是还在设计阶段的LSI Axxia AXM5500 16-core ARMCortex-A15, Freescale 的QorIQ Layerscape 系列,TI的KeyStone,还有海思的hixxxx系列,那真是一个Arm在网络市场大爆发的时代。但是很快,一年后,我跟着当时的老板,一位有电影明星气质的印度裔资深美女,从网络市场转为服务器市场,从那时到现在,全心全意的投入服务器市场与生态建设。
2.2 Computex 2012
2012年,Ian Ferguson在台北Computex上的公开演讲,大约是Arm第一次向公众介绍服务器方面的努力。和他一起站台的是Ubuntu的Mark(软件生态是个大话题,本文主要集中在芯片方面,系统硬件设计和软件话题另外开文再说)。他引用了Facebook的 Frank说的 performance per watt per dollar的价值观。
提到Arm服务器,Ian Ferguson必须有姓名(他教我了一句做市场工作的最基本的一句话,“你是打算report news,还是make news?”,现在我也愿意和小伙伴一起说,来来来,我们一起搞事情。)如他在大会上的发言,从Arm打算考虑服务器市场的第一天起,整个业界都充满了怀疑的论调。不仅仅怀疑是否能成功,甚至从根上,怀疑动机。
这些问题,我并不着急回答,如果你有耐心读到最后,一切都自有答案。
2.3 Marvell Armada XP 2013
在第一波服务器浪潮中,Marvell Armada XP 四核系列,也是要提到的。而且这里的core,不是A9,也不是A15,是Marvell的custom Core。
也是因为Armada,我把什么叫架构授权,回答得滚瓜烂熟。
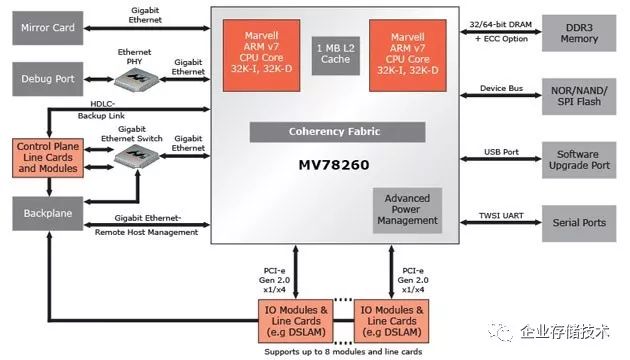
图2.3 MarvellArmada XP
这款集成度很高,功耗低的SoC非常适合存储应用。Dell以此为核心,出了“Copper”的arm服务器系统。百度也曾经使用过。这是Arm服务器在互联网公司的第一个案例。
2.4 Calxeda 倒闭 2013
它的结业邮件中说,因为Arm服务器的出现,“the industry will be transformed forever”。从现在看,是的。
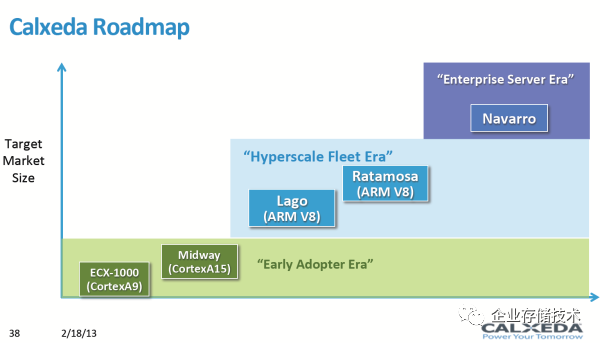
图2.4 Calxeda 路标
Insight 64 的分析师说,他们在32bit Arm服务器上花了太多钱。是的,2011年Arm宣布了64bit的Armv8,Applied Micro公布了X-gene的计划,其实第二轮Armv8 的服务器的浪潮就已经展开。
而Calxeda的倒闭,标志着第一轮的结束。
3 第二波 Armv8.0 (2011-2018)
虽然顶着编年史这种文艺的名字,我是想把它写成一个技术分析文章,重点在Arm服务器芯片的特点与演进,不是解释为什么这个公司成功,那个公司不成功。其实一个产品分析好做,一个公司的成败,偶然因素真的影响很大。
第二波的三个关键词是自研核心(custom core),主流性能,标准设计。在Arm服务器的初始岁月里,芯片设计公司来自各个不同的领域,带着自己对服务器CPU芯片的理解,各自交出了自己的产品。我把重点放在APM的X-gene,Cavium的ThunderX与高通的Centriq 2400上。同时也努力把所有的其它芯片都给一个线索,供有兴趣的人,自己深入。
我做了一个excel表格,努力的比对所有的服务器SoC,包括公司规模,投资与花费的人力资源。有缘线下做交流。
再说一段,因为在这一段历史中自研核占了多数,而且关于架构,ISA的争论一直不断,我不想展开说,因为会偏题。在一个做私有云的大牛那里学到一个词,“累计优势”,做CPU,做ISA,做芯片,其实也在一个缓慢的累计优势。这些年,我有带着客户的需求,案例,测试数据,信心满满地前往公司总部找架构师或者产品经理,要求改设计,增加指令的时候(是的,我还管这事),结果么?我不能说我一次也没有成功,但是我家架构师和产品经理,都是狠角色,在对拼数据和应用案例方面,鲜有败绩。
另外,Hock Tang 一定要提一下,这人简直就是Arm服务器的发展道路和我职业生涯中的荆棘,一个拿了double kill 双杀的男人。他先收购Broadcom,卖掉服务器芯片项目,然后提出收购 Qualcomm,高通的管理层为了自保,提出每年消减1B的开销,因此自我了断所有长期投资项目,运作良好的服务器项目就这样躺枪了。
3.1 AppliedMicro – X-gene (2011)
2011年10月,在Arm第一次宣布ARMv8架构的同时,Applied Micro公布了它们的自架构x-gene计划(大新闻都是和关键客户一起发布的)。
如果你在那个时代读新闻,你会留意到SoC这个概念,当然现在,SoC这个概念不用解释了。那个时候,还是需要强调 SoC等于chip + chipset的集成设计。
X-gene的第一代是8个自研核心-Storm,两个核共享256KB的L2 cache,这跟Arm的4个核一个cluster不同。下一章讲的AMD的代号Seattle的Opteron A1100 processor,也没有用4个Cortex-A57的一个cluster,两个cluster的设计,而是2个A57,4个cluster的设计。AMD的A1100的两个A57,共享1MB的L2 cache,比X-gene大4倍。但是X-gene的自研核Storm是4 issue的, A57仍然在3 issue的能效比的甜蜜点上。
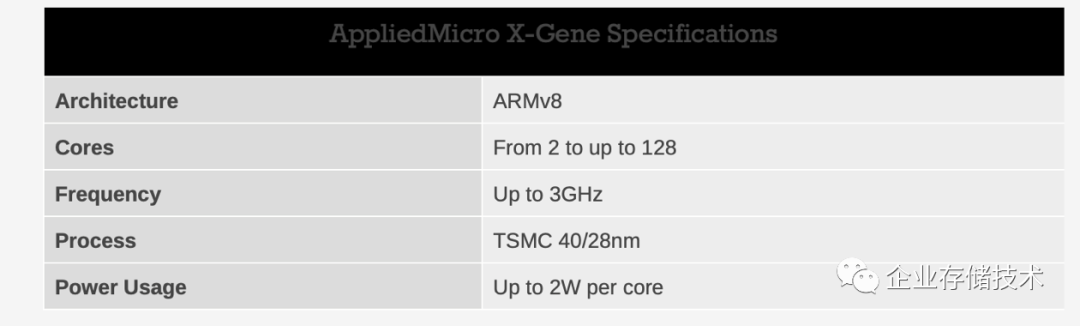
图3.1 APM的X-Gene spec

图3.2 APM的X-Gene产品路标
现在,连手机CPU都奔着6 issue去了,从这点上看,自研核,还是展现自己对业界发展洞见的好武器。
X-gene为8个核,配了4个memory通道,这个也是在x86阵营中少见的CPU:memory比例。而且集成了2个10G NIC,支持RoCE,算是SoC的优势。
Applied Micro官方资料给出的能耗参数,满负荷状态,一个核2瓦,idle状态,仅仅0.5w。

图3.2 X-Gene的框架图
我对X-Gene设计印象最深的部分是MSLIM ,这是4个A5组成的小处理器cluster,提供加速功能。我不知道到底有没有客户使用这个处理器组,也不知道当年的设计理念。
从设计到成品,有多少设计被客户忽略,有多少设计到了客户手里超常发挥,我觉得架构师也会感觉迷茫,工程的世界里竟然也有许多的不确定性。

图3.3 X-Gene die
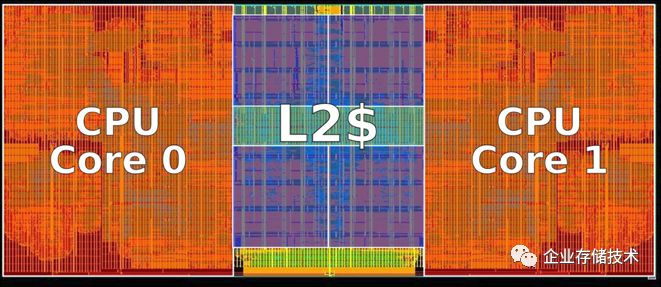
图3.4 X-Gene CPU模块
没有整个die的信息,不过有处理器模块的信息。每个处理器模块,有2个core,共享的L2,在40nm的工艺下,14.8 mm²,84M transistors。照着这个尺寸,我估计整个die是300 mm2。
Anandtech曾经有篇蛮详细,也蛮负面的评测报告。中心意思就是尚未成熟,性能,能效比优势也不明显。它测试的是HPE的moonshot系统,HPE的官方文件其实对X-gene评价颇高,因为X-gene是第一款量产的Arm 64bit 服务器芯片,初期的软件伙伴们,都是用着它家的系统的。
我知道Applied Micro-APM的时候,它还叫AMCC。AMCC团队算是硅谷老牌做CPU的不多团队之一,不过是做PowerPC的。它在多核路上不太顺利,所以换了Arm重新开始。大约因为是老牌CPU设计团队,他们一上手就选了最高难度的架构授权,自研核的路线。我曾经为了它和同事争论到面红耳赤,跟他说,我站起来是条汉子,倒下去还是条汉子。我同事,性别男,气笑了,说,行,行,你是条汉子。
X-gene2大体上是X-gene1的28nm的tick实现,略。
3.1.1 eMAG-X-Gene3 2018
我犹豫许久,不知道该把这颗Ampere重新设计的eMAG,归为第二波尾巴,还是第三波的开头。按照核心的原设计脱胎于X-Gene 3来说,还是第二波尾巴。

图3.5 Ampere eMAG

图3.6 Ampere 产品优势

图3.6 Ampere eMag 框架图
3.2 AMD's A1100 (2012)
在Armv8架构推出一年之后,Arm发布了A57和A53两款 cortex-A5x系列的产品,按照国际惯例,一个重磅的合作伙伴在发布会与Arm一起闪亮登场,AMD。
这款内部代码名为Seattle,属于Opteron系列,后面的正式产品名字是A1100的芯片,现在在AMD主线产品历史上找不到的产品。
AMD当时花了蛮长的时间,解释为什么要做Arm服务器,怎么定位公司内部的x86与Arm的产品线,甚至为了稳定外界的怀疑,推出了仅仅活在新闻中的K12 (2015)。
如果我们回头看2012年,有一个名词,不能忽略,“microserver”,而那个时候,AMD刚买了SeaMicro,一个围绕着 Freedom Fabric打造高密度,低功耗的系统的公司。这个Fabric,超高密度(very-high-density),低功耗,听起来耳熟不?Calexda的路数啊。下图是10U的尺寸,共有768个CPU,包括了四个GE交换机和一个流量均衡器(a loadbalancer)。

图3.7 Calexda 10U系统
在这样的系统设计下,配一颗超低功耗的Arm处理器,合情合理多了吧?因此选Arm的标准核Cortex-A57,缩短开发时间,节省开发费用,也是顺理成章的事情,都在合理逻辑之内。
Cortex-A57的资料满世界都是,我就不在这里罗列了。前一章有提,AMD选了2 core 4 cluster的配置,而不是手机AP常见的4 core 2 cluster。好处么,自己体会一下。

图3.8 AMD Opteron A1100框架图
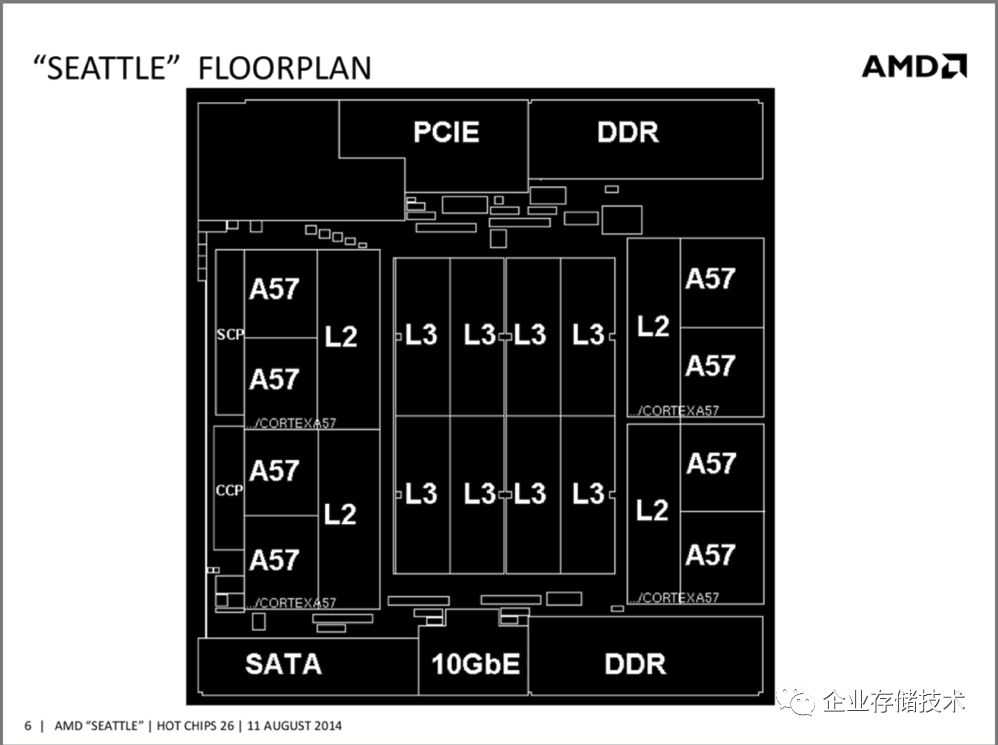
图3.9 AMD Opteron A1100 Floorplan
某种意义上,AMD这颗Seattle虽然被列入第二波浪潮中。它的设计理论完全是第一波的。K12才是第二波的。
可是看看K12的设计目标,在AMD的框架下,为什么要做Arm,自然是x86啊。Jim Keller这个男人本来是跟K12联系在一起的。但是…… ,这个风一样不羁的男子啊。
Intel的对于此轮浪潮的反应是14nm “Xeon-D”。
3.3 Cavium ThunderX 2014
某种程度上, Cavium的48核ThunderX 才是真正开启第二波Arm服务器浪潮的产品。它凑齐了一颗主流服务器芯片应有的所有特点,例如双路和性能。
Cavium做为一家仅仅有AMD1/10大的公司,很早就有超多核处理器的设计能力,只是之前是MIPS网络应用处理。
虽然只有2 issue的自研核,单核性能较弱。但是整个SoC的设计,特别多路设计,是出色的。而且因为网络处理器方面的积累,这颗芯片的加速引擎与IO接口非常丰富。
而且为了降低功耗,可以有选择的关闭加速引擎,变成4种不同的配置:云计算版本,存储版本, 运营商版本,安全版本。
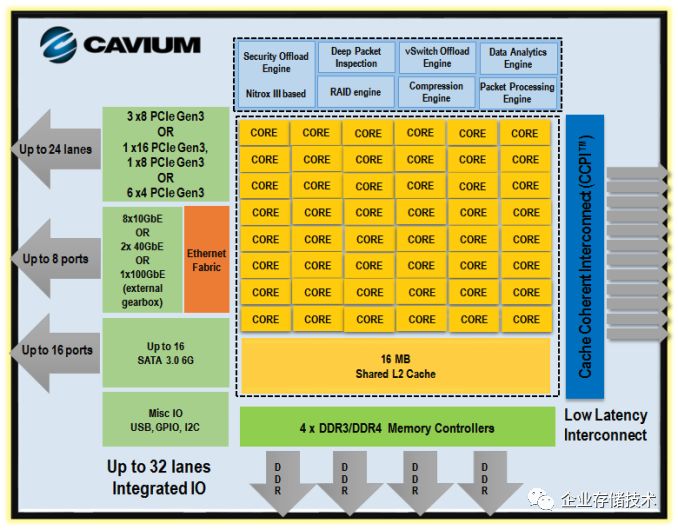
图3.10 Cavium ThunderX 框架图
Anandtech有个非常不错的性能测试,有助于对 Cavium ThunderX的理解。
3.4 BroadcomVulcan ThunderX2
这是很纠结的一节。如果说Broadcom Vulcan,那是2016的左右的事情。如果说Cavium 的Thunder X2 那是2018年的产品。然后就迅速变成了Marvell的ThunderX2。本来是同期规划的产品,结果,各种曲折离奇的竟然二合一。有的时候,我都不相信,我们这个产业,也有这么多戏剧化的故事。
说起来,源自RMI的Broadcom的CPU设计团队,和Cavium的CPU设计团队,有好多共同点,都是MIPS系的,都是做网络出身。但是跟Cavium老是做2 issue小核不同,Broadcom团队从一开始就擅长做多线程。因此在规划的时候Vulcan就是逆天的4线程。此时ARM阵营里,还没有多线程的处理器呢。
Broadcom原先的设计目标是16nm,die size 600 mm2,32核,每核4线程,支持双P系统。被Cavium收购之后,die size未披露。
而它的目标市场,或者说可见的design win集中在HPC市场。

图3.11 ThunderX2的框架图

图3.12 ThunderX 2 布局

图3.13 ThunderX2 IO接口
3.5 Qualcomm 2017
Centriq 2400有18Btransistors,398mm2,三星的10nm工艺,比thunderX2小巧多了。虽然它是单P处理器,但是对多年多代服务器发展规律,这本来不成问题。

图3.14 Centriq 2400
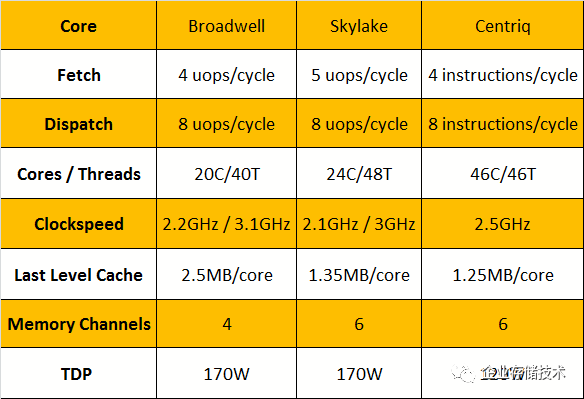
图3.15 Centriq 2400的微架构对比

图3.16 Centriq2400的框架图
这颗含着金钥匙出生的芯片,一路顺风顺水的到tape out,直到那位叫Hock Tang的黑天鹅的出现。
从价格功耗表上看,Centriq2400的定价与ThunderX2基本一致。
Centriq 2400的CPU核名字为“Falkor”的自研核。最高2.6Ghz,是高通的第五代自研核。如果有的话,下一代核是“Saphira” ,芯片的名字叫“Firetail”。但是没有然后了,高通取消了服务器芯片项目,也标志着第二轮Arm服务器的浪潮的尾声。
3.6 Samsung(2012-2014)
主线写完,支线也要写。
Samsung的Arm 服务器的故事,在国内知道的人少,但是上过华尔街日报的。Samsung也从来没有官宣过,整个项目起的时候,大家是猜测,灭的时候,大家也都是传闻。
其实,Samsung进入服务器SoC设计的逻辑可以和高通很接近,但是当时高通有CEO的支持,还有那样的黯然收场,而一家韩国公司的美国分支部门,想撑起一个大服务器芯片的设计,有多困难,可以想象。
3.7 Nvidia Project Denver 2011-2014
Nvidia是一个我非常尊敬的公司,也是硅谷现存的仍然是创始人做CEO的极少数公司了。但是这一章,我写了几次,都写不下去。大约是Nvidia仍然是GPU为主线的公司,它的CPU的发展逻辑,属于面向应用规划的那种放飞型。
这是一个从Tegra开始,到Carmel,集成Arm CPU在复杂功能芯片的路径。 其实,看起来更像是系统公司的芯片规划路径。因为本文集中在通用服务器芯片的分析,否则Nvidia家的产品路线,绝对值得一个完整的大章分析。

图3.17 Tegra Arm CPU

图3.18 Eegra K1

图3.19 Carmel CPU
3.8 Balkal
俄罗斯的第一颗28n芯片BE-M1000,其实不应该算在服务器类,不过它涵盖了工作站。这个芯片公司跟日本的Fujitsu,中国的飞腾,一样都是从超算项目中孵化出来,独立运作,更注重商业成功一点。
我当年是看过他们计划的超强路标的。但是从路标到产品落地,这中间的三五年的时间,太多变数,因此风消云散的多了。
说到做芯片这事,这是超算的同志们的传统强项。前面说到的某个服务器SoC,其实也来自于超算市场的推动。后面,我会说到欧洲,欧洲的同志们也开始发奋图强要自己动手做芯片了。
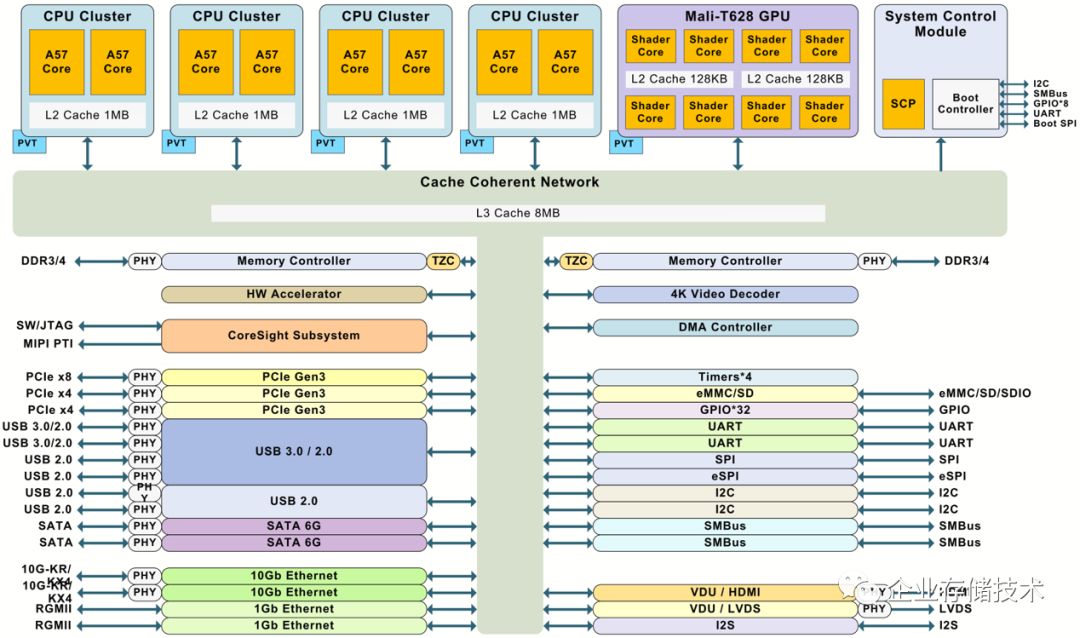
图3.20 Balkal BE-M1000
3.9 Phytium
飞腾的芯片的公开信息,来自hotchips 2015。最新的路标,来自飞腾总经理窦强2019年12月19日的公开分享。
恕不展开。
3.10 HiSilicon 1616
海思的1616是鲲鹏920的前一代,比较低调的一代。华为官网上没有介绍。我也就不放任何外网资料。
关于海思,我觉得可以按照《明朝那些事》的风格写部史诗级的著作,再补一个《海思群雄谱》的人物传记做后传。文科生写像海思这种公司,写不出气势,得我这种理工科的文艺青年。万事俱备,就差两件事就可以动手,一是海思宣传部预付的稿费,当然网友众筹也可以考虑, 二是要等我退休哈。
3.11 Socionext
Socionext这颗"SynQuacer™" SC2A11大约是唯一一颗Cortex-A53的24核芯片了吧?

图3.21Socionext SC2A11框图
这颗芯片,不能光看芯片,要看系统设计。
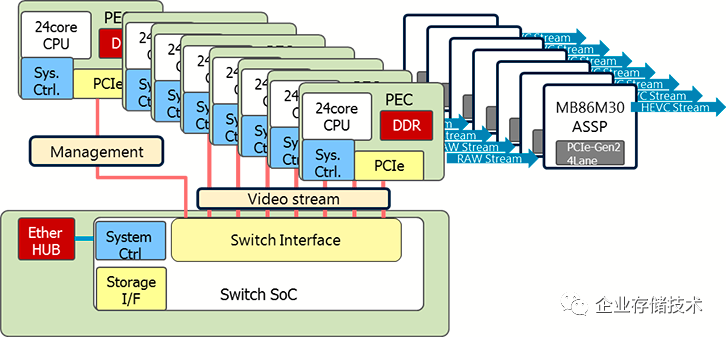
图3.22 Socionext SC2A11服务器系统
这种小核,高密度系统,有相似感觉了吧?那个时代的设计。
3.12 私评尾声
第二波浪潮还是半导体业界和系统厂商推动的,那么第三波,就是终端用户自己下海弄潮了。
4 第三波 Neoverse
Drew Henry(建议大家去读读他在Linkedin上的简介,堪称高管简历模版)这个男人也是要在Arm 服务器历史上留下名字的。在他加入Arm一年之后,2018年10月 Arm Tech上,他宣布Arm在Infrastructure 市场上有了自己的品牌(Neoverse)和冰公布了每年一代,每代提升30%的路线图。
这是第三波浪潮的开始,只是深水静流,那个时候,世界还是静悄悄的。
而我还记得为了凑齐发布会上的那些大厂logo的那些琐碎工作,还有伙伴们的给力支持。
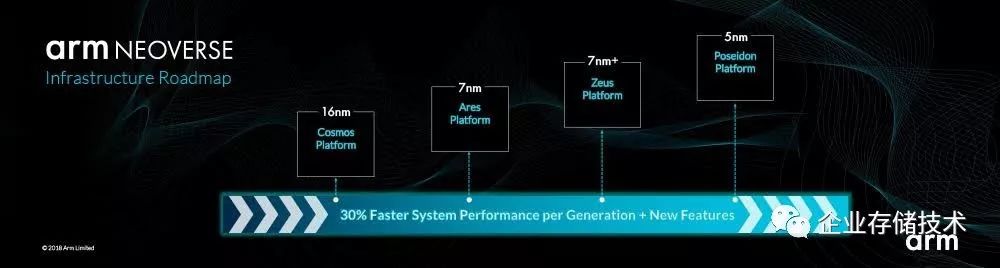
图4.1 Arm NEOVERSE路标
4.1 Huawei Kunpeng 920
2019年1月7日,有大徐总之称的徐文伟发布了鲲鹏920。
我只放我觉得重要的公开图,怎么解读,就看各位自己了。
这是颗世界先进级的产品,无论哪个方面,包括关注的热度。

图4.2 鲲鹏920的发布会图
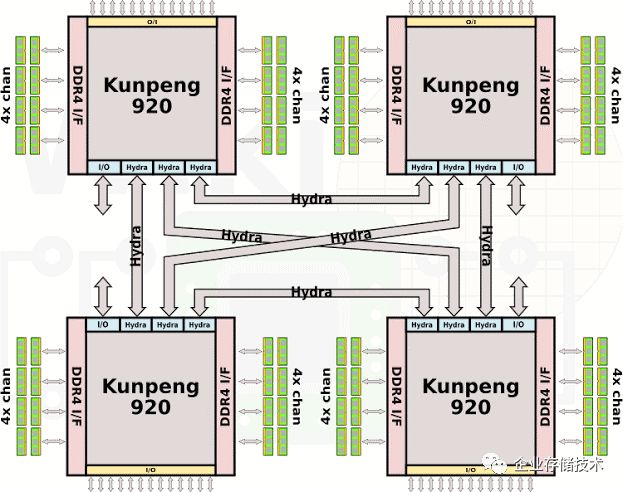
图4.4 鲲鹏920 4P互联图
4.2 AWS Graviton2
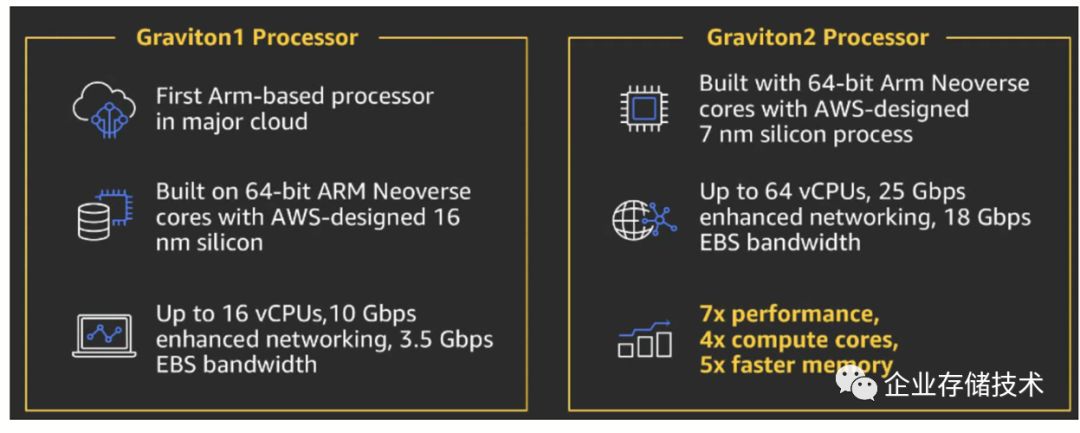
图4.5 Graviton1 & Graviton2
即使2018年11月AWS发布了Graviton,并且用Neoverse称呼了这个16个cortex A72 的自制芯片。世界并不震惊。现在看,16核A72 16nm@2.3GHz,确实更像是试水。
特别是看看2017年AWS发布的也是由2015年收购的以色列创业公司Annapurna labs团队开发的Nitro芯片。
但是2019年的AWS Graviton 2就是惊艳级别的产品了。64核 Neoverse N1,30 Billion transistors,7nm的工艺,推测die size应该在 300-350mm²,官宣高于Intel Xeon-based 5th代处理器40%的性能,还有高达25 Gbps的网络带宽和18 Gbps of 优化EBS的带宽。
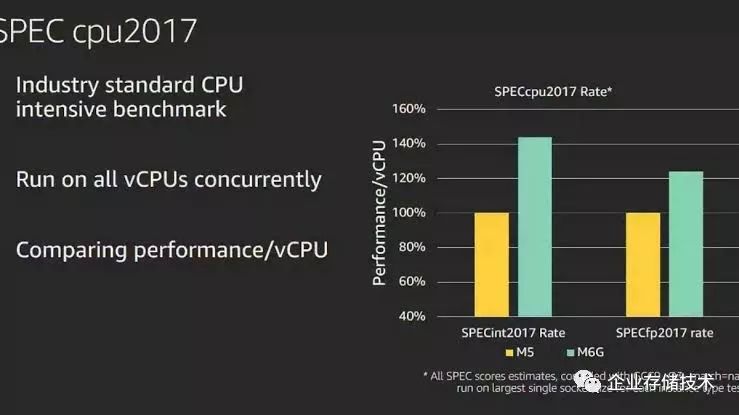
图4.6 SPEC cpu 2017

图4.7 AWS Graviton2支持的EC2
4.3 Ampere QuickSilver 2019
Ampere顺着AWS的graviton的正面风潮,透露了7nm 80核N1 代码名字为QuickSilver的下一代计划。最亮眼的是新芯片支持2 socket的配置,这要感谢Arm mesh IP (CMN-600)在CCIX方面的努力。

图4.8 Ampere产品路标
除了让人觉得帅到炸裂的80核N1设计之外,QuickSilver拥有128 PCIe4 lanes这样的豪华配置。还是Nividia家CUDA-on-ARM的核心伙伴。
这是我2020最期望的一颗芯片,毕竟能买到啊,AWS的graviton只能买云服务。
4.4 MarvellThunderX3
接着AWS的热度,公布自己下一代计划的不仅仅有Ampere,还有我们的老牌公司Marvell,因此我们知道了ThunderX3 processor的自研核的名字是“Triton”,还看到了每两年一代,每代性能翻倍的强劲产品路标。
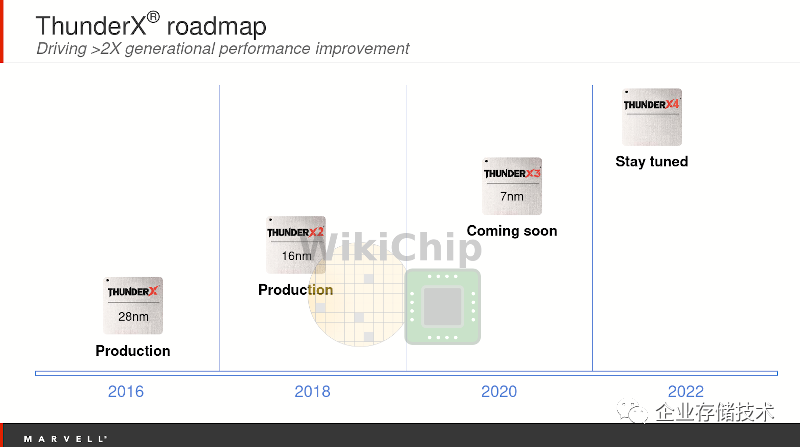
图4.9 ThunderX 路标

图4.10 ThunderX3的增强部分
4.5 Fujistu A64FX 2016
最喜欢的要放到最后。我的同事,在跟与一位伙伴讨论memory选择的时候,说“高吞吐,大容量和便宜三者之间,你只能选两个”,这句话非常有哲理了,如果有三项都可以兼顾的方案,大家就不纠结了。有纠结,肯定是有难选的地方,我个人偏好那种“除了贵,没别的毛病”的方案,但是请放心,给伙伴推荐的时候,我绝对不会表露这种个人倾向性的。
富士通的这款A64FX其实不是服务器芯片,是用来做超算的,恰恰就是那种“除了贵,没别的毛病”的产品。
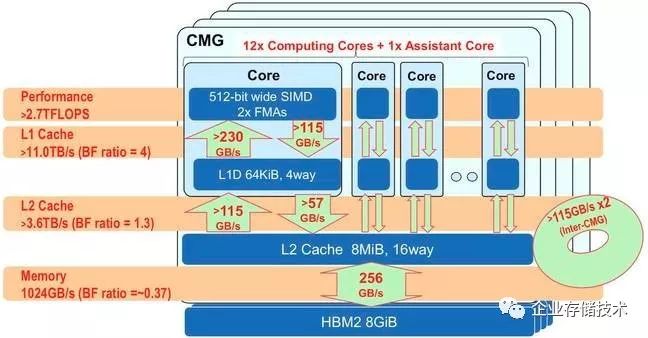
图4.11 A64FX的缓存层级和速度
2018年富士通在hotchips上公开介绍了A64FX这颗芯片。先看硬参数:8.8 billion transistors (这个不算多,AWS Graviton2 有30B) ,7nm。48个自研核加上4个同质的管理核,其实是4个处理器cluster,每个cluster是13个核。核间互联是自研的第二代TOFU -6D mesh/torus片上网络(第一代TOFU的口碑超级好),配的32GB HBM2 (超豪华配置),16PCIe 3.0 lanes (这个不算多,估计也不想接什么外设),1024 GB/s的存储带宽,2.7 TFLOPS @ 64bit,21.6 TFLOPS@8bit 的性能。Nvidia Tesla P4和P40,在8bit整数的时候,分别是22 TFlops和47TFLOPS,颇有一拼。
A64FX的cache层级,吞吐很高,执行流水线,电源管理,RAS都很有特色,有兴趣可以读一下hotchips的文档。

图4.12 A64FX的floorplan

图4.13 Fugaku节点(液冷的)
A64FX这种强悍的性能,可以不用和GPU组合,因此Cray在和富士通合作,把A64FX做进 CS500 clusters和未来Shasta系统中。
4.6 其它的新入者
2019年11月,一家叫Nuvia的创业公司,在SC会议期间,浮出水面。这家公司创始人的背景,苹果的诉讼,立刻登上了头条。没有产品之前,让我们记住他们的口号"deliver industry-leading performance and energyefficiency for the data center" 。
欧洲的欧洲处理器联盟-EPI也是一个以设计服务器级的CPU为目标的努力。不多说,看路标。

图4.11 EPI路标图
5 总结
我在试图回答Arm为什么要做服务器的时候,我能想到的就是“先进生产力”这5个字。什么叫先进生产力, Frank Frankovsky,Facebook VP of Hardware Design and Supply Chain Operations 也是个要有名字的男人。他提出 the most useful work per watt per dollar。真正能用上的算力除以买服务器花费与运营服务器所花的电费就是这个服务器的代表的生产力,这个值标志了先进性。
延伸一下,对产业链上的人就是the total useful work per total investment,提供有用计算力除以总投入的资金(时间,工程师的智慧与心血),这就是这个技术/方案/ISA/产品的生产力是否先进的指标。这也是我写这篇编年史的一条暗线,多少投入,第三波浪潮会带来多少产出。
真正的先进生产力,是属于全世界的,也是全世界共同努力的结果。
先进的产品是一行行的代码,一个个wafer累积出来的。
转自网络
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

