
语义网详解
引言

万维网本身是一个有趣的矛盾体--它的构成主体是计算机,但服务对象是人。我们每天所访问的站点都以便于我们理解的方式来提供信息,它们使用自然语言及图片,并采用了相应的页面布局。尽管计算机处于构建和维护万维网的核心地位,但这些计算机本身并不能真正理解所有这些信息的含义。它们无法像人一样去阅读、确定相互关系并作出决定。
语义网的目的是帮助计算机能够“阅读”进而使用万维网。这个看似雄心勃勃的想法实现起来颇为简单--将元数据添加到网页中,从而使万维网中现有的计算机能够阅读这些网页。这并不是要赋予计算机人工智能或使其具有自我意识,它不过是让计算机能够查找、交换或者(在有限程度上)解释信息。语义网是万维网的延伸,而不是要取代万维网。
上述内容听起来可能比较抽象,事实上也确实有些抽象。尽管某些站点已经开始使用语义网概念,但很多必要的工具仍处于研发阶段。本文中,我们将以《星球大战》三部曲为例带你了解语义网背后的概念和“利器”。
鸣谢
感谢乔西·赛内卡尔(Josh Senecal)为本文提供的帮助。
为什么需要语义网?
假设您想要在网上购买《星球大战》三部曲精装全集,而且您为此设定了一些基本条件。首先,您想要的是宽银幕(而非全银幕)DVD,而且希望有附赠礼品光盘。其次,您希望能以最低价买到,而且是一套新的,不是二手的。最后,您不希望支付过多的送货费用,也不希望等得太久才拿到手。
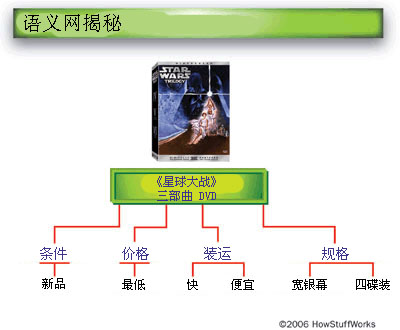 |
在万维网不断发展的今天,最普遍的做法是浏览不同零售商的网站,比较各自的价格以及送货时间和费用。您也可以在某个网站同时对比几家零售商的价格和送货服务。不论您采取哪种方法,几乎所有这类收集信息的繁琐工作都要您亲自完成,然后才能做出决定并提交订单。
有了语义网,您就多了一个选择。您可以将您的偏好提交给一个计算机程序实现的代理,它会为您搜索万维网,找到最佳匹配结果并提交订单。而且,这个代理还会打开您计算机上的个人理财软件并记录本次消费金额,并在日历上标注DVD预计送达的日期。代理还会学习您的习惯和偏好。这样,如果您在某个站点有过不愉快的购物经历,它会知道这个站点不应该再“拜访”了。
代理并不会像人一样去观看图片或阅读说明,它是通过搜索元数据实现上述过程的。这些元数据清晰地描述并定义了代理所需要的信息。元数据不过是可由计算机阅读、用来描述其他数据的数据而已。在语义网中,元数据对于阅读网页的人是不可见的,但对计算机是清晰可见的。元数据也可以变得更为复杂,从而使得万维网搜索能得到更精确的结果。用万维网之父蒂姆·伯纳斯-李(Tim Berners-Lee)的话说,这些工具会将当前看似一本巨型书籍的万维网转变为一个巨型数据库。
接下来,我们来看看那些使得文档能够让计算机阅读的“利器”。
语义网标记:XML和RDF
假设我们希望计算机能够读懂下面这句话:
阿纳金·天行者(Anakin Skywalker)是卢克·天行者(Luke Skywalker)的父亲。
这句话的含义对您来说再简单不过了:阿纳金·天行者和卢克·天行者都是指人,而且他们之间存在某种关系。我们知道,父亲是双亲之一,而且这句话也意味着卢克·天行者是阿纳金·天行者的儿子。但是,如果不借助某种手段,既便是如此简单的含义也会另计算机一头雾水。为了让计算机能理解这句话的含义,我们需要添加一些计算机可阅读的信息,这些信息描述了阿纳金天行者和卢克·天行者是谁,以及他们之间的关系。为此,首先要用到两个工具--可扩展标记语言(eXtensible Markup Language,XML)和资源描述框架(Resource Description Framework,RDF)。
与超文本标记语言(HTML)类似,XML也是一种标记语言。通过网上冲浪,您可能对前者已有所了解。HTML 描述了信息在万维网上的显示效果。而XML则添加对数据加以描述的标记,它是对HTML的补充,而非取而代之。这些标记对于阅读文档的人是不可见的,但对计算机是可见的。XML标记在万维网中已得到应用,而且现有的机器人(bot)(如为搜索引擎采集数据的机器人)就会阅读这些标记。
顾名思义,RDF的作用是提供一个描述资源的框架,这是通过XML标记实现的。从RDF的角度看,世界上几乎每样事物都可视为资源。通过这个框架,资源(任何名词,如上例中的“阿纳金·天行者”或《星球大战》三部曲)将与万维网上的特定项或位置相匹配,这样计算机就能确切知道该资源是什么。如此明确标识的资源可以使计算机避免将阿纳金·天行者与演员塞巴斯蒂安·肖(Sebastian Shaw)或海登·克里斯滕森(Hayden Christiansen)相混淆,也不会将原版三部曲与独角戏改编版的《星球大战》三部曲混为一谈。
为此,RDF使用三元组以XML标记的形式将该信息表达为一个图。三元组由主体、属性及客体构成,类似于一个句子的主语、动词和直接宾语。(有些资料称之为主体、谓词和客体。)RDF在万维网中已得到应用,例如RSS Feed的创建就用到了RDF。
 每个RDF三元组都有一个主体(阿纳金·天行者)和一个客体 (卢克·天行者),以及联结二者的属性。 |
在本例中,计算机现在知道了上述那句话中有两个对象,而且二者之间有一定的关系。但计算机仍不知道这两个对象是什么,也不知道二者之间具体是什么关系。接下来,我们将看到另一个工具,它将为我们添加新的一层:含义。
统一资源标识符URI
即使有了XML和RDF所提供的框架,计算机仍需通过一种非常直接具体的方式来理解这些资源是谁或是什么。为此,RDF使用统一资源标识符(Uniform Resource Identifiers,URI)为计算机指引资源所代表的文档或对象的具体位置。统一资源定位符(URL,以 http:// 开头)对您来说已经比较熟悉了,它是统一资源标识符最为常见的形式。统一资源标识符可以指向万维网中的任何事物,也可以指向万维网之外,如计算机化的住宅中的家电设备。统一资源标识符还有一些其他形式,如Mailto、ftp以及telnet地址等。
在本文的例子中,我们使用人物角色的页面作为其统一资源标识符,该页面位于《星球大战》官方网站。
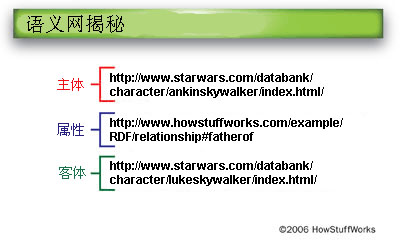 统一资源标识符为计算机给出了三元组中每个项的具体引用点--这样就无需进行解释,也不会造成理解错误。 |
现在,计算机知道了主体和客体是什么--第一个统一资源标识符代表的实体是阿纳金·天行者,第二个代表的实体是卢克·天行者。但是,你也会注意到三元组中间的那个统一资源标识符并未指向《星球大战》网站,而是指向HowStuffWorks服务器的一个关系说明文档。如果该页确实存在,它会成为我们的XML命名空间。
XML与HTML不同:后者使用标准的标记(用b>表示粗体,用u>表示下划线等),而XML并没有标准的标记。这是有好处的--它能让开发人员针对特定目的创建独特的标记。但这也意味着浏览器无法自动识别这样的标记的含义。XML命名空间本质上是一个定义文档,它告知应用程序另一个文档中的所有标记的含义。XML文档的创建者在文档的开头用一行代码声明命名空间。在本例中,我们的命名空间形如:
rdf:RDF xmlns:hsw=http://www.howstuffworks.com/example/RDF/relationship#>
这行代码告诉计算机:任何以“hsw”开头的标记所使用的词汇都在此文档中定义。您可以在此处查找任何以“hsw”开头的标记。通过这种方法,人们可以为文档创建其所需的XML标记,而不会与万维网上的其他XML文档冲突。
XML和RDF是语义网的“官方语言”,但它们本身并不足以使计算机能访问整个万维网。接下来,我们将看到一些其他的层。
语义网模式与本体工具:RDFS、OWL和SKOS
语义网的另一个障碍就是计算机并没有人所具备的词汇。您在生活中一直在使用语言,可以易如反掌地看出不同词语和概念之间的关系并根据上下文来推断含义。不幸的是,我们并不能简单地将字典、年鉴和一套百科全书提供给计算机,就指望计算机能自行学会所有的知识。为了能够理解单词的含义以及单词之间的关系,计算机必须依赖那些描述所有单词的文档以及建立必要连接的逻辑。
在语义网中,这需要通过模式(schema)和本体(ontology)来实现。这是两个相互关联的工具,用于帮助计算机理解人类的词汇。本体就是指描述对象以及对象间关系的词汇。模式则是组织信息的方式。通过RDF标记,可以在文档内包含对模式和本体的访问,条件是文档的创建者必须在文档的起始处声明所引用的本体。
语义网中使用的模式和本体工具包括:
- RDF词汇描述语言模式 (RDF Vocabulary Description Language schema,RDFS)--RDFS为资源添加了类、子类以及属性,从而创建了一个基本的语言框架。例如,资源“达戈巴”是行星的一个子类。达戈巴的一个属性会是“多沼泽”。
- 简单知识组织系统(Simple Knowledge Organization System,SKOS)--简单知识组织系统按照宽泛或具体对资源进行分类,它允许指定首选和备选标签,并允许用户可以快速将同义词和词汇传送到万维网。例如,在《星球大战》的词汇中,西斯勋爵(Sith Lord)的具体名称为达斯·西迪亚斯(Darth Sidious),而宽泛的名称为武士。类似,汉·索罗的备用标签是那夫·赫德和激光脑。
- 万维网本体语言(Web Ontology Language,OWL)--OWL是最复杂的一层,它对本体加以规范,描述类之间的关系并使用逻辑进行推理。它也可以根据现有的信息构建新的类。OWL共有三种基本的复杂级别--轻量、描述语言(DL)和完全。
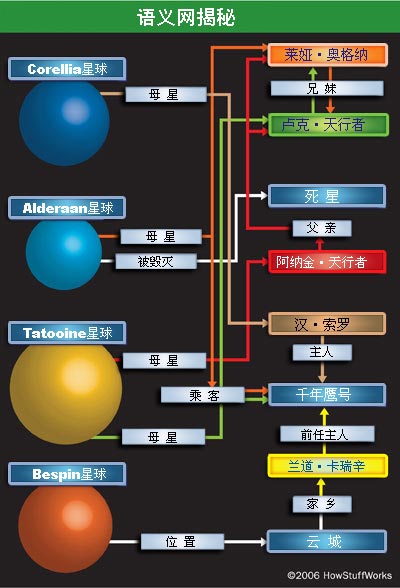 《星球大战》本体中的个别几个资源和连接示例。您自己也可以通过观看这部电影或从上网浏览来画出这些资源和连接,但计算机必须对这些信息有很明晰的界定才能得出其含义。 |
本体带来的问题是它们非常难以创建、实施和维护。如果本体涉及的范围较广,则本体数量会很庞大,涉及很多概念和关系的定义。正是由于上述困难,相比本体而言,一些开发人员更倾向于逻辑和规则。人们对于这些规则应扮演的角色存在争议,这可能是语义网发展一个潜在的困难。
接下来,我们将回到最初的示例:购买《星球大战》三部曲 DVD,来全程体验一下。
访问元数据
语义网的长远目标之一是让代理、软件应用程序及Web应用程序能够访问并使用元数据。实现这一点的关键工具之一是简单协议(simple protocol)和仍处于开发阶段的RDF查询语言 (RDF Query Language, SPARQL)。SPARQL的目的是从RDF图中抽取信息。它可以查找数据,并对结果进行限制和排序。RDF结构的优势之一就是这些查询可以非常精确,从而获得非常准确的结果。
语义网工作流程
在本文开头部分的例子中说到,我们要在线购买《星球大战》三部曲 DVD。接下来,我们说说语义网如何使整个购买过程更加便捷:
- 每个站点不但有供用户阅读的文字和图片,还会有供计算机阅读的元数据,这些元数据描述了该站点出售的DVD。
- 使用RDF三元组和XML标记的元数据使计算机能够阅读DVD的所有属性(如条件和价格)。
- 如有必要,商家会使用本体为计算机提供用于描述所有这些对象及其属性的词汇。各购物站点都可以使用相同的一套本体,如此一来,所有这些元数据就成为了通用语言。
- 每个出售DVD的站点也可以采用相应的安全性和加密机制来保护客户的信息。
- 计算机应用程序或代理便会阅读各站点中的元数据。应用程序可以对信息进行比较,确定资源是准确和可信的。
当然,万维网规模庞大,为现有的网页添加这些元数据是一项艰巨的工程。接下来,我们将讨论这一点以及语义网所面临的其他潜在障碍。
W3C和语义网的未来

同万维网类似,语义网也是分散式的--并没有哪个机构或组织对其规则和内容具有控制权。然而,确有某些个人和组织对语义网的原则和协议的制定担负着领导角色。这里不得不提到的便是万维网联盟(World Wide Web Consortium,W3C) 和该组织的总监蒂姆·伯纳斯-李,此外还有W3C下属的成员组织。W3C并非一个学术机构,因此大学、其他组织和公众社会在这个领域也颇为活跃。
万维网的某些领域现已融入了一些语义网的元素。其中包括:基于RDF的RSS馈送(RSS Feed)以及旨在创建可由计算机阅读的个人网页的Friend-of-a-Friend(FOAF)项目。
但语义网的大部分功能和实践尚处在成长阶段,还有一些相当大的障碍有待克服。分散式使得开发人员能够自由地精确创建所需的标记和本体。但是,这也意味着不同的开发人员会采用不同的标记来描述同一事物,从而给计算机在进行比较时带来困难。批评人士还提出了“身份问题”这一质疑--URI代表一个网页还是该页描述的概念或对象?例如:“http://www.starwars.com”代表《星球大战》这部电影还是仅仅表示该网页?
一些开发人员对语义网应更多的依赖于规则还是更多的依赖于本体也存在争议。批评人士甚至认为这根本就是个无法实现的庞大工程。首先,人的思维方式与RDF所使用的图实际上大相径庭。其次,商家和现有的网站似乎不可能真正投入时间和资源添加所有必需的元数据。将来,某些商业软件创建新文档时可能会提供添加元数据的选项,但要在更大的规模上实施,这样的工具似乎仍不可行。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

