
本文将描述一种针对网络边缘设计的基于 NN 的关键短语检测解决方案。这些二值化模型可在低功耗 UltraPlus™ FPGA 上运行。本文将讨论当使用包含嘈杂背景(如音乐或聊天噪声)的数据集训练 NN 时,如何在嘈杂环境中使用关键短语检测。在这种情况下,神经网络使用公共数据集进行训练,以检测“七”这个词。关键短语检测可用于广泛的应用,无需个人助理设备。可能的应用包括智能电灯开关、智能电视和 AVR,通过音量增大和减小等命令来管理设备。
一、引言
长期以来,使用语音命令来控制人机界面 (HMI) 一直是系统设计人员的目标。可以追溯到 20 世纪中叶的流行科幻电视节目和电影,例如《星际迷航》和《星球大战》,向我们暗示了语音世界的样子。但事实证明,为现实生活中的消费类应用开发低成本、高能效的解决方案是难以捉摸的。
然而,在过去几年中,亚马逊的 Alexa 和苹果的 Siri 等流行的人工智能应用程序的出现,以及它们将语音命令转换为系统操作的能力,加速了向基于语音的 HMI 的迁移。这些快速进步为越来越多依赖关键短语检测的智能家居解决方案打开了大门。如今,用户可以要求 Alexa 在互联网上订购产品、开灯、锁门、设置家庭恒温器,甚至给草浇水。
通常,这些支持语音的 HMI 执行识别云中的关键短语所需的计算。在许多情况下,设计师将他们的应用程序插入到预先存在的基础设施中,比如亚马逊的 Alexa。然而,这种发展战略面临着一些限制。首先最重要的是成本。在云中的服务器上运行关键短语检测算法的解决方案必须在每次访问云中的资源时按分钟付费。此外,构建基于云的边缘解决方案的开发人员必须向 NRE 支付费用,以针对特定设备训练他们的解决方案,然后为他们交付的每个解决方案支付版税。将他们的设计插入现有基础设施的设计人员将看到他们的成本随着他们转向需要更强大的处理器来获取数据、分析数据的 Wi-Fi 模型而增加,
此外,依赖互联网连接会带来额外的风险。如果连接中断,使用互联网连接将数据传输到云可能会导致服务中断。通过互联网传输数据也存在潜在的黑客攻击风险。从用户的角度来看,互联网连接为侵犯隐私和安全问题打开了大门。依赖直接位于设备上的计算资源的边缘解决方案避免了这些潜在问题。
二、新的方法
本文探讨了一种不同的方法,可以为位于网络边缘的设备带来成本更低的关键短语检测。利用在开发高精度、紧凑和低成本的二值化神经网络 (NN) 模型方面取得的进展,以及对新一代极低功耗现场可编程门阵列 (FPGA) 的改进,设计人员现在可以构建关键短语检测解决方案,以执行所有计算都在边缘,从而消除了与云连接的 NN 关键词检测实施相关的连接性、安全性和隐私问题。
通过在本地执行关键短语检测,与基于云的解决方案相比,此设计策略可显着节省成本。它也不依赖其他生态系统来运行。如果基于云的解决方案中的 Internet 连接失败,则系统将失败。本地的、基于边缘的解决方案不会冒这种风险。安全和隐私问题不是威胁。本地解决方案更易于用户设置和运行。最后,使用莱迪思的超低功耗 iCE40 Ultra Plus FPGA,这种方法为设计人员提供了显着的节能效果,这是电池供电设备的一个重要考虑因素。例如,本演示文稿中描述的解决方案仅消耗 7 mW。
将负担得起的智能家居应用带到边缘的关键步骤是开发能够在低密度、低功耗 FPGA 上运行的二值化 NN 模型。在云端使用浮点计算的深度学习技术对于边缘的消费者应用程序是不切实际的。相反,设计人员必须开发计算效率高的解决方案,既要满足精度目标,又要符合消费市场的成本、尺寸和功率限制。因此,在边缘工作的设计人员必须使用尽可能少的数学运算。
设计人员可以简化计算的一种方法是从浮点切换到定点甚至基本整数。通过补偿浮点到定点整数的量化,使用二值化神经网络的设计人员可以开发出训练更快、精度更高的解决方案,并将定点、低精度整数神经网络的性能提高到接近浮点版本的水平。 为了构建简单的边缘设备,训练必须创建具有 1 位权重的 NN 模型。这些模型称为二值化神经网络 (BNN)。
通过使用 1 位值而不是更大的数字,BNN 可以消除乘法和除法的使用。这允许使用 XOR 和弹出计数来计算卷积,从而导致显着的成本和高达 16 倍的功耗节省。借助当今的 FPGA,设计人员拥有了一个高度灵活的平台,可以提供他们所需的所有存储器、逻辑和 DSP 资源。
三、神经网络实现
下面的讨论描述了一个关键短语检测解决方案的示例,该解决方案专为边缘应用而设计,并在具有 BNN 软核的 iCE40 UltraPlus FPGA 中实现。在正常操作期间,关键短语检测实现会在消耗不到 1mW 的情况下侦听声音。一旦系统检测到声音,它就会激活 1 秒的缓冲并调用 BNN。BNN 直接对原始输入进行操作,而不是传统的频谱图和 MFCC 预处理。代表 1 秒音频的 16K 原始样本通过重叠的 1D 卷积层,变成 30 个 32x32x3 图像,每个图像代表一个 10ms 音频样本。然后将输出传递到主 BNN 进行处理。

BNN 有四层深,每层执行如下所示的功能:
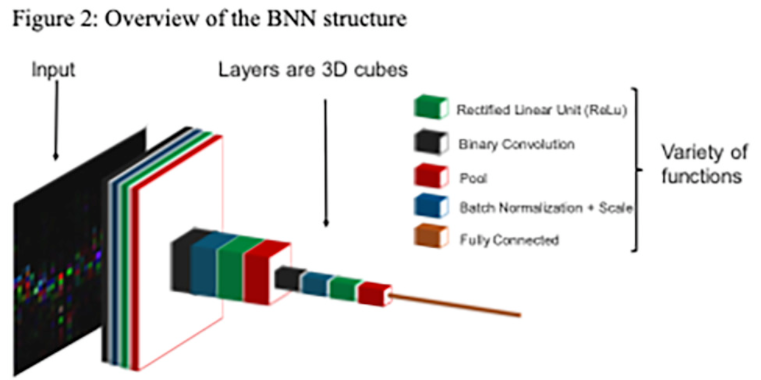
二进制卷积是输入数据和 1 位权重的 1 位乘法。在这种情况下,乘法被 XOR 函数代替。Batch Normalization 和 Scale 在 BNN 训练阶段对激活进行归一化并提供帮助。整流线性单元 (ReLu) 将低于特定阈值的数据设置为 0,高于相同阈值的数据设置为 1。对图像的每个相邻像素执行池化,并选择概率最高的有意义的像素。此功能减少了后续步骤所需的计算量。全连接层通常是最后一层,它占用前一层中的每个神经元。它对下一层的神经元也有一定的影响。这个函数通常计算量很大,因此它是作为最后一个操作执行的,其中神经元显着减少。
BNN 使用 GPU 进行训练,并运行 Café 和 TensorFlow 等标准训练工具。使用的训练数据集是一个公共训练集,包含 65,000 个 1K+ 人 30 个短词的 1 秒长的话语。这个阶段被称为训练阶段。然后,训练工具的输出通过莱迪思半导体的 NN 编译器工具进行格式化,以供 FPGA 设计使用。您可以将权重视为边缘硬件推理期间要使用的关键短语的模板。选择的关键词是“七”。
四。系统实施
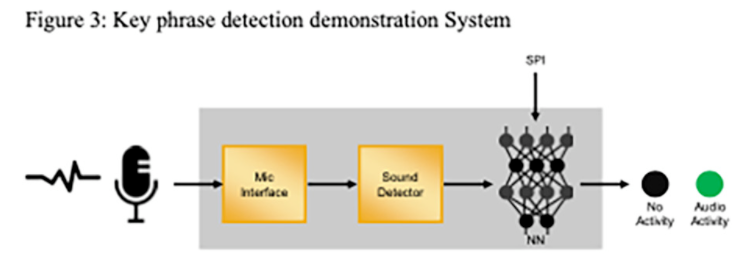
为了演示系统的功能,工程师使用了带有 iCE40 UltraPlus FPGA 的 HiMax HM01B0 UPduino 扩展板。这是一款低成本的 Arduino 外形板,旨在展示 FPGA 的功能。该板有两个直接连接到 FPGA 的 I2S 麦克风、用于 FPGA 设计的外部闪存和权重激活存储。它还具有用于指示检测到关键短语的 LED。用户可以直接对着麦克风讲话。一旦检测到关键短语,LED 就会亮起。
五、业绩
在此应用中,FPGA 设计频率和处理长度可以换取功耗。在 27MHz 时,16K 原始样本,相当于 1 秒的音频处理,可以在 25ms 内处理,同时消耗 7.7mW。当频率降至 13.5MHz 时,功耗降至 4.2mW,同样的 1 秒音频样本在 50ms 内处理完毕。
关键短语检测通常必须在嘈杂的环境中运行,而无需添加额外的硬件来消除噪声和回声。该实现通过使用包含嘈杂背景的数据集训练 NN 来实现这一目标,而无需定位和波束成形。训练有素的 NN 像人类一样检测关键词,但有类似的限制。带有各种随机人群噪音水平(咖啡厅、会议等)的数据集被添加到关键词中。用较高噪声水平训练的 NN 对噪声的鲁棒性更强,但需要更响亮的关键短语。
BNN 可以检测多达十个 1 秒的关键短语,非常适合通过语音进行 HMI。为了提高检测精度,仅在连续检测发生时才使用时域过滤器来报告关键短语检测。该设计为单个关键短语提供高达 99% 的准确性,为多达 5 个关键短语提供高达 90% 的准确性。
结论
将人工智能带到边缘会带来几个重大挑战。然而,它也提供了巨大的机会。正如该项目所展示的,使用 FPGA 实现 BNN 而不是基于云的资源将 AI 构建到设备中可以显着降低硬件成本,同时加快响应时间。同时,保持本地处理可以提高安全性并节省宝贵的带宽和服务器使用成本。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

