
OpenVINO最新版本是2020.4版本,自从2020.1版本以后,增加支持了C的API,这里还是以常用的C++的API来说明如何调优和加速。
这里简单以视觉模型来说明推理过程,和调优方法:
假设你已经完成模型转换,即将开源框架(如TF, Caffe)训练出来的模型转为IR格式。整个推理流程可以用下图来描述,下面根据这个流程来描述可以调优的方法和经验。
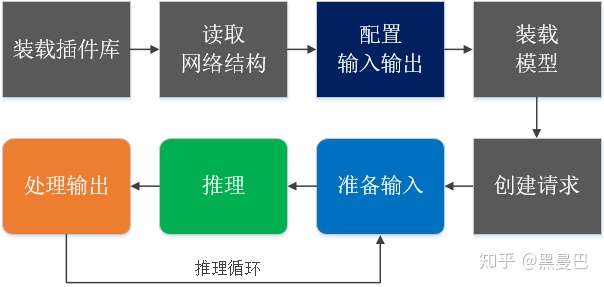 图1 推理流程
图1 推理流程1. 装载插件库
InferenceEngine::Core core; // 管理处理器和扩展插件
2. 读取模型结构
auto network = core.ReadNetwork("model.xml");3. 配置输入和输出
OpenVINO默认的通道顺序是BGR,在输入的时候,如果拿到的数据不是BGR格式,需要预处理通道顺序,这里通过setColorFormat接口进行调整。预处理不仅可以调整通道,还可以Resize算法类型,设置平均图(逐像素平均或逐通道平均)。
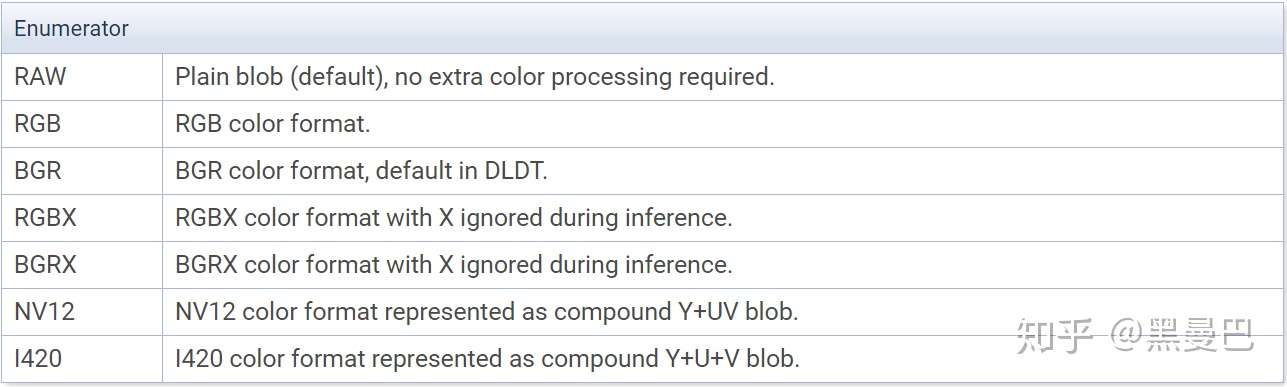 图2 图像通道类型
图2 图像通道类型注意:如果是NV12或I420格式,不支持批量推理。
// 输入InferenceEngine::InputsDataMap input_info(network.getInputsInfo());/** Iterate over all input info**/for (auto &item : input_info) {
auto input_data = item.second;
input_data->setPrecision(Precision::U8);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setResizeAlgorithm(RESIZE_BILINEAR);
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);}// 输出InferenceEngine::OutputsDataMap output_info(network.getOutputsInfo());for (auto &item : output_info) {
auto output_data = item.second;
output_data->setPrecision(Precision::FP32); // 设置输出精度 output_data->setLayout(Layout::NC);}4. 装载模型
装载模型有两种方式,一种是默认配置,只需指定设备型号,如CPU,另外一种方式,可以通过第3个参数增加优化配置选项,其中,config的配置以<key, value>形式给出。
auto executable_network = core.LoadNetwork(network, "CPU");// 或者std::map<std::string, std::string> config = {{ PluginConfigParams::KEY_PERF_COUNT, PluginConfigParams::YES }};auto executable_network = core.LoadNetwork(network, "CPU", config);画重点:优化选项都有哪些?如何配置这些选项?
上面的优化选项中,KEY_CPU_THROUGHPUT_STREAMS和KEY_CPU_THREADS_NUM比较常用,其他的选项根据需要进行配置。
假如你有一台CLX6240服务器,36核,KEY_CPU_THROUGHPUT_STREAMS的数目是推理流总数,网络较小就多开点推理流,大网络就烧开点,KEY_CPU_THREADS_NUM是绑定线程数,即每个推理流都会同时多线程并发计算,用多少核,就配置多少线程并发。
5. 创建推理请求
auto infer_request = executable_network.CreateInferRequest();
6. 准备输入
这里根据部署模型的情况情况来说明输入的数据准备
单一网络
这里输入图像或数据必须和Blob的大小对准(手动Resize),以及具有正确的色彩格式。
/** Iterate over all input blobs **/for (auto & item : inputInfo) {
auto input_name = item->first;
/** Get input blob **/
auto input = infer_request.GetBlob(input_name);
/** Fill input tensor with planes. First b channel, then g and r channels **/
...}级联网络
从一个网络的输出获得Blob,输入下一个网络的输入Blob。
auto output = infer_request1->GetBlob(output_name);infer_request2->SetBlob(input_name, output);
级联网络中处理ROI
当第一个网络的输出ROI是第二个网络的输入,无需重新为ROI结果分配内存,例如,当第一个网络检测视频帧上的对象时(存储为输入Blob),第二个网络接收检测到的边界框(帧内的ROI)作为输入。在这种情况下,允许第二个网络重用预先分配的输入blob(由第一个网络使用),并且只裁剪ROI,而不分配新的内存通过InferenceEngine::make_shared_blob()接口(参数为InferenceEngine::Blob::Ptr和InferenceEngine::ROI)。
/** inputBlob points to input of a previous network and cropROI contains coordinates of output bounding box **/InferenceEngine::Blob::Ptr inputBlob;InferenceEngine::ROI cropRoi;.../** roiBlob uses shared memory of inputBlob and describes cropROI according to its coordinates **/auto roiBlob = InferenceEngine::make_shared_blob(inputBlob, cropRoi);infer_request2->SetBlob(input_name, roiBlob);
分配适当类型和大小的Blob,然后将图像和数据输入到Blob中,通过InferenceEngine::InferRequest::SetBlob()接口设置到请求里。
/** Iterate over all input blobs **/for (auto & item : inputInfo) {
auto input_data = item->second;
/** Create input blob **/
InferenceEngine::TBlob<unsigned char>::Ptr input;
// assuming input precision was asked to be U8 in prev step input = InferenceEngine::make_shared_blob<unsigned char, InferenceEngine::SizeVector>(InferenceEngine::Precision:U8, input_data->getDims());
input->allocate();
infer_request->SetBlob(item.first, input);
/** Fill input tensor with planes. First b channel, then g and r channels **/
...}7. 推理
异步模式
异步模式会立即返回结果,不会阻塞主线程,使用wait()等待推理结果。
infer_request->StartAsync();infer_request.Wait(IInferRequest::WaitMode::RESULT_READY);
Wait()有三种模式可用:
1) 指定阻塞最大时间,该方法会被阻塞,直到指定的超时过期或结果可用(以先出现的时间为准)。
2)InferenceEngine::IInferRequest::WaitMode::RESULT_READY, 一直等待,直到有推理结果出来。
3) InferenceEngine::IInferRequest::WaitMode::STATUS_ONLY, 立即返回请求状态,它不会阻塞或中断当前线程。
同步模式
infer_request->Infer();
8. 检查输出并处理结果
不推荐通过std::dynamic_pointer_cast将Blob到TBlob转换,最好通过buffer()和as()来做。
for (auto &item : output_info) {
auto output_name = item.first;
auto output = infer_request.GetBlob(output_name);
{
auto const memLocker = output->cbuffer(); // use const memory locker // output_buffer is valid as long as the lifetime of memLocker const float *output_buffer = memLocker.as<const float *>();
/** output_buffer[] - accessing output blob data **/到此为止,就完成了整个推理的API调用和相关配置。也期待你能以正确的姿势来使用OpenVINO,性能得到一定得提升。
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

