
今天给大侠带来直接扩频通信,由于篇幅较长,话不多说,上货。
本篇适用于有一定通信基础的大侠,本篇使用的理论不仅仅是扩频通信。为了便于学习,本章将会以实战的方式,对整个工程的仿真。并对一些关键的仿真结果进行说明。各位大侠可依据自己的需要进行阅读,参考学习。
理论基础
一、扩频通信
香农(E.Shannon)在 1945 年、1948 年和 1949 年连续发表了有关信息论和通信加密以及系统安全性等 3 篇论文。最后给出信道容量的数学计算公式:
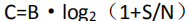
( C:信道容量;B:带宽大小;S:信号能量;N:噪声能量 )
根据香农最后给出的信道容量公式(C=B·log2(1+S/N))可知,信道容量与带宽大小正好成正比,不论信噪比(S/N)有多小(但不会为零),只要带宽足够大,信道容量就足够大。根据这个结论,引出了扩频通信技术。
扩频通信,即扩展频谱通信技术(Spread Spectrum Communication),通过扩频调制用一个更高频率的伪随机码将基带信号扩展到一个更宽的频带内,使****信号的能量被扩展到一个更宽的频带内,从而看来如同噪声一样,使该系统更具隐藏性和抗干扰性。接收端则采用相同的伪随机码进行解扩,从而恢复出原始信息数据。按照频谱扩展的方式的不同,现有的扩频通信系统可以分为直接序列扩频(Direct Sequence Spectrum)工作方式(简称直接扩频方式)、跳变频率(Frequency Hopping)方式(简称跳频方式)和混合方式四种[1]。本文所设计的使用直接序列扩频方式。
直接序列扩频通信是将带传输的二进制信息数据用高速的伪随机码(PN 码)直接调制,实现频谱扩展后传输,在接收端使用相逆方式进行解扩,从而可以恢复信源的信息。最能体现扩频通信的特点就是它具有优异的抗干扰能力。所以它常常被运用于一些干扰性很强的通信领域中。比如无线通信。
二、M序列
2.1 伪随机码概述
伪随机码也称为伪随机序列。是模仿随机序列的随机特性而产生的一种码字,也称为伪噪声序列或者伪噪声吗。直接扩频通信的性能取决于其伪随机序列的性能,伪随机码序列是一种规律难以发现、具有类似白噪声统计特性的编码信号。所以,伪随机序列通常有以下要求:
- a. ‘0’和’1’的个数基本相等,具有良好的随机性(由于数字通信通常以二进制位多,所以要‘0’的概率和’1’的概率基本相等);
- b. 具有尖锐的自相关特性,以保证通过同步伪随机序列完成扩频信号的解扩;
- c. 不同的 PN 序列具有很小的互相关特性,以防止通过不同的 PN 序列扩频后的信号被此干扰;
- d. 不同的 PN 序列具有很小的互相关特性,以防止通过不同的 PN 序列扩频后的信号被此干扰;
- e. PN 序列总量大,以满足多用户需求
2.2 伪随机码选型
根据上述要求,常用的序列有包括:m 序列、gold 序列和 Walsh 序列等,m 序列通常容易硬件直接硬件实现;gold 序列自相关性差;Walsh 序列一般使用写入双口 RAM 中,然后启动读取逻辑序列产生,但耗费大量的硬件逻辑单元。故本设计选用了 m 序列作为系统的伪随机码。
2.3 m 序列产生
m 序列是最长线性反馈移位寄存器序列的简称,它是最常用的一种伪随机序列。由 n 级串联寄存器组成,通过反馈逻辑的移位寄存器设定初始状态后,在时钟的触发下,每次移位后各级寄存器状态会发生变化。从任何一个寄存器输出得到的一串序列,该序列称为移位寄存器。其框图如图 1 所示为一个时钟触发下的时序电路。
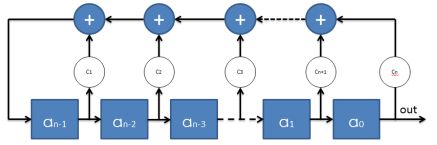
图1
图中使用 n 个寄存器,通常将 a0 作为输出信号产生 m 序列。从上图也可以看出,一个完成的 n 级 m 序列是由一个相应的线性反馈逻辑表达式,即为:

(其中, ‘⊕’代表异或运算或叫模 2 加运算,Cn ∈{0,1} )
由上式可知,只有当 Cn=1 时,对应的多项式才有效。为了便于表示,通常将上式与本原多项式对应。本原多项式的数学表达式如下:
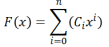
仅当该多项式为本原多项式时才能产生 m 序列,以下列出部分本原多项式表 1。
表1 2-10 阶本原多项式
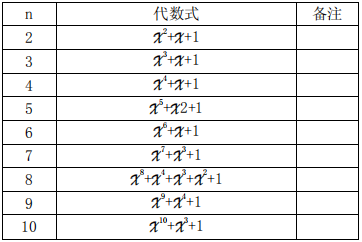
其中,n 阶 m 序列具有如下特点:
a. 序列长度为 2n-1;
b.‘0’和‘1’个数相当,即‘1’的个数比‘0’的个数多且仅多 1 个。
本原多项式是由多位科学家及其科学工作者最终得来,关于它们的具体得来,这里不作多解释。
本文设计采用的是 5 阶 m 序列作为系统的伪随机码发生器,其对应的硬件框图如图 2。由于级联的寄存器初始状态不能全为 0。
本设计中规定初始状态为:a4 a3 a2 a1 a0 = 5’b10000。
a0 输出的得到的 m 序列为:{0000101011101100011111001101001}。从左到右顺序输出。
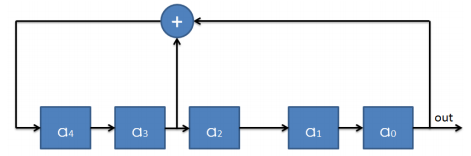
图2
根据以上 m 序列的拓扑结构图,我们就很容易使用 FPGA 的资源来设计5 阶的 m 序列,只要 5 个触发器和 1 个异或门就可以完成该设计。而 Verilog HDL 语言更容易完成设计。具体内容,参考 coder 模块。
三、汉明码
数字信号在传输过程中常常因干扰而发生损坏。接收端接收到数据后可能错误的判决。乘性干扰引起的码间串扰可以采用均衡的办法纠正。而加性干扰的影响则需要其他办法解决。对于加性干扰,本文考虑使用差错控制措施。
差错控制措施,即在数据中间添加必要的监督位,达到可以对错误数据的监督和纠错能力。对于差错控制措施,前辈科学家和科学工作者也设计出多种方法,各有各的优劣。本设计使用的是汉明码(7,4),其中 7 为码组的总长度,4 为原始信息位数,则监督位为 3 位。故每发送 4 比特信息需要添加 3 比特的监督位,监督位是根据信息位既定约束关系得到。汉明码是一种能纠错 1 比特错误的特殊的线性分组码。由于它的编译码简单,在数据通信和计算机存储系统中广泛应用,如蓝牙通信技术和硬盘阵列等。
本设计所使用的汉明码的最小码距为 3,可以纠正 1 为错误,检测 2 位错误。但对 2 位错误码并不能正确的纠错。尽管发生 1 位错的概率相对最高,但在一些比较高的应用中汉明码不能满足要求。码距是指两个不同码组间对应位不同的个数,例如 1000111 和 10001100 的码距为 3。
对于以上介绍比较乏味,以下使用另一种角度来对(7,4)码进行介绍汉明码的原理与设计过程。
我们可以把添加纠错码作为一个系统,即输入 4 比特原始信息位(a6,a5,a4,a3)而输出带有 3 比特监督位(a2,a1,a0)的码组。
对于 3 个监督位,有以下规则:
S1. 监督位 a2 作为 a6、a5 和 a4 的偶校验码,即 a2^a6^a5^a4=0;
S2. 监督位 a1 作为 a6、a5 和 a3 的偶校验码,即 a2^a6^a5^a3=0;
S3. 监督位 a0 作为 a6、a4 和 a3 的偶校验码,即 a2^a6^a4^a3=0;(‘^’表示异或或者表示模 2 加)对应以上 3 个监督位的规则,可以列出其对应的全部码组,如表 2。
表 2
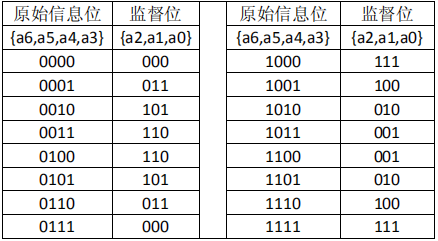
从上表中,不难看出,纠错码产生系统输出由 a6a5a4a3a2a1a0 构成,而每发送一个码组,只发送 4 比特的原始信息。从上表中,也不能直观的说明该编码方式可以纠错 1 位码元,而不能纠错 2位,而图 3 正好可以解释。
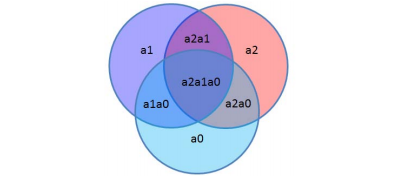
图3
图中 3 个大圆圈对应 3 个监督位的三个规则,可以这么理解,如下:
1. 如果接收到的信息只不符合规则“S1”,则对应图中 a2;
2. 如果接收到的信息只不符合规则“S2”,则对应图中 a1;
3. 如果接收到的信息只不符合规则“S3”,则对应图中 a0;
4. 如果接收到的信息不符合规则“S1”和“S2”,则对应图中 a2a1;
5. 如果接收到的信息不符合规则“S1”和“S3”,则对应图中 a2a0;
6. 如果接收到的信息不符合规则“S2”和“S3”,则对应图中 a1a0;
7. 如果接收到的信息不符合规则“S1”、“S2”和“S3”,则对应图中的a2a1a0。
从图 3 中,可以给出一个结论,只要错误码只有 1 位,系统就可以纠正错误;而如果错误码达到 2 位,就无法纠正错误。
根据以上两表对应关系可以推出以下错误规则和误码位置关系的结论,列出如表 3 所示。
表 3
![]()
(注明: 对应的 1 表示错误,例如 S1 S2 S3 等于 001,表示接收到的数据违反规则 S3)
从以上对汉明码的原理,到设计使用(7,4)码的设计,设计中的 3 个监督位都可以使用异或操作完成。具体内容将在后面介绍。
四、系统结构
对于该系统,我们最注重的是原始码元汉明码编码、扩频、信道编码、频解码和纠错码系统。当然,由于设计仿真需要模拟一些关于加性干扰,不得不在模拟发送过程中添加干扰源。加上测试平台的模块构成了整个系统的通信方式,便于读者理解。整个系统的拓扑结构图如图 4 所示。
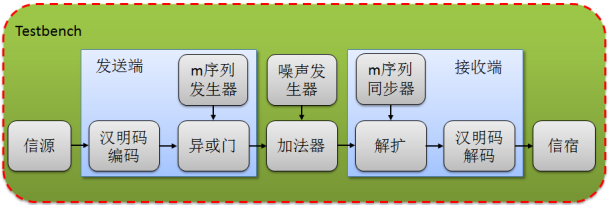
图中包括整个设计的构架,也是数字信号传输的基本模型。包括信源、汉明码编码、m 序列发生器、解扩器、m 序列同步器、汉明码****和信宿等。Testbench 平台会把信源和信宿进行比对,输出传输的结果,并且打印到屏幕上供查看。其中,发送端和接收端才可综合,其它模块均用于测试,不可综合。噪声发送器为模拟信道传输过程中的干扰。加法器表示加性干扰。各个模块的代码对应如表 4 所示。
表 4 模块与代码文件对应关系
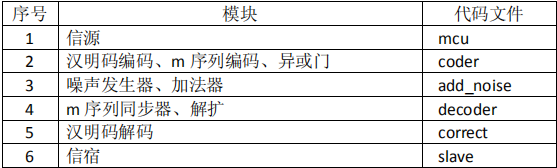
还有一些相关的文件,将在中篇详细说明。
作为一个底层模块设计人员,以数据流作为主线是必须的。关于本人这个结论,并没有真正的得到老一辈工程师的验证。但在本篇中,就以数据流的方式作为设计主线。
系统的Verilog实现
一、数据传输过程
从上一章中的拓扑结构图中可知数据流的过程,如图 5 所示。

图 5 mcu
输出给 coder 模块原始信息,每 4 比特作为一组,所以,在 mcu 中,每一个字节拆分成 2 个 4 比特发送到 coder 模块中。
在coder中对原始信号进行扩频、信道编码、最终输出2比特的数据01和11(即 -1 和+1)给 add_noise,经过 add_noise 加性干扰噪声后,输出 3 比特的数据给decoder 模块,decoder 模块经过解扩后输出给 correct 模块纠错,最终发送给 slaver模块。
最终 top 模块根据发送的原始数据和接收后的数据进行比对,输出结果(打印到屏幕上)。这里只是大概的介绍了设计中数据流的过程。在以下各个模块设计中还会具体提到。
二、MCU模块
模块 mcu 负责通信的信源部分,除了给 coder 发送数据,也为 coder 模块和add_noise 模块提供时钟、复位信号。该模块对整个仿真有着相当重要。因为它的设计关系到系统仿真的完整性。
mcu 模块包含随机数据的产生、存储、发送。随机数的产生采用系统函数 random产生。而数据存储有两个位置,一个是输出存储到文件中,另一个是存储到 memory中。存储到文件中是为了提供仿真后数据的查看,而存放 memory 中为了数据的发送和之后数据的比对。
该模块与下游模块 coder 有一定的时序逻辑,它控制 coder 模块的开始,由 mcu发送 send_ena 到 coder,随后等待 coder 模块反馈信号 insourse_ena。Insourse_ena信号有效,则发送数据,否则停止发送数据。数据发送结束只要撤销 send_ena 信号的有效性即可。
具体代码如下:

三、coder 模块
模块 coder 为原始数据的接收、对数据的汉明码编码、扩频和信道编码等操作。
模块的通信时序如下:
1. 接收到模块 mcu 原始数据到来之前,先发送一个同步头,起止由 mcu 控制;
2. 每发送 128 个字节原始数据前,发送数据 0000 作为数据帧同步,用于检测发送和接收两端数据发送是否同步;
3. 对原始数据进行汉明码编码,监督位为 3 位,全部放到数据位后;
4. 对编好的信息进行扩频,1 比特扩频到 31 比特;
5. 对扩频后的信号进行信道编码,即 1 用 01(+1)、0 用 11(-1)。
扩频通信,原始数据的频率必然比扩频后的频率小得多,本设计的 m 序列码是 31 比特位为一个周期。所以,原始信息的频率假设为 f 1,则扩频频率 f2 = 31x f1。因此,该模块有两个时钟。
该模块采用输入使能信号(send_ena)和输出反馈信号(insourse_ena)作为与上游模块(mcu)的握手信号。当 send_ena 有效,同时 insourse_ena 有效时,mcu 才会发送真实的数据到输入端口。而当 send_ena 信号有效的一段时间内,先发送同步头和数据帧同步后,才使 insourse_ena 有效,发送原始数据。
发送端固定对应的 m 序列为{0000101011101100011111001101001}。则每一个数据的发送都是按该序列发送,在接收端更容易同步(解调时更详细解释)。因此 m 序列的寄存器需一个标示位(flag),使数据和随机码同步送。关于该模块的工作过程,可以参照下篇的仿真。
该模块的参考具体代码如下:

四、add_noise 模块
该模块代码的作用是产生干扰,这里所说的干扰都为加性干扰,只要把无干扰数据 01(+1)和 11(-1)分别加上范围在[-2,+2]的随机数。
加干扰后,+1 将会变成 01±[-2,+2] = [-1,+3],-1 将会变成 11±[-2,+2] = [-3,+1]。并且两个范围都是均匀分布。
由于输入数据为 2 个比特,必须扩展后加减法才是我们需要的。具体代码如下:

模块 mcu、模块 coder、模块 add_noise,使用 mcu 作为顶层模块,激励由 mcu产生、发送输出为加加性噪声后的信号。
五、decoder 模块
decoder 是解扩模块,包括查找同步头、数据同步、解扩。
同步头{1111_1111_110},数据帧同步{0000_000},必须接收到同步头,且同步同步头后和接收数据帧同步,之后才对数据解扩。
由于发送模块和接收模块有时间差,但可以确认的是,必须先接收,后再发送。发送端采用的是固定的 m 序列码作为扩频伪随机码,这样做的利处就是接收端只要采用一样的 m 序列作为解扩码。
由于伪随机序列具有很强的相关性。只要有 1 个时钟错误,解扩结果相差会相当的大。依靠它的这个特性,可以把发送数据一一解扩。(具体解扩过程在仿真部分将更详细说明)。
由于在模块 add_noise 中添加了干扰,发送数据会有一定的误差,所以,解扩过程需使用累加的方法进行。而累加的阀值这里固定在 28,由于累加过程会有减法运算,所以计算初值均为 100。
具体代码如下:

该模块只是对应的解扩,并未涉及信息的检错和纠错,检错将在 correct 模块中进行。
六、correct 模块
模块 correct 将对解扩后的信息就行检错和纠错。检错过程就相当于汉明码编码的逆过程。但(7,4)汉明码仅在 1 位错误的情况下可以检出错误,如果多于 1 位错误,将无法纠错过来(依据 d>e+1;码距 d=3)。
具体代码如下:

七、Correct_Decoder 模块
模块 Correct_Decoder 是模块 decoder 和模块 correct 的顶层模块。
代码如下:

八、slaver 模块
模块 slaver 充当信宿。它接收来自于模块 correct 纠错后的数据,对数据进行保存。以便查看结果。
模块 slaver 作为接收端,它将给解扩和纠错模块提供时钟信号,但其的起始必须必发送的起始快。并且它所产生的时钟可以是随机的开始,以 mcu 模块产生的时钟没有相位上的关系。
其代码如下:

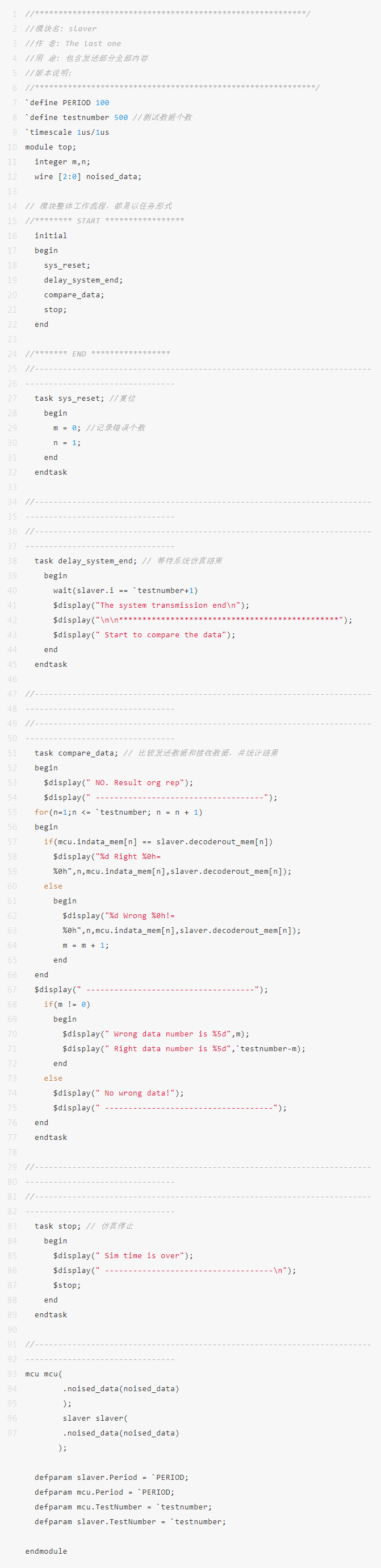
九、Top 模块
模块 top 作为仿真平台的顶层模块,它包含 mcu 和 slaver 两个模块。并且对发送数据和接收数据进行对比。统计结果,并输出(打印到屏幕)。
模块 top 将给两个模块提供周期,仿真个数等参数,以传参的形式传送。
它的代码如下:
仿真
一、模块的建立及其仿真环境的生成
1.1、在计算机上,找一个没有中文字符的目录,新建以下几个文件,如图 6:
上图为可以建立的文件,sim_wave.do 是仿真波形保存文件.tt.do。
其代码如下:
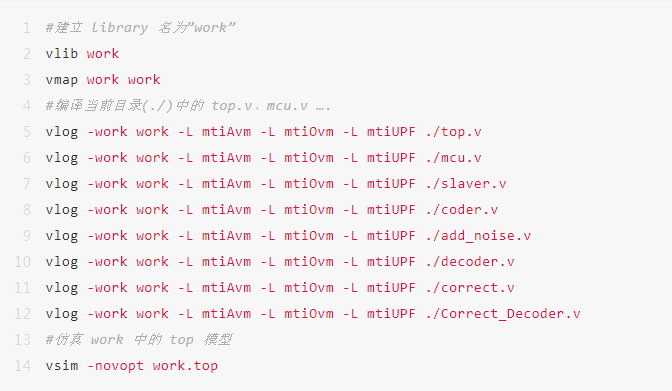
以上是输入方式进行仿真,也可以直接使用图形化的方式进行仿真。但没有开始仿真,因为我们以下还要添加一条语句。但没有响应的文件。
tt.bat 的代码如下:

tt.bat 文件为批处理文件,仅为打开 modelsim、运行 tt.do 文件使用。也可以不使用该文件(以下不会详细介绍)。
1.2、将对应的代码写到相应的文件中(sim_wave.do、tt.bat 文件可以不管)。
1.3、用 modelsim 的打开方式打开 top.v 文件(或者你先打开 modelsim,然后把目录修改成以上所述的目录也可)。运行的界面如图 7(modelsim6.5d):
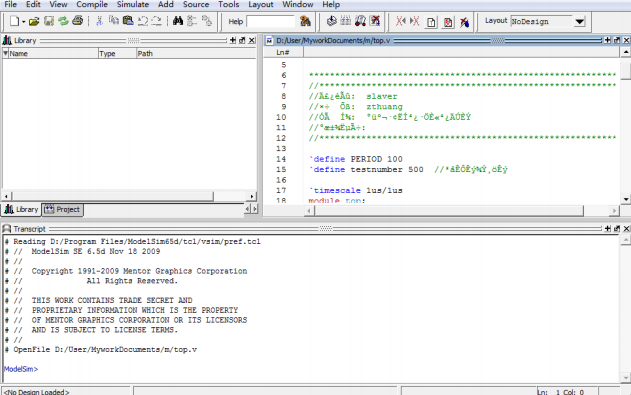
图7
图中的乱码均为modelsim不兼容我所使用的notepad软件编写的中文字符,大侠均可不以理睬。
1.4、在 Transcript 中输入”do tt.do”,运行当前目录下的 tt.do 文件。运行过程中,最后跳出如图 8 的窗口。如果有错误,会在 Transcript 中用红色字体说明(当然,这里都是英文)。
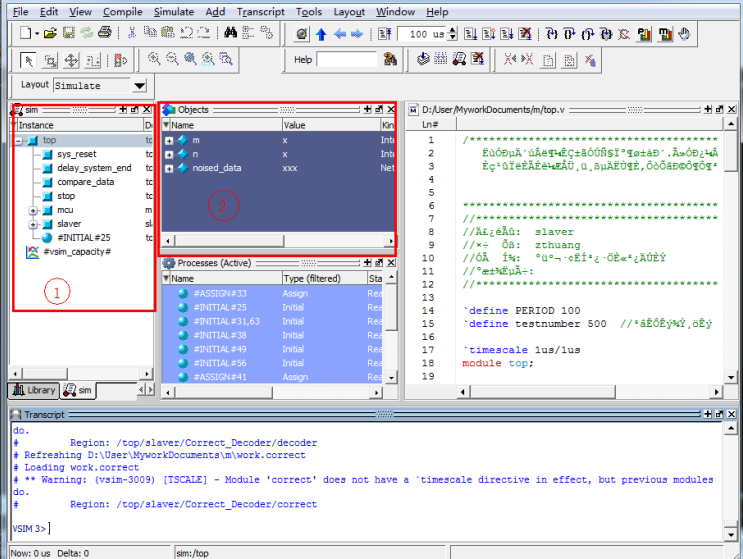
图8
在框图 1 中为整个仿真平台上的模型,可以点击模型+展开。框图 2 显示当前模型所含的项目。
1.5、添加波形,如图 9、10、11,对模块 coder 添加波形,并对波形进行分组。
图9
图10
图11
对所有仿真模型添加波形,并且分组,如图 12。
图12
图13
1.6、仿真开始在 Transcript 中输入”run -all” 等待结果。以上将生成仿真环境的全过程。下面会将对各个模块进行说明。
二、模块仿真
2.1、模块 mcu 仿真
mcu 扮演一个信源产生模块,其波形如图 14。
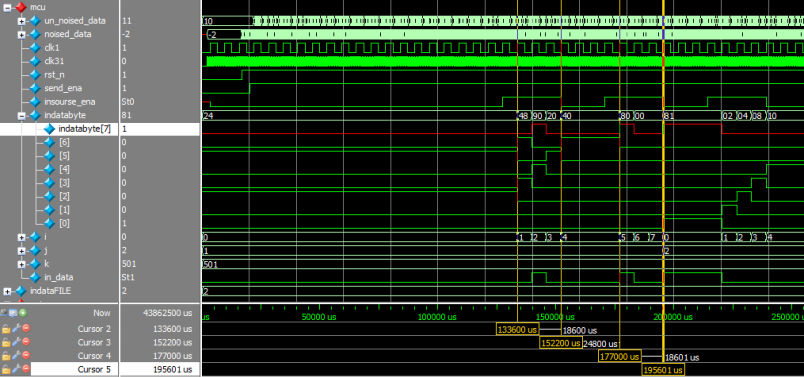
在 send_ena 使能的情况下,当 insourse_ena 为高时,数据从 indatabyte 第 7 位端口输出到 coder 模块,图中发送十六进制 24 的过程,仅在 insourse_ena 为高时发送。该模块还产生两个时钟,两个时钟分别是 31 倍的频率。clk1 和 clk31。
2.2、模块 coder 仿真
模块 coder 将对 mcu 传送的数据进行编码、扩频。仿真波形如图 15。
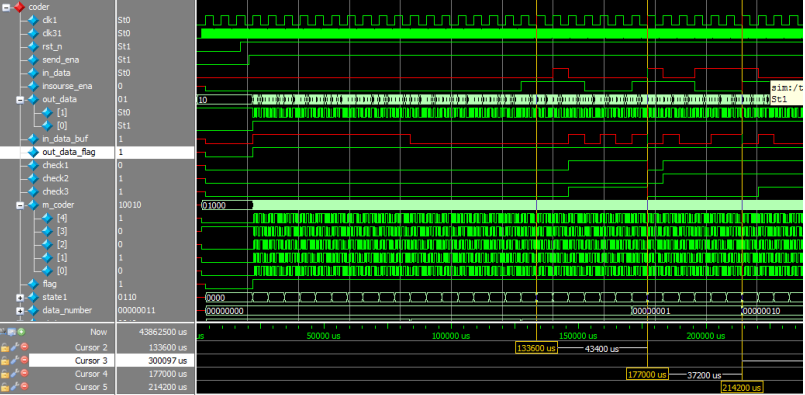
图15
图中的 in_data_buf 为发送码,当接收到 send_ena 后,先发送头和数据帧,然后才发送数据如图中从 133600us 开始发送数据”0010”(十六进制 2)后发送监督码的”101”,在 177000us 开始发送数据”0100”(十六进制 4)后发送监督码”110”。所有数据经过信道编码后,out_data 发送出去。
2.3、模块 noise 仿真
添加干扰,经 coder 发送的 2bit 数据扩展到 3bit 数据,并与噪声进行加性。
仿真波形如图 16。
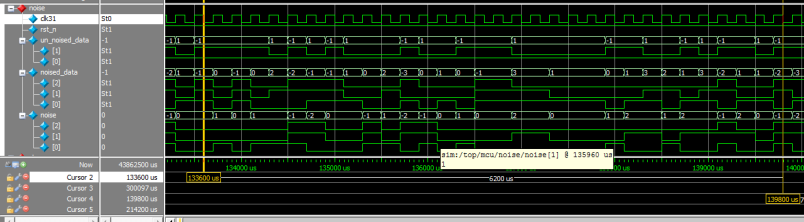
图16
图中是对 1bit 数据进行扩频后,其中 un_noised_data 为输入数据(无噪声)、经过与 noise 数据相加,得到数据 noised_data。
这模块就是充当信道中的加性干扰源。
2.4、模块 decoder 仿真
解扩是本系统的设计重点。它包含同步头的同步和数据的接收等。
本设计采用一个循环伪随机作为解扩码。采用一个 31bit 的寄存器,初始化为级数为 5 的 m 序列,首尾循环。那么,在寄存器每一位上采数,都可以得到一个伪随机序列。分别得出 31 个 m 序列。而且靠近的寄存器位,采集的 m 序列只有一位的移位。因此,可以采用该方法,在发送端发送的数据,不管为何时发送,在 31bit个寄存器中的 1 个寄存器中与之对应。更通俗的说法,不管发送设备何时开始发送。都可以在 31bit 的寄存器中找到一个寄存器采到的 m 序列与之对应。
由于在 31 比特的寄存器同时采数是比较耗费 FPGA 内部资源,所以本设计采用寄存器的每 10 个 bit 位进行一一处理。如果前 10 个没能找到对应的 m 序列,则累加到后 10 个,以此类推,在 3 次的累加中,总能完全扫描完 31bit 位的寄存器。此时可以找到对应的比特位。
由于发送设备的数据头为 10 个”1”和 1 个”0”,而在 10 个”1”中的 1 是延伸的,没法直接得到相邻”1”的交界,而在得到合适的 m 序列位后,必须进行同步,同步的方法为采集最后一个”0”作为同步。
在接收完成数据头后,进行数据帧同步。数据帧是 4bit 数据”0000”和 3bit 监督位”000”。
接收完成数据帧之后才是数据的开始。由于数据比较大,累加基数这里是 100,阀值为 30,那么,当接收到 130,说明接收到一个”1”。
仿真结果如下:
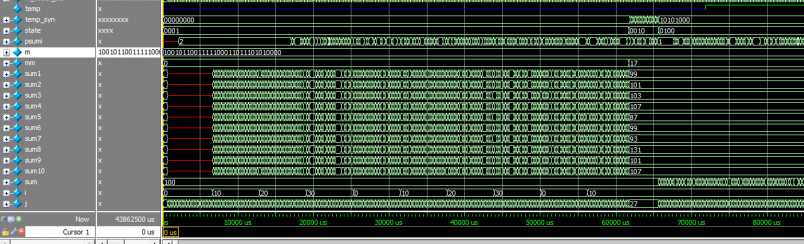
图17
图17 为接收的整体工作状态,sum1~sum10 分别采集 10 个寄存器比特位,当有1 个接收超过 130,说明寄存器该为上的 m 序列可以接收到 1 个”1”,sum 是对数据帧和数据的解扩统计。

图18
图18 是一个完整数据解扩的过程,clk31 是采集时钟,数据为 in_data_buf,从输入到输出,延迟一段时间后传送到解扩模块。psumi 为解扩的值,通过累加得到sum(in_data[2]判断。为 1,则加;为 0,则减)。如果 sum 超过 130,说明发送数据为”1”,否则为”0”。(以上为数据”1”的例子)
通过解扩的数据,送到 correct 模块进行纠错。
2.5、模块 correct 仿真
模块 correct 为纠错模块。它将解扩后的数据进行分析,即对汉明码的反运算。该模块的仿真过程省略。
2.6、模块 Slaver 仿真
Slaver 是接收模块端,它将解扩、纠错后的数据进行存储。仿真过程省略。
2.7、模块 Top 仿真
Top 模块应该放第一块讲解,因为它是一个仿真平台,它的子模块包括 mcu 和slaver。它将两个模块的发送接收进行统计、并且进行计算、输出,并对模块参数设置。以下设置发送数据比特位为 500 的输出结果(图 19、图 20):
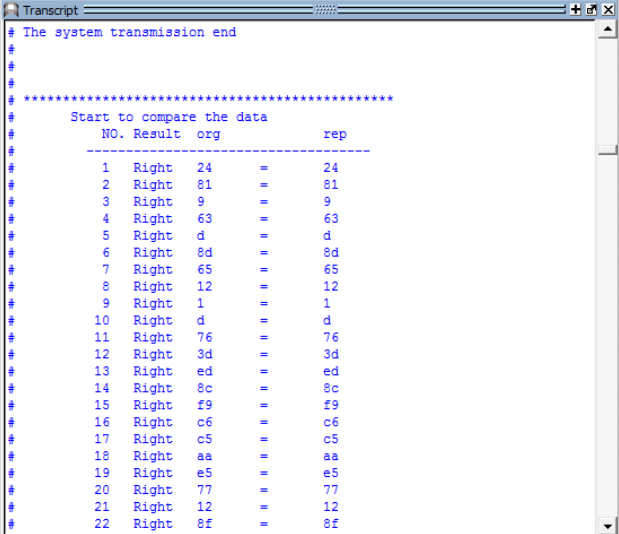
图19

以上是整个设计的仿真过程。
到此结束,直接扩频通信也到此结束,各位大侠,有缘再见!
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

