
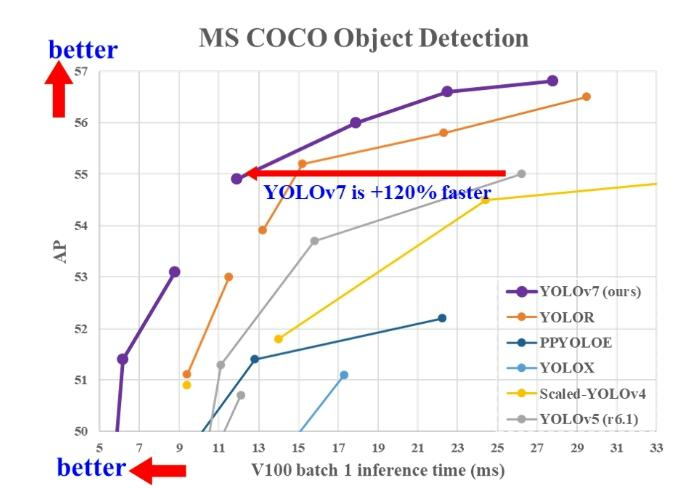
YOLO代表“You Only Look Once”,它是一种流行的实时物体检测算法系列。最初的YOLO物体检测器于2016年首次发布。从那时起,YOLO的不同版本和变体被提出,每个版本和变体都显着提高了性能和效率。YOLO算法作为one-stage目标检测算法最典型的代表,其基于深度神经网络进行对象的识别和定位,运行速度很快,可以用于实时系统。YOLOv7 是 YOLO 模型系列的下一个演进阶段,在不增加推理成本的情况下,大大提高了实时目标检测精度。
项目使用的代码在github开源,来源GitHub(https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/226-yolov7-optimization)。
01 准备模型与环境
1.1 安装OpenVINO™以及nncf包,并且clone yolov7的仓库
%pip install -q "openvino>=2023.2.0" "nncf>=2.5.0"
import sys
from pathlib import Path
sys.path.append("../utils")
from notebook_utils import download_file
# Clone YOLOv7 repo
if not Path('yolov7').exists():
!git clone https://github.com/WongKinYiu/yolov7
%cd yolov7下图为代码执行后的输出:
1.2 下载预训练模型
# Download pre-trained model weights
MODEL_LINK = "https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-tiny.pt"
DATA_DIR = Path("data/")
MODEL_DIR = Path("model/")
MODEL_DIR.mkdir(exist_ok=True)
DATA_DIR.mkdir(exist_ok=True)
download_file(MODEL_LINK, directory=MODEL_DIR, show_progress=True)下图为代码执行后的输出:
02 使用Pytorch原生推理检查模型
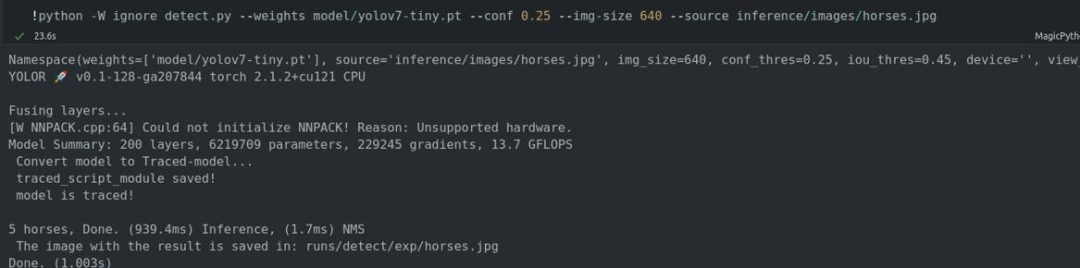
调用推理脚本`ignore detect.py`,输入模型相关信息和推理图片执行推理:
!python -W ignore detect.py --weights model/yolov7-tiny.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
下图为代码执行后的输出,执行完成后可以看到输出图像尺寸信息以及torch版本,推理设备为CPU。推理结果可以看到识别到5匹马,推理耗时、NMS耗时,结果图片保存路径等信息。
打开图片查看结果:
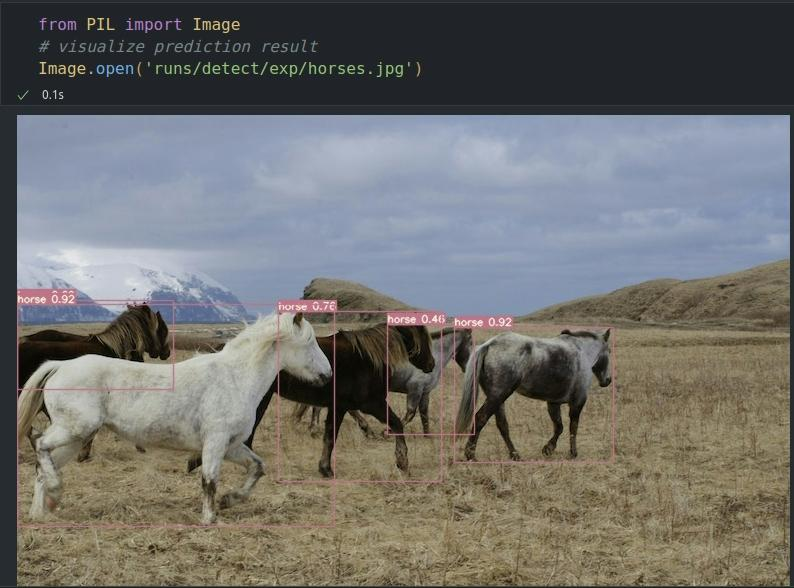
03 导出模型为onnx格式
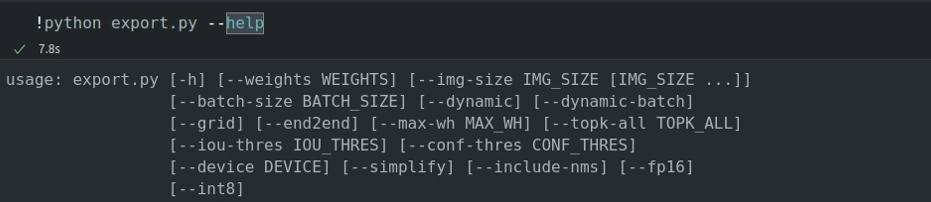
3.1 查看`export.py`脚本参数说明
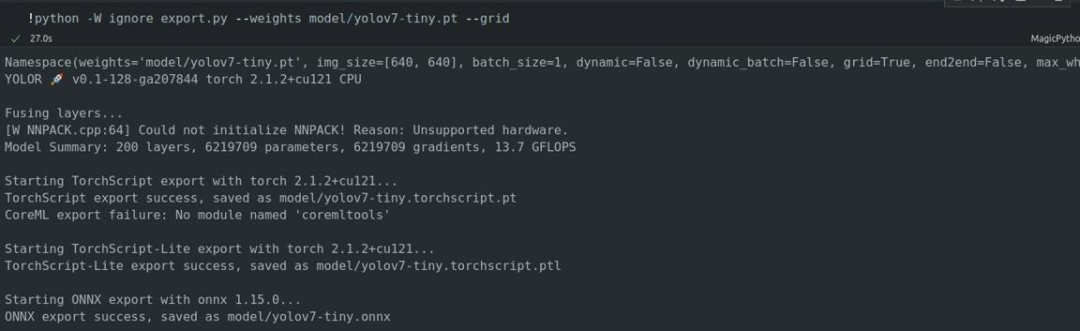
3.2 输入模型权重文件路径和要导出Detect()层网格,执行脚本生成onnx模型文件并保存
需要说明的是,将整个后处理包含到模型中有助于获得更高性能的结果,但同时会降低模型的灵活性,并且不能保证完全准确,这就是为什么我们只添加 --grid 参数来保留原始 pytorch 模型结果格式的原因。
04 转换onnx格式为OpenVINO™支持的IR文件
虽然 OpenVINO™ Runtime直接支持 ONNX 模型,但将它们转换为 IR 格式可以利用 OpenVINO™ 模型转换的一些API特性。调用模型转换的python API 的 `ov.convert_model`可以转换模型。该API返回 OpenVINO™ 模型类的实例,该实例可在 Python 接口中使用。我们可以使用 `ov.save_model` API 接口以 OpenVINO™ IR 格式保存在设备上,以备使用。
import openvino as ov
model = ov.convert_model('model/yolov7-tiny.onnx')
# serialize model for saving IR
ov.save_model(model, 'model/yolov7-tiny.xml')05 验证模型推理
`detect.py` 推理脚本包括预处理步骤、OpenVINO™模型的推理以及结果后处理以获得边界框等功能。
模型需要RGB通道格式的图像,并在 [0, 1] 范围内归一化。要调整图像大小以适合模型大小,请使用`letterbox`方法调整,其中保留了宽度和高度的纵横比。为了保持特定的形状,预处理会自动启用填充。
5.1 预处理阶段
对图像进行预处理,以 `np.array` 格式获取图像,使用`letterbox`方法将其调整为特定大小,将色彩空间从 BGR(OpenCV 中的默认值)转换为 RGB,并将数据布局从 HWC 更改为 CHW:
def preprocess_image(img0: np.ndarray): # resize img = letterbox(img0, auto=False)[0] # Convert img = img.transpose(2, 0, 1) img = np.ascontiguousarray(img) return img, img0
将预处理后的图像转换为张量格式。以 np.array 格式获取图像,其中 unit8 数据在 [0, 255] 范围内,并将其转换为浮点数据在 [0, 1] 范围内的 torch.Tensor 对象。
def prepare_input_tensor(image: np.ndarray): input_tensor = image.astype(np.float32) # uint8 to fp16/32 input_tensor /= 255.0 # 0 - 255 to 0.0 - 1.0 if input_tensor.ndim == 3: input_tensor = np.expand_dims(input_tensor, 0)
5.2 后处理阶段
模型检测功能核心代码的介绍,使用 NMS 读取图像、对其进行预处理、运行模型推理和后处理结果。
参数:
model(Model):OpenVINO™编译的模型。
image_path (Path):输入图片路径。
conf_thres(浮点数,*可选*,0.25):对象过滤的最小置信度
iou_thres(float,*可选*,0.45):在 NMS 中重新复制对象的最小重叠分数
classes (List[int], *optional*, None):用于预测过滤的标签,如果未提供,则将使用所有预测标签
agnostic_nms (bool, *optiona*, False):是否应用与类无关的 NMS 方法
返回:
pred (List):具有 (n,6) 形状的检测列表,其中 n - 格式为 [x1, y1, x2, y2, score, label] 的检测框数
orig_img (np.ndarray):预处理前的图像,可用于结果可视化
input_shape (Tuple[int]):模型输入tensor的形状,可用于输出分辨率
def detect(model: ov.Model, image_path: Path, conf_thres: float = 0.25, iou_thres: float = 0.45, classes: List[int] = None, agnostic_nms: bool = False): output_blob = model.output(0) img = np.array(Image.open(image_path)) preprocessed_img, orig_img = preprocess_image(img) input_tensor = prepare_input_tensor(preprocessed_img) predictions = torch.from_numpy(model(input_tensor)[output_blob]) pred = non_max_suppression(predictions, conf_thres, iou_thres, classes=classes, agnostic=agnostic_nms) return pred, orig_img, input_tensor.shape
图像上绘制预测边界框的核心代码实现,
参数:
predictions (np.ndarray):形状为 (n,6) 的检测列表,其中 n - 检测到的框数,格式为 [x1, y1, x2, y2, score, label]
image (np.ndarray):用于框可视化的图像
names (List[str]): 数据集中每个类的名称列表
colors (Dict[str, int]): 类名和绘图颜色之间的映射
返回:
image (np.ndarray):框可视化结果
def draw_boxes(predictions: np.ndarray, input_shape: Tuple[int], image: np.ndarray, names: List[str], colors: Dict[str, int]):
if not len(predictions):
return image
# Rescale boxes from input size to original image size
predictions[:, :4] = scale_coords(input_shape[2:], predictions[:, :4], image.shape).round()
# Write results
for *xyxy, conf, cls in reversed(predictions):
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, image, label=label, color=colors[names[int(cls)]], line_thickness=1)06 选择设备并推理
compiled_model = core.compile_model(model, device.value) boxes, image, input_shape = detect(compiled_model, 'inference/images/horses.jpg') image_with_boxes = draw_boxes(boxes[0], input_shape, image, NAMES, COLORS) # visualize results Image.fromarray(image_with_boxes)
单图片推理的可视化结果如下图所示:

07 验证模型准确性
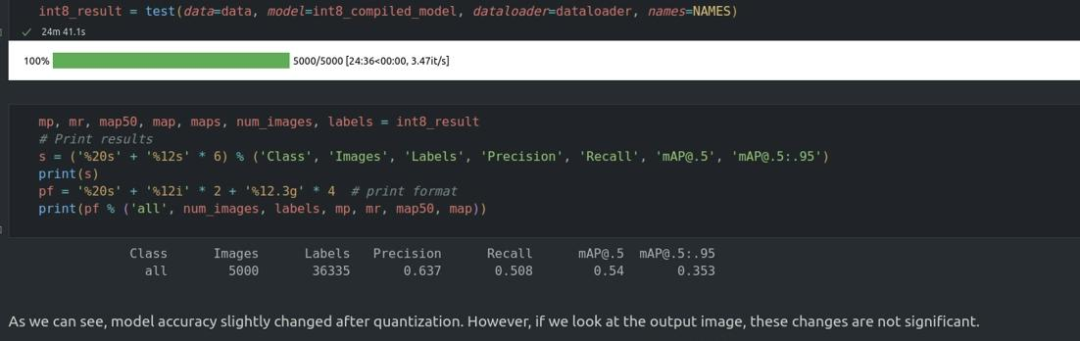
为了评估模型的准确性,需要下载coco数据集以及注释。处理验证数据集并完成评估。评估完成后,下图可以看到准确度是符合要求的:
08 使用 NNCF 训练后量化 API 优化模型
NNCF 是 OpenVINO™ 中的神经网络推理优化提供了一套高级算法,精度下降最小。我们将在训练后模式下使用 8-bit量化来优化 YOLOv7。优化过程包含以下步骤:1)创建用于量化的数据集。2)运行 nncf.quantize 以获取优化的模型。3)使用 openvino.runtime.serialize 函数序列化 OpenVINO™ IR 模型。
量化变换函数,从数据加载器项中提取和预处理输入数据以进行量化。量化完成后可以验证量化模型推理和验证量化模型的准确性,看是否符合要求。
import nncf def transform_fn(data_item): img = data_item[0].numpy() input_tensor = prepare_input_tensor(img) return input_tensor quantization_dataset = nncf.Dataset(dataloader, transform_fn)
nncf.quantize 函数提供模型量化的接口。它需要OpenVINO™模型和量化数据集的实例。
quantized_model = nncf.quantize(model, quantization_dataset, preset=nncf.QuantizationPreset.MIXED) ov.save_model(quantized_model, 'model/yolov7-tiny_int8.xml')
09 比较原始模型和量化后模型的性能
量化完成后,我们希望使用 OpenVINO™ 基准测试工具测量 FP32 和 INT8 模型的推理性能,从而清楚NNCF带来的优化提升。
下图为在AI爱克斯开发板上FP32格式的模型推理,cpu型号为n5105,可以看到吞吐为2.27fps。

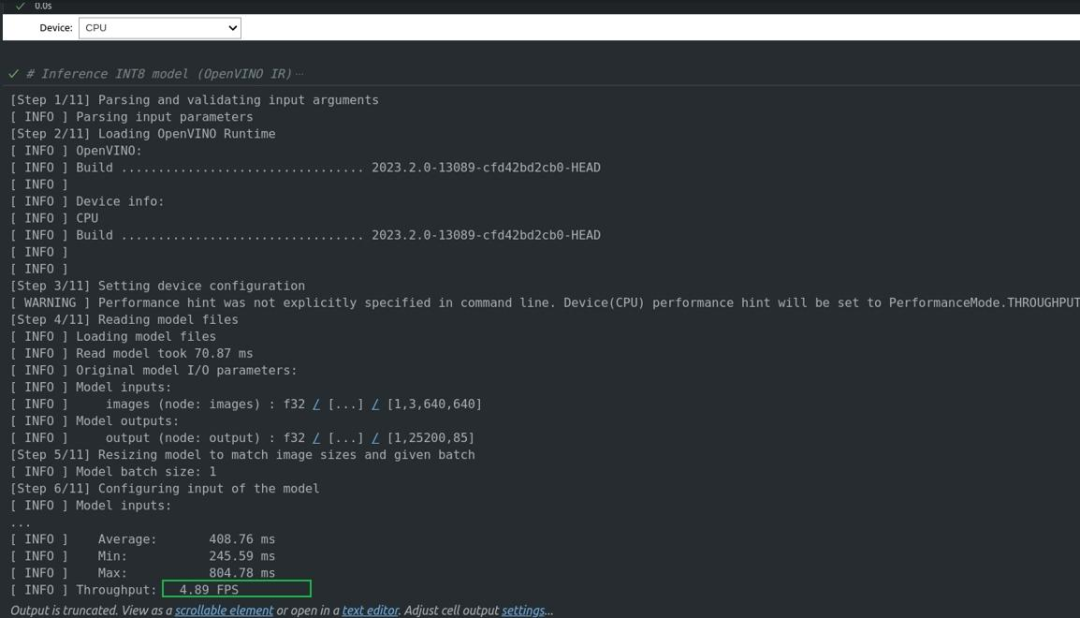
下图为量化后 INT8 格式的模型推理,可以看到吞吐为4.89fps。
总 结
FP32格式的模型推理AI爱克斯开发板上CPU吞吐为2.27fps,量化后 INT8 格式为4.89fps,由此说明了量化的后性能提升很明显,提升至2.15倍,在工程和学习中推荐使用NNCF等OpenVINO™工具来优化模型,从而在不损失精度的前提下提高推理性能,更好的服务于场景使用。
作者:康瑶明 英特尔边缘计算创新大使
 我要赚赏金
我要赚赏金 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂

